





本文提出了一种名为MotionLM的模型,用于多智能体的运动预测。该模型将轨迹生成和交互建模结合在一个解码过程中,通过受自回归语言模型启发的训练目标来生成联合轨迹。该模型通过采样离散的运动标记,并关注其他智能体的行为,生成联合轨迹。文档描述了MotionLM的架构,包括场景编码器和轨迹解码器,并解释了模型的分解和训练目标。作者还提供了在Waymo Open Motion数据集上进行的实验结果,证明了MotionLM在预测联合智能体轨迹方面的性能改进。总体而言,本文将MotionLM描述为一种有效的多智能体运动预测模型,能够捕捉驾驶场景的多模态性和时序依赖性。
论文标题:MotionLM: Multi-Agent Motion Forecasting as Language Modeling
可靠地预测道路各参与者的未来行为对于自动驾驶车辆的安全规划至关重要。本文中,我们将连续的轨迹表示为由离散运动标记构成的序列,并将多智能体运动预测建模为一个语言建模任务。我们的模型MotionLM具有以下几个优点:首先,它不需要锚点或显式的潜在变量优化来学习多模态分布。相反,我们采用了一个简单的语言建模目标,最大化序列标记的平均对数概率。第二,我们的方法不需要后处理的交互启发式,它们先生成各个智能体的轨迹,再进行交互评分。
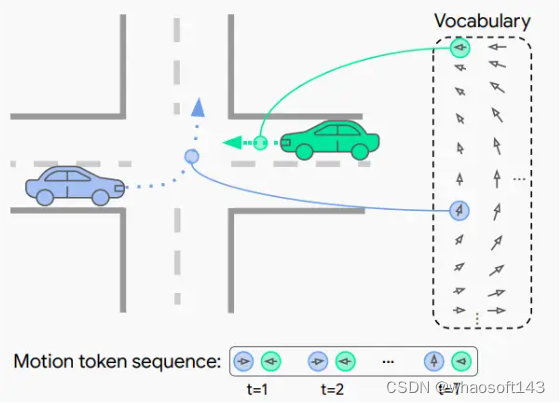
▲图1|模型能够为一组智能体自动回归地生成离散运动标记序列,从而产生一致的交互轨迹预测。
相反,MotionLM通过自回归解码过程直接生成交互智能体的联合分布。此外,模型的顺序分解使得条件化的时间顺序列出成为可能。我们在Waymo开放运动数据集上进行了实验,结果表明我们的方法在多智能体运动预测方面达到了新的最先进水平,并在交互预测挑战排行榜上获得了第一名。
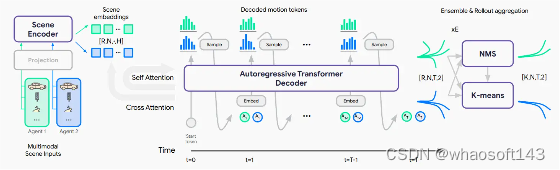
图2|MotionLM的体系结构。我们首先对每个建模智能体的参考框架编码异构场景特征(左),得到形状为R、N、、H的场景嵌入。其中R表示轨迹数,N表示(联合建模的)智能体数,H表示每个嵌入的维度。我们在批量维度上重复嵌入R次,以便在推理期间进行并行采样。接下来,一个轨迹解码器以时间因果的方式为多个智能体自动回归地生成运动标记序列(中)。最后,我们可以通过使用非最大抑制初始化的k均值聚类来恢复轨迹的代表模式(右)。
方法详解

