







1、环境配置html
- win10
- vs2017
- libtorch-win-shared-with-deps-debug-1.8.1+cpu
- opencv349
在源码中的requirments.txt中要求依赖库版本以下;在c++环境中,我们这里用的libtorch1.8.1(今天我也测试了环境:libtorch-win-shared-with-deps-1.7.1+cu110,也可以正常检测,和本博客最终结果一致);同时用opencv&c++做图像处理,不须要c++版本torchvision:ios
1 # pip install -r requirements.txt 2 3 # base ---------------------------------------- 4 matplotlib>=3.2.2 5 numpy>=1.18.5 6 opencv-python>=4.1.2 7 Pillow 8 PyYAML>=5.3.1 9 scipy>=1.4.1 10 torch>=1.7.0 11 torchvision>=0.8.1 # 如下内容神略
为了便于调试,我这里下载的是debug版本libtorch,并且是cpu版本,代码调好后,转CPU也很简单吧。opencv版本其实随意,opencv3++就行。
2、.torchscript.pt版本模型导出git
打开yolov5.4源码目录下models文件夹,编辑export.py脚本,以下,将58行注释,新增59行(GPU版本还须要修改一些内容,GPU版本后续更新,这篇博客只管CPU版本)github
1 """Exports a YOLOv5 *.pt model to ONNX and TorchScript formats
2
3 Usage:
4 $ export PYTHONPATH="$PWD" && python models/export.py --weights ./weights/yolov5s.pt --img 640 --batch 1
5 """
6
7 import argparse
8 import sys
9 import time
10
11 sys.path.append('./') # to run '$ python *.py' files in subdirectories
12
13 import torch
14 import torch.nn as nn
15
16 import models
17 from models.experimental import attempt_load
18 from utils.activations import Hardswish, SiLU
19 from utils.general import set_logging, check_img_size
20 from utils.torch_utils import select_device
21
22 if __name__ == '__main__':
23 parser = argparse.ArgumentParser()
24 parser.add_argument('--weights', type=str, default='./yolov5s.pt', help='weights path') # from yolov5/models/
25 parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='image size') # height, width
26 parser.add_argument('--batch-size', type=int, default=1, help='batch size')
27 parser.add_argument('--dynamic', action='store_true', help='dynamic ONNX axes')
28 parser.add_argument('--grid', action='store_true', help='export Detect() layer grid')
29 parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
30 opt = parser.parse_args()
31 opt.img_size *= 2 if len(opt.img_size) == 1 else 1 # expand
32 print(opt)
33 set_logging()
34 t = time.time()
35
36 # Load PyTorch model
37 device = select_device(opt.device)
38 model = attempt_load(opt.weights, map_location=device) # load FP32 model
39 labels = model.names
40
41 # Checks
42 gs = int(max(model.stride)) # grid size (max stride)
43 opt.img_size = [check_img_size(x, gs) for x in opt.img_size] # verify img_size are gs-multiples
44
45 # Input
46 img = torch.zeros(opt.batch_size, 3, *opt.img_size).to(device) # image size(1,3,320,192) iDetection
47
48 # Update model
49 for k, m in model.named_modules():
50 m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
51 if isinstance(m, models.common.Conv): # assign export-friendly activations
52 if isinstance(m.act, nn.Hardswish):
53 m.act = Hardswish()
54 elif isinstance(m.act, nn.SiLU):
55 m.act = SiLU()
56 # elif isinstance(m, models.yolo.Detect):
57 # m.forward = m.forward_export # assign forward (optional)
58 #model.model[-1].export = not opt.grid # set Detect() layer grid export
59 model.model[-1].export = False
60 y = model(img) # dry run
61
62 # TorchScript export
63 try:
64 print('\nStarting TorchScript export with torch %s...' % torch.__version__)
65 f = opt.weights.replace('.pt', '.torchscript.pt') # filename
66 ts = torch.jit.trace(model, img)
67 ts.save(f)
68 print('TorchScript export success, saved as %s' % f)
69 except Exception as e:
70 print('TorchScript export failure: %s' % e)
71 # 如下代码省略,无需求改
72 ......
