










做spider-node的初衷
1: 当前应用系统研发过程存在的问题
1.1: 架构设计与技术管理缺失导致的痛点
- 1:缺乏顶层架构规划导致模块耦合度过高,代码如"面条"般纠缠,修改一处功能可能引发连锁错误(如牵一发动全身).
- 2: 应用系统中,各个服务各种交互来完成一个业务能力,导致各个服务之间相互依赖,业务逻辑复杂,维护困难,很难看到业务形态的全不面貌。
- 3:需求与实现脱节的恶性循环
- 4:需求变更频繁且缺乏技术可行性评估,研发被迫仓促响应,导致代码结构混乱;
- 5:未建立需求-架构-代码的映射关系,技术方案文档缺失,新成员需通过逆向工程理解系统
- 6: 应用系统的核心资产缺失,比如业务能力的业务流程,数据流程,系统的底层能力都缺失。
- 7: 代码复杂、模型文档更新不及时,致使新同学和非技术同学不能短时间内了解业务现状。技术和非技术间对同一业务理解存在分歧而不自知。甚至业务Owner也不能很流畅的描述出自己所负责的业务,产品对研发实现的流程一无所知,再进行产品设计的时候,无法考虑到研发的代码流程
- 8: 项目中涉及到许多领域对象,对象间不仅存在复杂的前后依赖关系还相互掺杂没有明显边界,代码多次迭代后更是混乱不堪难以维护,迭代风险高,很难兼容全部的业务场景,当业务流程繁杂,存在需要延迟,轮询,异步等组合使用的情况下。