2.1 联合概率轨迹

我们将未来联合动作序列的分布分解为条件概率的乘积:
等式(2)表示我们在时间t将智能体动作视为在先前动作和场景上下文的条件下独立的。这与真实世界驾驶在短时间间隔内的经验一致;例如,非受损人类司机通常需要至少500毫秒才能在前车制动时释放加速器。在我们的实验中,我们发现2Hz的反应足以超过最先进的联合预测模型。
我们注意到,我们模型的分解完全不包含潜在变量;多模态预测纯粹来自每个滚动时间步的分类标记采样。
训练目标。MotionLM被表述为一个生成模型,训练去匹配观察到的智能体行为的联合分布。具体来说,我们遵循多智能体动作序列的最大似然目标:
与现代语言模型的典型训练方式类似,我们采用了‘教师强制’(teacher forcing)的方法,其中在每个时间步提供先前的真实(非预测)标记,这有助于提高稳定性并避免训练过程中的采样误差。我们注意到,这对于所有目标代理(agent)都是适用的;在训练中,每个目标代理都可以看到所有目标代理在当前时间步之前发生的真实动作序列。这自然允许利用基于注意力(attention)的现代体系结构(如Transformer[48])来实现时间上的并行化。
我们的模型也存在与一般模仿学习框架相同的理论限制。但这并不妨碍我们实现强大的预测性能。
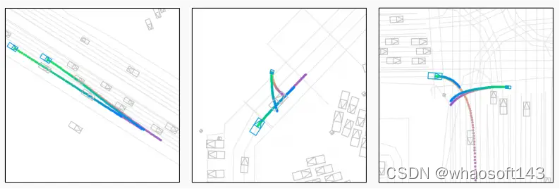
▲图3|WOMD场景中预测的前两个联合轨迹模式。颜色渐变表示从t=0s到t=8s的时间推移,最可能的联合模式从绿色转为蓝色,次要的联合模式从橙色转为紫色。观察到三种类型的交互:相邻车道中的智能体根据变道智能体变道时机让路(左)、行人根据车辆的进展绕过经过的车辆(中)、转弯车辆要么让路给过街自行车手(最可能的模式),要么在自行车手接近之前转弯(次要模式、右)。
■2.2 模型实现
我们的模型由两个主要网络组成,一个编码器处理初始场景元素,后面是一个轨迹解码器,它执行对场景编码的交叉注意力以及沿着智能体运动标记的自注意力,遵循Transformer体系结构。
1)场景编码器:
场景编码器的任务是处理来自几个输入模态的信息,包括道路图、交通灯状态和周围智能体的轨迹历史。在这里,我们遵循了早期融合网络的设计作为我们模型的场景编码骨干。特别选择早期融合是因为其灵活地处理所有模态的能力,而具有最小的归纳偏见。
上述特征都是相对于每个建模智能体的参考框架提取的。输入张量然后馈送到一堆自注意力层,在所有过去时间步和智能体间交换信息。在第一层中,潜在查询交叉参与原始输入,以将正在处理的向量集合减少到可管理的数量。
2)联合轨迹解码器:
我们的轨迹解码器的任务是为多个智能体生成运动标记序列。

我们用“Verlet”步骤包装Δ动作,其中零动作表示应使用与前一步相同的Δ索引。由于智能体速度在连续时间步之间往往平滑变化,这有助于减少总词汇量,简化了训练动力学。最后,为了在顺序预测中有所保留,我们将每个坐标的动作折叠到它们的笛卡尔积的单个整数索引中。在实践中,对于这里呈现的模型,我们使用每个坐标13个标记,总共有13^2=169个离散运动标记可用(参见附录A了解更多细节)。
我们为每个离散运动标记计算一个学习的值嵌入和两个学习的位置嵌入(表示时间步和智能体标识),它们通过元素 Wise 求和组合以输入到Transformer解码器中。

为方便了解基于智能体的特征编码的交叉注意力,我们为每个建模智能体表示扁平化标记序列一次。每个建模智能体都被视为一次“自我”智能体,并对该智能体的场景特征执行交叉注意力。将自我智能体折叠到批处理维度允许训练和推理期间的并行化。
■2.3 强制时间因果性
我们的自动回归分解自然尊重联合轨迹期间的时间依赖性;对任一特定智能体的运动标记采样仅受过去标记(来自任何智能体)的影响,不受未来标记的影响。在训练时,我们需要一个掩码来确保自注意力操作只根据这些依赖关系更新每个步骤处的表示。此注意力掩码呈阶梯形块状模式,使所有智能体只暴露每个其他智能体直到上一步的历史。

图4|联合轨迹的因果贝叶斯网络表示(左)、干预后因果贝叶斯网络(中)和非因果条件化(右)。实线表示时间因果依赖性,虚线表示非因果信息流动。
时间因果条件。如前所述,这种分解的一个特定好处是querying时间因果条件轨迹的能力(图4)。在这种设置下,我们固定一个查询智能体采取某些动作序列,并仅展开其他智能体。
我们可以将这视为在没有混杂者的情况下计算因果干预的近似;一般来说,仅通过观察数据无法学习干预(由于可能存在未观察到的混杂者),但我们模型的分解至少消除了违反时间因果导致的某些伪相关。