接着在conda环境激活yolov5.4的虚拟环境,执行下面脚本:api
(提示:如何配置yolov5.4环境?参考我这篇Win10环境下YOLO5 快速配置与测试:https://www.cnblogs.com/winslam/p/13474330.html)bash
python models/export.py --weights ./weights/yolov5s.pt --img 640 --batch 1
错误解决:一、bash窗口可能提示 not module utils;这是由于没有将源码根目录添加进环境变量,linux下执行如下命令就行app
export PYTHONPATH="$PWD"
win下,我建议直接用pycharm打开yolov5.4工程,在ide中去执行export.py就行,若是你没有下载好yolovs..pt,他会自动下载,下载连接会打印在控制台,以下,若是下不动,能够尝试复制连接到迅雷
Downloading https://github.com/ultralytics/yolov5/releases/download/v4.0/yolov5s.pt to yolov5s.pt...
执行export.py后出现以下警告:
1 D:\yolov5-0327\models\yolo.py:50: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs! 2 if self.grid[i].shape[2:4] != x[i].shape[2:4]: 3 D:\Program Files\Anaconda\envs\yolov5\lib\site-packages\torch\jit\_trace.py:934: TracerWarning: Encountering a list at the output of the tracer might cause the trace to be incorrect, this is only valid if the container structure does not change based on the module's inputs. Consider using a constant container instead (e.g. for `list`, use a `tuple` instead. for `dict`, use a `NamedTuple` instead). If you absolutely need this and know the side effects, pass strict=False to trace() to allow this behavior. 4 module._c._create_method_from_trace( 5 TorchScript export success, saved as ./yolov5s.torchscript.pt 6 ONNX export failure: No module named 'onnx' 7 CoreML export failure: No module named 'coremltools' 8 9 Export complete (10.94s). Visualize with https://github.com/lutzroeder/netron.
警告内容之后处理,不影响部署
3、C++版本yolov5.4实现
libtorch在vs环境中配置(在项目属性中设置下面加粗项目):
include:
D:\libtorch-win-shared-with-deps-debug-1.8.1+cpu\libtorch\include
D:\libtorch-win-shared-with-deps-debug-1.8.1+cpu\libtorch\include\torch\csrc\api\include
lib:
D:\libtorch-win-shared-with-deps-debug-1.8.1+cpu\libtorch\lib
依赖库:
c10.lib torch.lib torch_cpu.lib
环境变量(须要重启):
D:\libtorch-win-shared-with-deps-debug-1.8.1+cpu\libtorch\lib
配置好以后,vs2017 设置为debug X64模式,下面是yolov5.4版本c++代码
输入是:
- 上述转好的.torchscript.pt格式的模型文件
- coco.names
- 一张图
1 #include <torch/script.h>
2 #include <torch/torch.h>
3 #include<opencv2/opencv.hpp>
4 #include <iostream>
5
6
7 std::vector<std::string> LoadNames(const std::string& path)
8 {
9 // load class names
10 std::vector<std::string> class_names;
11 std::ifstream infile(path);
12 if (infile.is_open()) {
13 std::string line;
14 while (std::getline(infile, line)) {
15 class_names.emplace_back(line);
16 }
17 infile.close();
18 }
19 else {
20 std::cerr << "Error loading the class names!\n";
21 }
22
23 return class_names;
24 }
25
26 std::vector<float> LetterboxImage(const cv::Mat& src, cv::Mat& dst, const cv::Size& out_size)
27 {
28 auto in_h = static_cast<float>(src.rows);
29 auto in_w = static_cast<float>(src.cols);
30 float out_h = out_size.height;
31 float out_w = out_size.width;
32
33 float scale = std::min(out_w / in_w, out_h / in_h);
34
35 int mid_h = static_cast<int>(in_h * scale);
36 int mid_w = static_cast<int>(in_w * scale);
37
38 cv::resize(src, dst, cv::Size(mid_w, mid_h));
39
40 int top = (static_cast<int>(out_h) - mid_h) / 2;
41 int down = (static_cast<int>(out_h) - mid_h + 1) / 2;