该功能的全景,几乎很难被后者挖掘,以及迭代。 存在于线上环境的偶现问题更是难以排查。需要一种可以通过简单操作就能将重要节点数据都保存下来的能力,此能力堪比对链路精细化梳理后的系统性日志打印
- 9: 维护平台型产品,为众多上游业务线提供着基础服务,但在短时间内应对各个业务方的定制化需求捉襟见肘,更不知如何做好平台与业务、业务与业务之间的隔离,更不知道系统之间交互,如何做到解耦
1.2: 架构层面的痛点
- 1: 高运维成本:微服务数量激增后,服务发现、配置管理、监控报警等复杂度呈指数级上升。
- 2: 分布式事务难题:跨服务的数据一致性需要复杂的补偿机制(如Saga模式),增加了开发和维护成本。
- 3: 性能开销:服务间通过网络通信(如HTTP/REST或gRPC)会产生序列化、网络延迟等额外开销,尤其在高频交互场景下问题更突出。
- 4: 版本与依赖管理:服务间的依赖关系复杂,版本升级可能导致连锁反应,甚至引发“分布式僵化”
1.3: 研发与产品之间缺乏沟通桥梁去统一语言
- 1: 研发与产品之间缺乏沟通桥梁去统一语言,导致产品无法理解研发的代码逻辑。
- 2:研发很多层面也无法很有效的理解产品需求,导致研发无法快速响应产品需求。
1.4: ai当前应用在编码阶段遇到的问题
- 1: ai很难通过你的项目来理解的业务,从而完成代码的编写
