






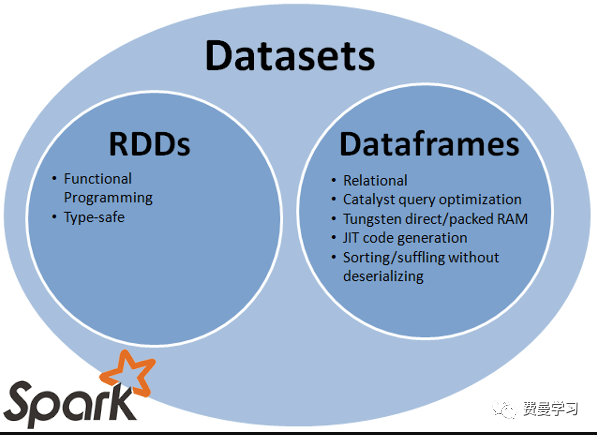
当我们使用scala进行Spark开发时,经常会用到将RDD转换为DataFrame和Dataset类型。相对于RDD,DataFrame和Dataset具有很多优势,比如说DataFram增加了Schema信息,类似于关系数据库中表,而且对于这种数据结构的操作性能方面也有提升。
创建 RDD
首先使用sparkContext.parallelize() 函数将Seq对象生成RDD。
import spark.implicits._val columns = Seq("language","users_count")val data = Seq(("Java", "20000"), ("Python", "100000"), ("Scala", "3000"))val rdd = spark.sparkContext.parallelize(data)转换 RDD 成 DataFrame
将RDD转换成DataFrames有三种方法:toDF, createDataFrame,RDD[Row]类型转换。
使用rdd.toDF()函数z转化
Spark对象提供隐式函数toDF() 用来将RDD, Seq[T], List[T] 转换成DataFrame。为了使用函数toDF() 需要首先隐式导入import spark.implicits._。
val dfFromRDD1 = rdd.toDF()dfFromRDD1.printSchema() toDF()函数生成的DataFrame默认的列名形式为_1,_2。
root |-- _1: string (nullable = true) |-- _2: string (nullable = true)toDF()也提供使用字符串的形式定义列名。
val dfFromRDD1 = rdd.toDF("language","users_count")dfFromRDD1.printSchema()输出的schema信息如下。
root |-- language: string (nullable = true) |-- users_count: string (nullable = true)默认情况生成的DataFrame中列数据类型是推断出的,可以为null值。也可以使用StructType来定义列值的类型和是否为空。
使用spark createDataFrame() 函数
SparkSession 类提供以rdd为参数的createDataFrame()函数,利用函数``toDF() 定义列信息。
val columns = Seq("language","users_count")val dfFromRDD2 = spark.createDataFrame(rdd).toDF(columns:_*) 上面使用scala操作符 **:_\*** 将多Seq对象展开为用逗号的分开的字符串。
使用RDD[Row]转化为DataFrame
Spark createDataFrame() 可以接受RDD[Row]和schema参数生成DataFrame,首先将RDD[T]转换为RDD[Row]类型,使用StructType定义schema信息。StructType定义需要一个数组类型的StructField。
//From RDD (USING createDataFrame and Adding schema using StructType) val schema = StructType(columns .map(fieldName => StructField(fieldName, StringType, nullable = true))) //convert RDD[T] to RDD[Row] val rowRDD = rdd.map(attributes => Row(attributes._1, attributes._2)) val dfFromRDD3 = spark.createDataFrame(rowRDD,schema)RDD转换为Dataset
DataFrame API和RDD API 有很大的区别,前者可以通过Spark Catalyst优化器创建执行计划,优化计算性能。
Dataset API设计的目标是为了一方面满足面向对象风格的开发,另一方面为保证RDD API编译类型安全使用Catalyst 进行优化。同时具有类似DataFrame对象具有的堆外存储机制。和DataFrame相比,DataFrame是Dataset的一种特例即Dataset[Row]。关于对象序列化,Data API具有效率很高的序列化和反序列化机制。
val ds = spark.createDataset(rdd)结论
本文介绍了如何将RDD转化为DataFrame和Dataset类型,在工作中会经常使用。这种转化还有优化计算性能的好处。















 4396
4396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