2.4 轨迹聚合
像WOMD这样的联合运动预测基准任务需要以少量“模式”的形式紧凑表示未来联合分布。每个模式被赋予一个概率,并可能对应于一个特定的同胚结果(例如通过/产量)或速度/几何的更细微差异。
在这里,我们聚合轨迹以实现两个主要目标:
1)发现分布的基本模式
2)估计每个模式的概率。
具体来说,我们采用非最大抑制(NMS)聚合方案,但通过确保所有智能体预测都在对应簇内保持在给定距离阈值范围内,将其扩展到联合设置。另外,我们利用模型集成来考虑表面不确定性,进一步改善预测质量,在聚合步骤之前合并独立训练的副本的轨迹。
实验
实验结果的分析显示,MotionLM模型在预测多个交互代理的联合轨迹方面表现出卓越的性能。模型通过采样离散的运动令牌并关注其他代理的动作,将轨迹生成和交互建模结合在一个解码过程中。实验结果表明,MotionLM在预测联合代理轨迹方面的性能得到了显著的提高。与其他现有方法相比,MotionLM能够捕捉驾驶场景的多模态性和时间依赖关系。通过比较模型在不同情境下的表现,可以发现模型在边缘预测和联合预测方面都取得了优异的结果。边缘预测的模型版本相对于联合预测的版本,在预测重叠度方面获得了相对较高的性能。然而,联合预测的模型能够更好地捕捉代理之间的交互情况,使其能够更准确地适应其他代理的动作。在模型规模和推断延迟的分析中,我们可以看到不同模型大小和滚动次数的性能差异。
总体而言,MotionLM模型在多代理运动预测方面的实验结果显示出其卓越性能和潜力,并提出了未来工作的发展方向。
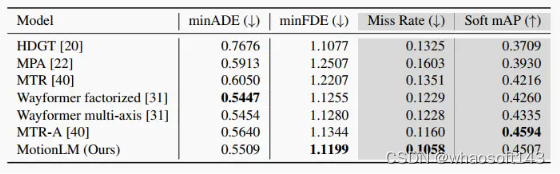
▲表1|在WOMD测试集上的边缘预测性能。我们展示了跨时间步(3、5和8秒)以及智能体类型(车辆、行人和自行车手)的平均指标。灰色列表示该挑战的官方排名指标。
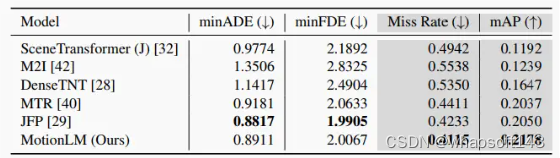
▲表2|在WOMD交互测试集上的联合预测性能。我们展示了跨时间步(3、5和8秒)以及智能体类型(车辆、行人和自行车手)的场景级联合指标。灰色列表示该挑战的官方排名指标。
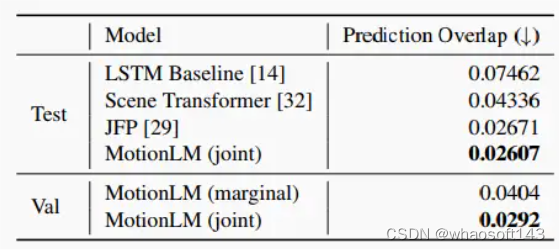
▲表3|不同模型配置的预测重叠率。展示了各种模型在WOMD交互测试和验证集上的自定义预测重叠指标。