- 2:你无法判断ai是否理解的你需求,从而梳理出可行的编码方案
- 3: 当前ai编码大多还是在idea中充当编码助手,这个编码助手,现在通病都是,他无法通过一个需求,正确的去整理到,需要修改,或者需求理解的代码文件。
1.4: 通过以上的痛点问题基础上,衍生了做spider-node-ai的想法。
spider-node当前存在开源可用的版本
spider-node 1.0.2版本 不支持ai
这个版本可以看 http://www.spider-node.cn/
spider-node 2.0版本 支持ai
概述
-
1: spider-node 2.0版本,想要推动web层面研发思想改革。想要完成DDD,中台,没有完成的事业。
-
2: 想要让研发在应用系统迭代的过程中,只需要完成技术方案的实现,那么他的工作就完成了百分之80,剩下的编码,调试,交给spider-node 2.0版本ai。
-
3: 技术方案包含,业务流程的设计,数据流程的设计,明确基础功能的能力范围
-
3.1: 数据流程的设计
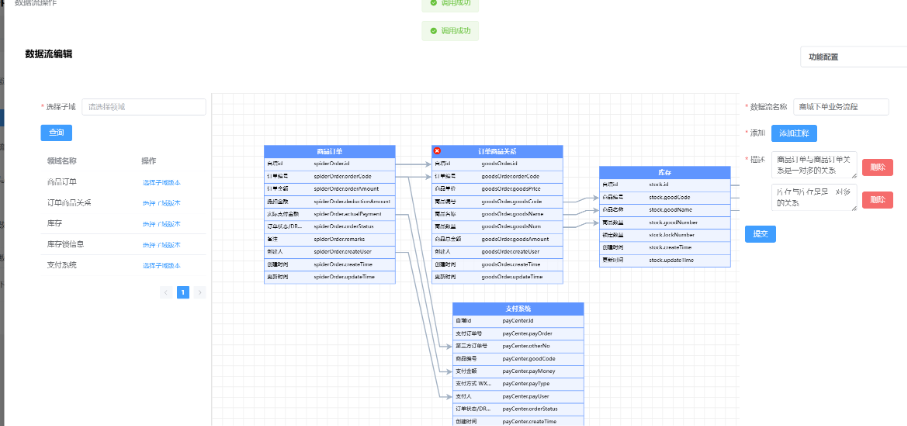
-
3.2: 基础能力的迭代 交给ai编码 输入简单的需求,ai生成详细需求
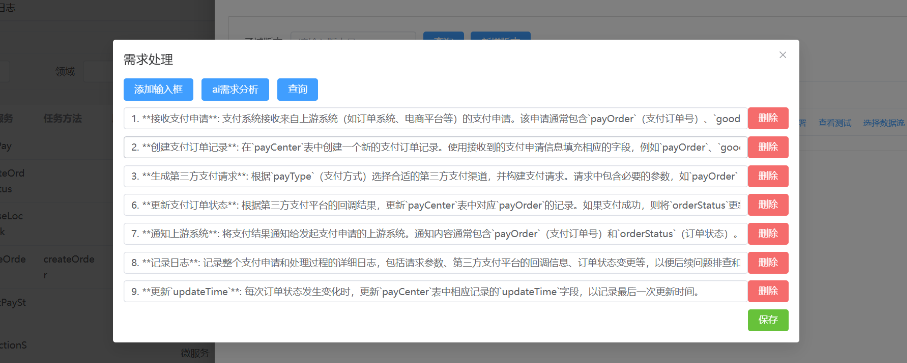
-