42 int left = (static_cast<int>(out_w) - mid_w) / 2;
43 int right = (static_cast<int>(out_w) - mid_w + 1) / 2;
44
45 cv::copyMakeBorder(dst, dst, top, down, left, right, cv::BORDER_CONSTANT, cv::Scalar(114, 114, 114));
46
47 std::vector<float> pad_info{ static_cast<float>(left), static_cast<float>(top), scale };
48 return pad_info;
49 }
50
51 enum Det
52 {
53 tl_x = 0,
54 tl_y = 1,
55 br_x = 2,
56 br_y = 3,
57 score = 4,
58 class_idx = 5
59 };
60
61 struct Detection
62 {
63 cv::Rect bbox;
64 float score;
65 int class_idx;
66 };
67
68 void Tensor2Detection(const at::TensorAccessor<float, 2>& offset_boxes,
69 const at::TensorAccessor<float, 2>& det,
70 std::vector<cv::Rect>& offset_box_vec,
71 std::vector<float>& score_vec)
72 {
73
74 for (int i = 0; i < offset_boxes.size(0); i++) {
75 offset_box_vec.emplace_back(
76 cv::Rect(cv::Point(offset_boxes[i][Det::tl_x], offset_boxes[i][Det::tl_y]),
77 cv::Point(offset_boxes[i][Det::br_x], offset_boxes[i][Det::br_y]))
78 );
79 score_vec.emplace_back(det[i][Det::score]);
80 }
81 }
82
83 void ScaleCoordinates(std::vector<Detection>& data, float pad_w, float pad_h,
84 float scale, const cv::Size& img_shape)
85 {
86 auto clip = [](float n, float lower, float upper)
87 {
88 return std::max(lower, std::min(n, upper));
89 };
90
91 std::vector<Detection> detections;
92 for (auto & i : data) {
93 float x1 = (i.bbox.tl().x - pad_w) / scale; // x padding
94 float y1 = (i.bbox.tl().y - pad_h) / scale; // y padding
95 float x2 = (i.bbox.br().x - pad_w) / scale; // x padding
96 float y2 = (i.bbox.br().y - pad_h) / scale; // y padding
97
98 x1 = clip(x1, 0, img_shape.width);
99 y1 = clip(y1, 0, img_shape.height);
100 x2 = clip(x2, 0, img_shape.width);
101 y2 = clip(y2, 0, img_shape.height);
102
103 i.bbox = cv::Rect(cv::Point(x1, y1), cv::Point(x2, y2));
104 }
105 }
106
107
108 torch::Tensor xywh2xyxy(const torch::Tensor& x)
109 {
110 auto y = torch::zeros_like(x);
111 // convert bounding box format from (center x, center y, width, height) to (x1, y1, x2, y2)
112 y.select(1, Det::tl_x) = x.select(1, 0) - x.select(1, 2).div(2);
113 y.select(1, Det::tl_y) = x.select(1, 1) - x.select(1, 3).div(2);
114 y.select(1, Det::br_x) = x.select(1, 0) + x.select(1, 2).div(2);
115 y.select(1, Det::br_y) = x.select(1, 1) + x.select(1, 3).div(2);
116 return y;
117 }
118
119 std::vector<std::vector<Detection>> PostProcessing(const torch::Tensor& detections,
120 float pad_w, float pad_h, float scale, const cv::Size& img_shape,
121 float conf_thres, float iou_thres)
122 {
123 /***
124 * 结果纬度为batch index(0), top-left x/y (1,2), bottom-right x/y (3,4), score(5), class id(6)
125 * 13*13*3*(1+4)*80
126 */
127 constexpr int item_attr_size = 5;
128 int batch_size = detections.size(0);
129 // number of classes, e.g. 80 for coco dataset
130 auto num_classes = detections.size(2) - item_attr_size;
131
132 // get candidates which object confidence > threshold
133 auto conf_mask = detections.select(2, 4).ge(conf_thres).unsqueeze(2);
134
135 std::vector<std::vector<Detection>> output;
136 output.reserve(batch_size);