▲表4|条件预测性能。展示了在三种预测设置下模型在WOMD交互验证集上的边缘(单智能体)指标:边缘、时间因果条件和非因果条件。
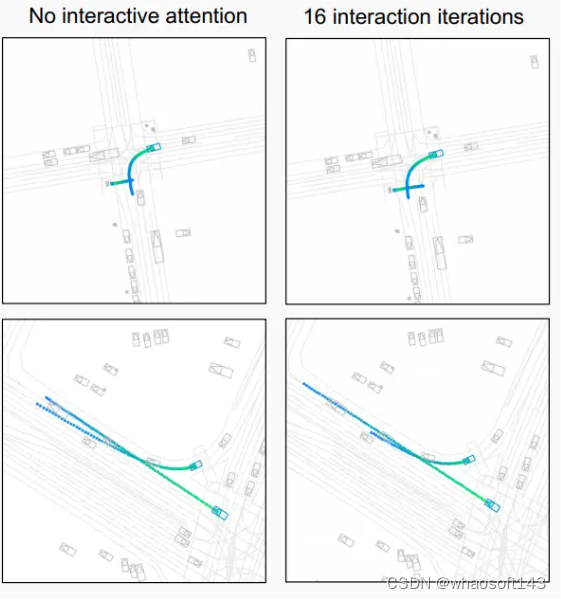
▲图5|在研究的交互注意力频率两极端,显示了场景中预测的顶部联合轨迹模式。在没有交互注意力的情况下(左),两个建模智能体仅在8秒轨迹开始时相互参与一次,之后再也不会,这与2 Hz注意力下的16次完全相反(右)。零交互注意力导致独立轨迹可能导致场景不一致的重叠。例如,转弯车辆未考虑过街行人(左上),或者未适当让路过街车辆(左下)。
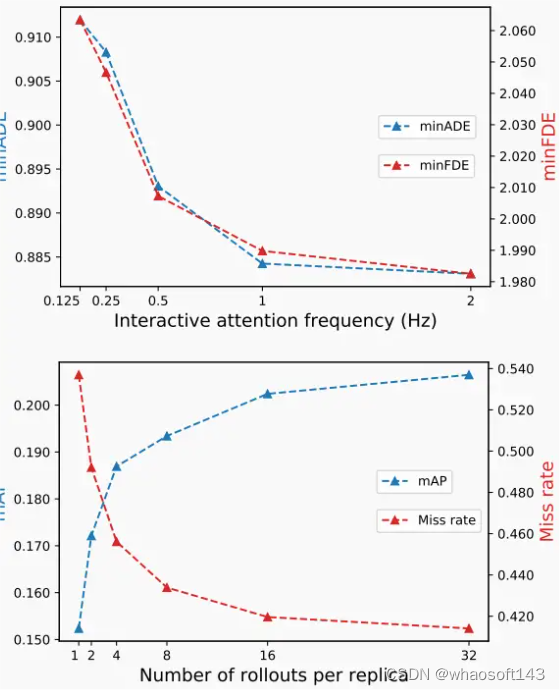
▲图6|在WOMD交互验证集上,跨不同的交互注意力频率(顶部)和每个副本的轨迹数(底部),显示了联合预测性能。垂直轴显示8个副本集成的场景级联合指标。参见附录表5和6以获取完整的参数范围和指标。
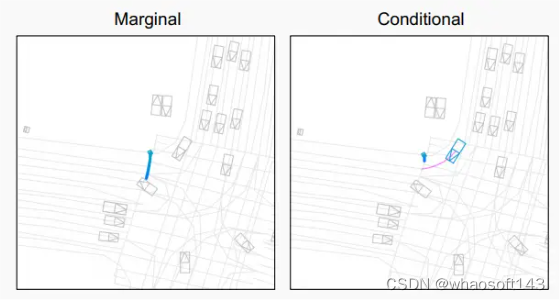
▲图7|在边缘设置(左)和时间因果条件设置(右下),可视化行人在最可能的未来预测。当独立考虑行人时,模型对穿过道路的轨迹分配了最大概率。当考虑车辆的真实转弯轨迹(品红色)时,行人被预测停下来让路。
展望
这篇文章主要讨论了一个名为MotionLM的模型,该模型旨在进行多智能体运动预测。文章详细介绍了MotionLM作为一个生成模型用于预测多个交互智能体未来轨迹的开发和实施。文章强调了现有方法的局限性,这些方法要么侧重于边际轨迹生成,要么在不明确建模轨迹内的时间依赖性的情况下进行交互评分。
相反,MotionLM将轨迹生成和交互建模结合在一个单一的解码过程中,利用基于自回归语言模型的训练目标。该模型通过采样离散的运动标记并关注其他智能体的动作来生成联合轨迹。文章描述了MotionLM的架构,包括场景编码器和轨迹解码器,并解释了模型的分解和训练目标。
作者还提供了在Waymo Open Motion数据集上进行的实验结果,展示了MotionLM在预测联合智能体轨迹方面的改进性能。
总体而言,文章将MotionLM作为一种有效的多智能体运动预测模型,能够捕捉驾驶场景的多模态性和时间依赖性。















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