3.2.1: 这儿只需要输入这个需求的简述,让ai生成详细的细节,可以判断这些细节,那些可以不要,也可以自行补充
-
3.3: 查看ai完成后的代码结果
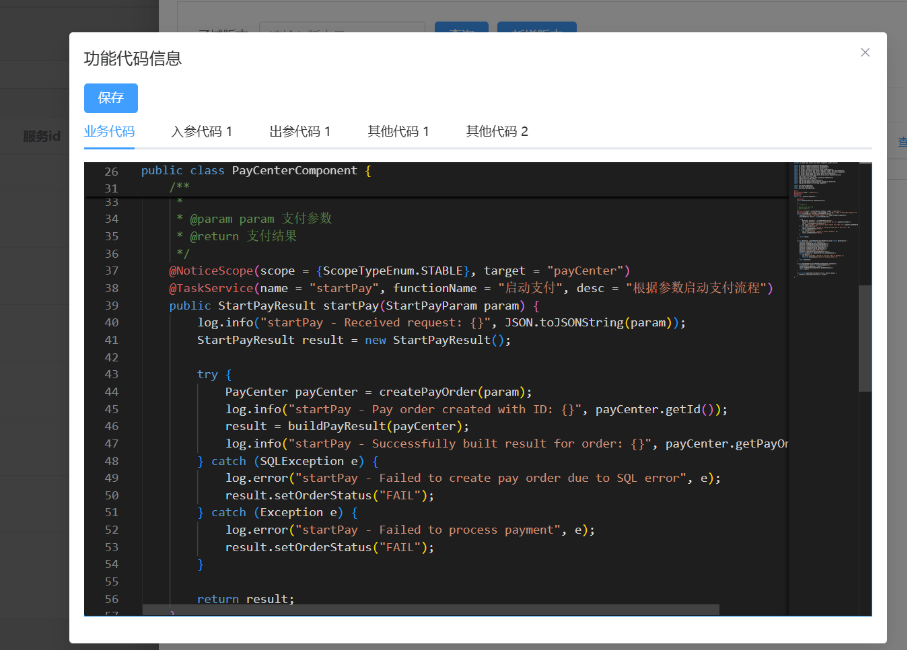
-
3.4: 查看部署情况
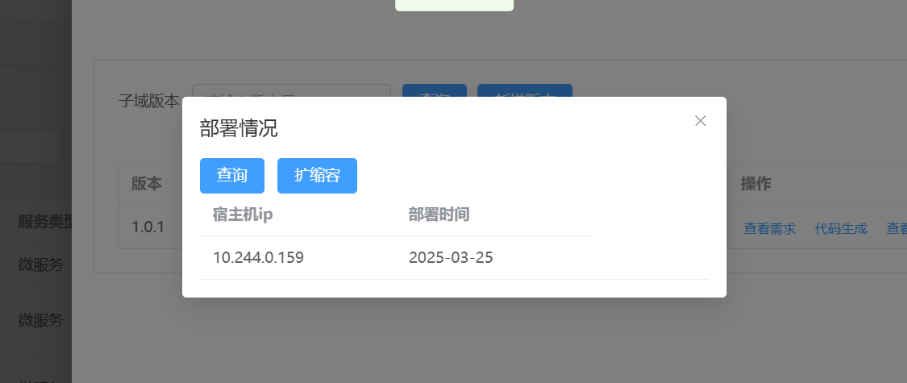
-
4: 业务流程设计
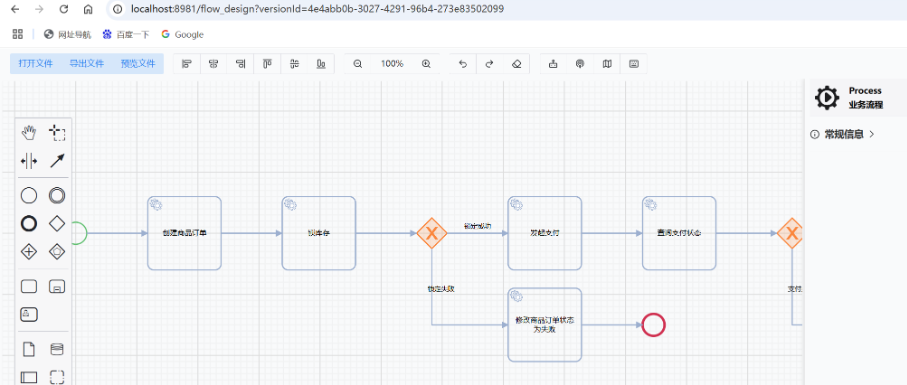
-
4.1: 业务流程中参数扭转(ai完成)
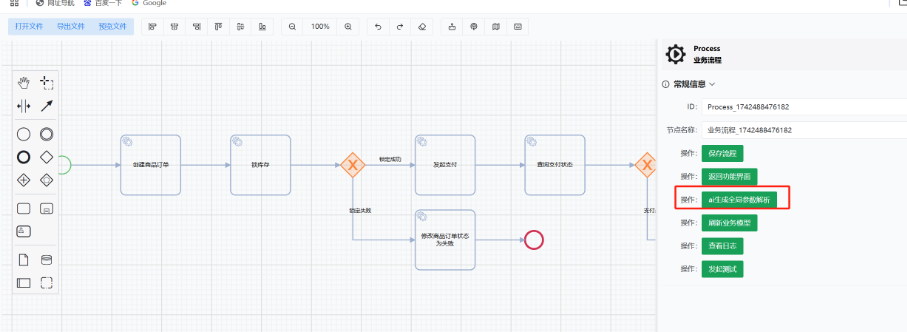
-
5: 测试
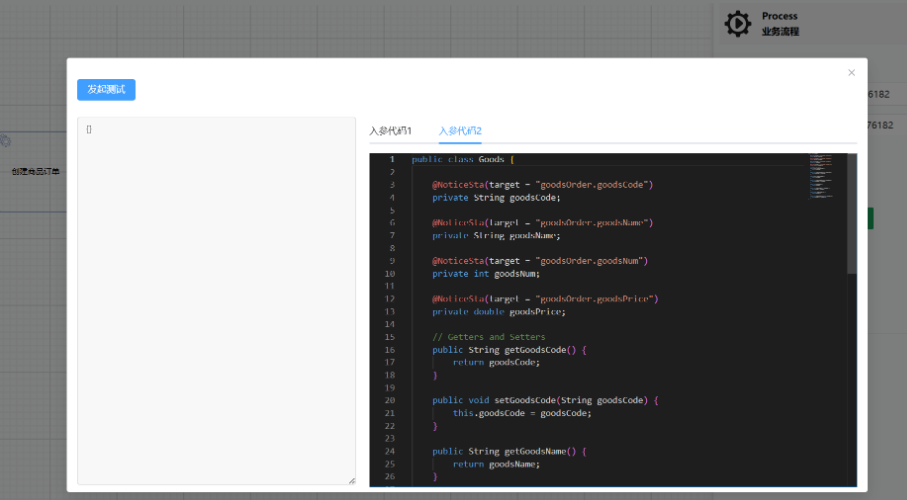
-
5.1: 查看执行细节

在这里插入图片描述
- 6: 分布式事务配置
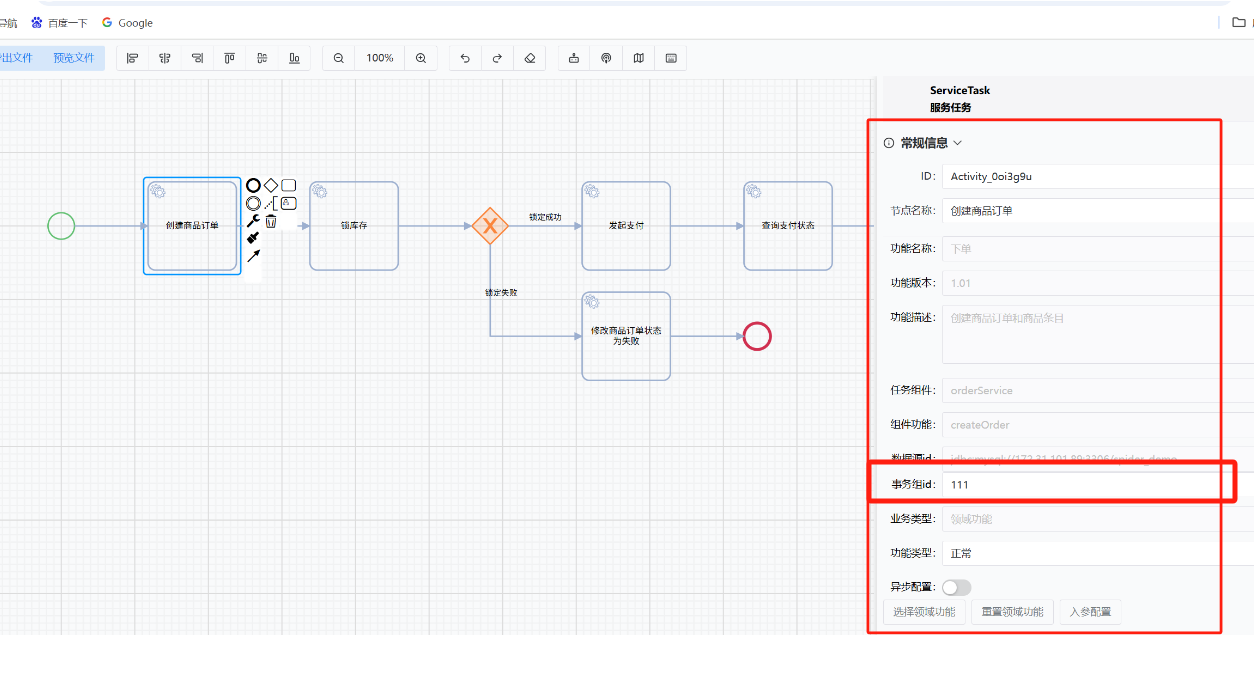
- 6.1: 事务讲解,只要在业务流程中的节点事务组输入框,输入相同的字符串,代码这些节点在一个事务组,这些节点同时成功,同时失败
- 7 业务模型的基础能力
- 包含网关,判断网关,延迟节点,轮询节点,节点异步

















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