137
138 // iterating all images in the batch
139 for (int batch_i = 0; batch_i < batch_size; batch_i++) {
140 // apply constrains to get filtered detections for current image
141 auto det = torch::masked_select(detections[batch_i], conf_mask[batch_i]).view({ -1, num_classes + item_attr_size });
142
143 // if none detections remain then skip and start to process next image
144 if (0 == det.size(0)) {
145 continue;
146 }
147
148 // compute overall score = obj_conf * cls_conf, similar to x[:, 5:] *= x[:, 4:5]
149 det.slice(1, item_attr_size, item_attr_size + num_classes) *= det.select(1, 4).unsqueeze(1);
150
151 // box (center x, center y, width, height) to (x1, y1, x2, y2)
152 torch::Tensor box = xywh2xyxy(det.slice(1, 0, 4));
153
154 // [best class only] get the max classes score at each result (e.g. elements 5-84)
155 std::tuple<torch::Tensor, torch::Tensor> max_classes = torch::max(det.slice(1, item_attr_size, item_attr_size + num_classes), 1);
156
157 // class score
158 auto max_conf_score = std::get<0>(max_classes);
159 // index
160 auto max_conf_index = std::get<1>(max_classes);
161
162 max_conf_score = max_conf_score.to(torch::kFloat).unsqueeze(1);
163 max_conf_index = max_conf_index.to(torch::kFloat).unsqueeze(1);
164
165 // shape: n * 6, top-left x/y (0,1), bottom-right x/y (2,3), score(4), class index(5)
166 det = torch::cat({ box.slice(1, 0, 4), max_conf_score, max_conf_index }, 1);
167
168 // for batched NMS
169 constexpr int max_wh = 4096;
170 auto c = det.slice(1, item_attr_size, item_attr_size + 1) * max_wh;
171 auto offset_box = det.slice(1, 0, 4) + c;
172
173 std::vector<cv::Rect> offset_box_vec;
174 std::vector<float> score_vec;
175
176 // copy data back to cpu
177 auto offset_boxes_cpu = offset_box.cpu();
178 auto det_cpu = det.cpu();
179 const auto& det_cpu_array = det_cpu.accessor<float, 2>();
180
181 // use accessor to access tensor elements efficiently
182 Tensor2Detection(offset_boxes_cpu.accessor<float, 2>(), det_cpu_array, offset_box_vec, score_vec);
183
184 // run NMS
185 std::vector<int> nms_indices;
186 cv::dnn::NMSBoxes(offset_box_vec, score_vec, conf_thres, iou_thres, nms_indices);
187
188 std::vector<Detection> det_vec;
189 for (int index : nms_indices) {
190 Detection t;
191 const auto& b = det_cpu_array[index];
192 t.bbox =
193 cv::Rect(cv::Point(b[Det::tl_x], b[Det::tl_y]),
194 cv::Point(b[Det::br_x], b[Det::br_y]));
195 t.score = det_cpu_array[index][Det::score];
196 t.class_idx = det_cpu_array[index][Det::class_idx];
197 det_vec.emplace_back(t);
198 }
199
200 ScaleCoordinates(det_vec, pad_w, pad_h, scale, img_shape);
201
202 // save final detection for the current image
203 output.emplace_back(det_vec);
204 } // end of batch iterating
205
206 return output;
207 }
208
209 void Demo(cv::Mat& img,
210 const std::vector<std::vector<Detection>>& detections,
211 const std::vector<std::string>& class_names,
212 bool label = true)
213 {
214 if (!detections.empty()) {
215 for (const auto& detection : detections[0]) {
216 const auto& box = detection.bbox;
217 float score = detection.score;
218 int class_idx = detection.class_idx;
219
220 cv::rectangle(img, box, cv::Scalar(0, 0, 255), 2);
221
222 if (label) {
223 std::stringstream ss;
224 ss << std::fixed << std::setprecision(2) << score;
225 std::string s = class_names[class_idx] + " " + ss.str();
226
227 auto font_face = cv::FONT_HERSHEY_DUPLEX;
228 auto font_scale = 1.0;
229 int thickness = 1;
230 int baseline = 0;
231 auto s_size = cv::getTextSize(s, font_face, font_scale, thickness, &baseline);
232 cv::rectangle(img,
233 cv::Point(box.tl().x, box.tl().y - s_size.height - 5),
234 cv::Point(box.tl().x + s_size.width, box.tl().y),
235 cv::Scalar(0, 0, 255), -1);
236 cv::putText(img, s, cv::Point(box.tl().x, box.tl().y - 5),
237 font_face, font_scale, cv::Scalar(255, 255, 255), thickness);
238 }
239 }
240 }
241
242 cv::namedWindow("Result", cv::WINDOW_NORMAL);
243 cv::imshow("Result", img);
244
245 }
246
247 int main()
248 {
249 // yolov5Ns.torchscript.pt 报错,因此仅能读取yolov5.4模型
250 torch::jit::script::Module module = torch::jit::load("yolov5sxxx.torchscript.pt");
251 torch::DeviceType device_type = torch::kCPU;
252 module.to(device_type);
253 /*module.to(torch::kHalf);*/
254 module.eval();
255
256 // img 必须读取3-channels图片
257 cv::Mat img = cv::imread("zidane.jpg", -1);
258 // 读取类别
259 std::vector<std::string> class_names = LoadNames("coco.names");
260 if (class_names.empty()) {
261 return -1;
262 }
263
264 // set up threshold
265 float conf_thres = 0.4;
266 float iou_thres = 0.5;
267
268 //inference
269 torch::NoGradGuard no_grad;
270 cv::Mat img_input = img.clone();
271 std::vector<float> pad_info = LetterboxImage(img_input, img_input, cv::Size(640, 640));
272 const float pad_w = pad_info[0];
273 const float pad_h = pad_info[1];
274 const float scale = pad_info[2];
275 cv::cvtColor(img_input, img_input, cv::COLOR_BGR2RGB); // BGR -> RGB
276 //归一化须要是浮点类型
277 img_input.convertTo(img_input, CV_32FC3, 1.0f / 255.0f); // normalization 1/255
278 // 加载图像到设备
279 auto tensor_img = torch::from_blob(img_input.data, { 1, img_input.rows, img_input.cols, img_input.channels() }).to(device_type);
280 // BHWC -> BCHW
281 tensor_img = tensor_img.permute({ 0, 3, 1, 2 }).contiguous(); // BHWC -> BCHW (Batch, Channel, Height, Width)
282
283 std::vector<torch::jit::IValue> inputs;
284 // 在容器尾部添加一个元素,这个元素原地构造,不须要触发拷贝构造和转移构造
285 inputs.emplace_back(tensor_img);
286
287 torch::jit::IValue output = module.forward(inputs);
288
289 // 解析结果
290 auto detections = output.toTuple()->elements()[0].toTensor();
291 auto result = PostProcessing(detections, pad_w, pad_h, scale, img.size(), conf_thres, iou_thres);
292 // visualize detections
293 if (true) {
294 Demo(img, result, class_names);
295 cv::waitKey(0);
296 }
297 return 1;
298 }
View Code
4、问题记录
我参考的是连接[1][2]代码,很是坑,[1][2]代码是同样的,也不知道谁抄谁的,代码中没有说明yolov5具体版本,并且有不少问题,不过仍是感谢给了参考。
在原版代码整理以后,再将其改成第三节中的cpp,,第三节中的cpp相对原版libtorch实现,我作了以下修改(改了一些错误),参考了资料[3]:
一、注释 detector.h中,注释以下头文件
//#include <c10/cuda/CUDAStream.h>
#//include <ATen/cuda/CUDAEvent.h>
二、错误1: “std”: 不明确的符号
解决办法:项目->属性->c/c++->语言->符合模式->选择否
,有个老哥给出的方法是,在std报错的地方改成:"::std",不推荐!
三、libtorch中,执行到加载模型那一行代码,跳进libtorch库中的Assert,提示错误:AT_ASSERT(isTuple(), "Expected Tuple but got ", tagKind());(我们是libtorch debug版本,还能跳到这一行,要是release,你都不知道错在哪里,因此常备debug版本,颇有必要)
多是你转模型的yolov5版本不是5.4,而是是5.三、5.3.一、5.三、5.1;还有多是你export.py脚本中没有按照上面设置。
参考:https://blog.csdn.net/weixin_42398658/article/details/111954760
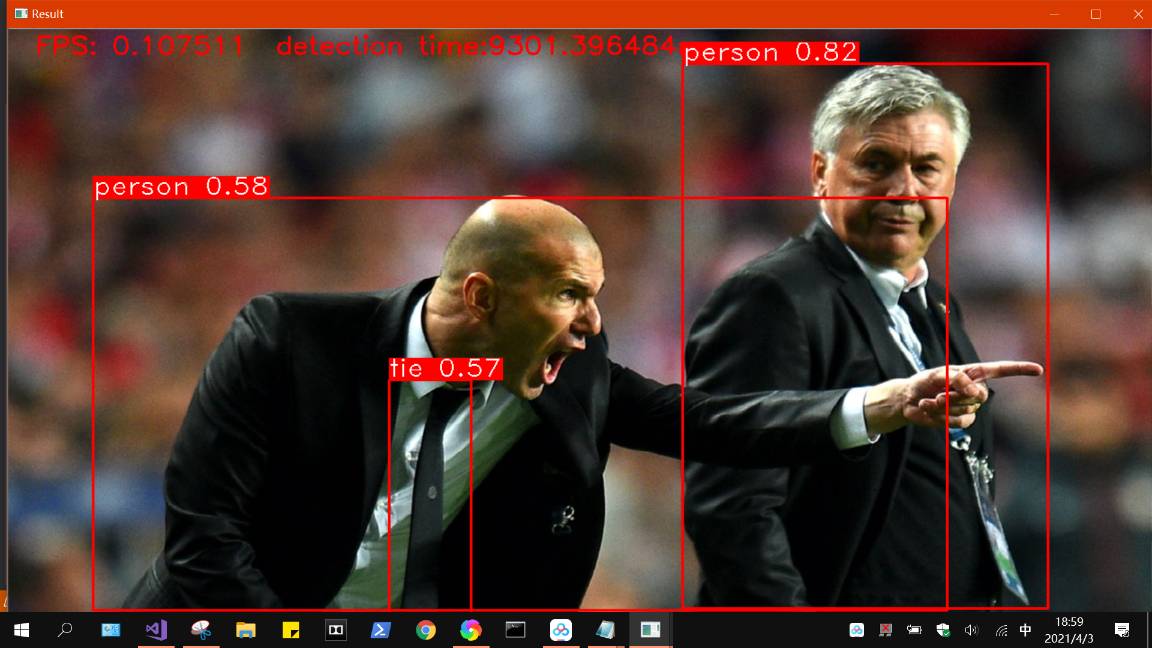
四、上面导出模型控制台打印的警告信息还没解决,由于部署后,检测效果和python版本有差异(其实几乎差很少),以下:
以下:左边是官方结果,右边是libtorch模型部署结构,置信度不相上下,开心!


reference:
[1] libtorch代码参考;https://zhuanlan.zhihu.com/p/338167520
[2] libtorch代码参考;https://gitee.com/goodtn/libtorch-yolov5-gpu/tree/master
[3] libtorch相关报错总结(很是nice!):https://blog.csdn.net/qq_18305555/article/details/114013236














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









