






近年来,视觉、语言和多模态预训练逐渐呈现出统一的趋势。对于多模态基础模型,我们希望其不仅能够处理多模态相关任务,还希望其在单模态任务上也具有优异的性能。然而,现有的多模态模型,往往不能很好的平衡模态协作(collaboration)和模态纠缠(entanglement)的问题,从而限制了在各种单模态及跨模态下游任务上的性能。
为了解决这一问题,阿里达摩院的研究者提出模块化的多模态基础模型mPLUG-2,能够处理文本、图像和视频等多种模态输入,在30+多模态及单模态任务上,相比以往采用同等数据和模型规模的方法取得了领先或相近的性能,并在VideoQA和VideoCaption等任务上,取得了超越Flamingo、VideoCoCa等超大规模模型的SOTA表现。
该工作已被机器学习顶级会议ICML 2023接收,此外,mPLUG-Owl 是阿⾥巴巴达摩院 mPLUG 系列的最新工作,延续了 mPLUG 系列的模块化训练思想,把 LLM 升级为一个多模态大模型,论文和代码地址如下:
论文地址: https://arxiv.org/pdf/2302.00402.pdf
mPLUG-2地址: https://github.com/X-PLUG/mPLUG-2
mPLUG-Owl地址: https://github.com/X-PLUG/mPLUG-Owl
方法概览
近期,Transformer结构的成功应用,使得语言、视觉和多模态预训练呈现出大融合的趋势。以Flamingo为代表的多模态基础模型,为多模态数据共享单一的建模网络,并采用序列生成框架来统一多种任务和模态,以此来利用模态协作的信息。然而,由于不同模态涉及到的任务的巨大差异,这种策略将面临模态纠缠的问题,多个模态之间可能会相互干扰。以往的单模块基础模型,难以平衡模态协作的收益和模态纠缠的干扰,从而限制了下游任务上的性能。
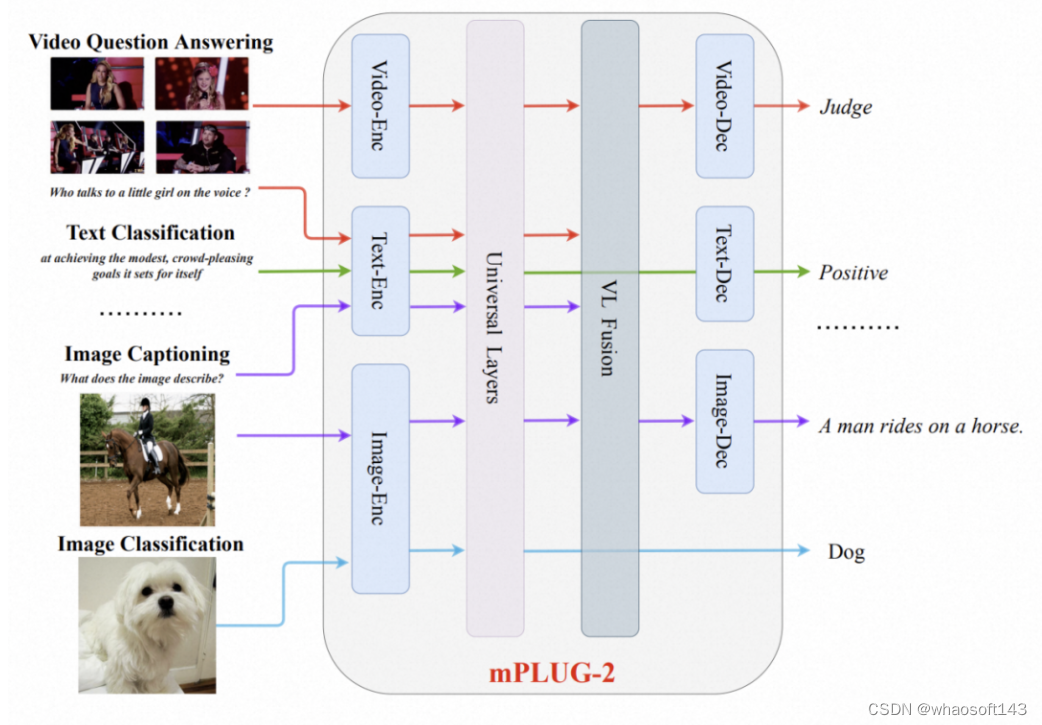
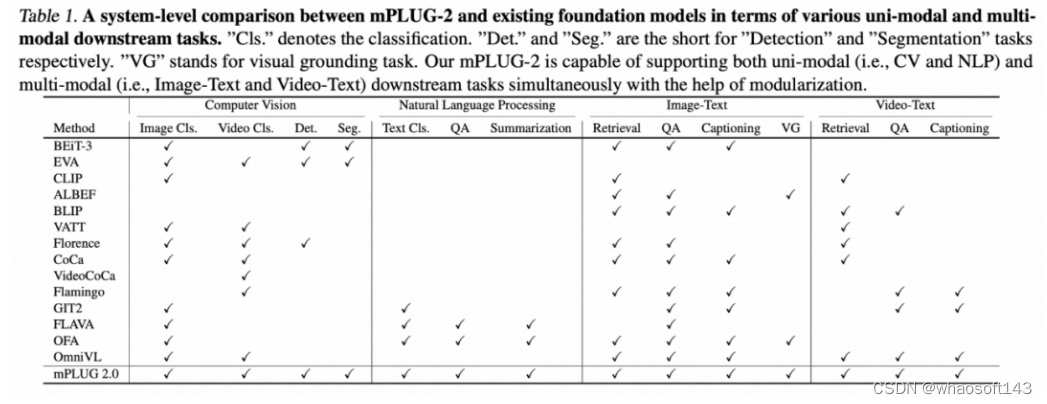
为此,阿里达摩院研究团队在mPLUG-2这项工作中,引入了一种新的多模态基础模型的统一范式。如图所示,mPLUG-2采用模块化的网络设计,来平衡模态协作和模态纠缠。研究者设计了特定的共享功能模块以鼓励模态协作,同时保留特定于模态的模块以缓解模态纠缠问题。基于模块化的设计,不同的模块可以灵活地选取和组合,以适应不同的单模态及多模态的理解和生成任务。下表展示了mPLUG-2支持的下游任务,可以看到相比以往的方法,mPLUG-2能够处理更多类型的跨文本、图像和视频的下游任务。
模型细节
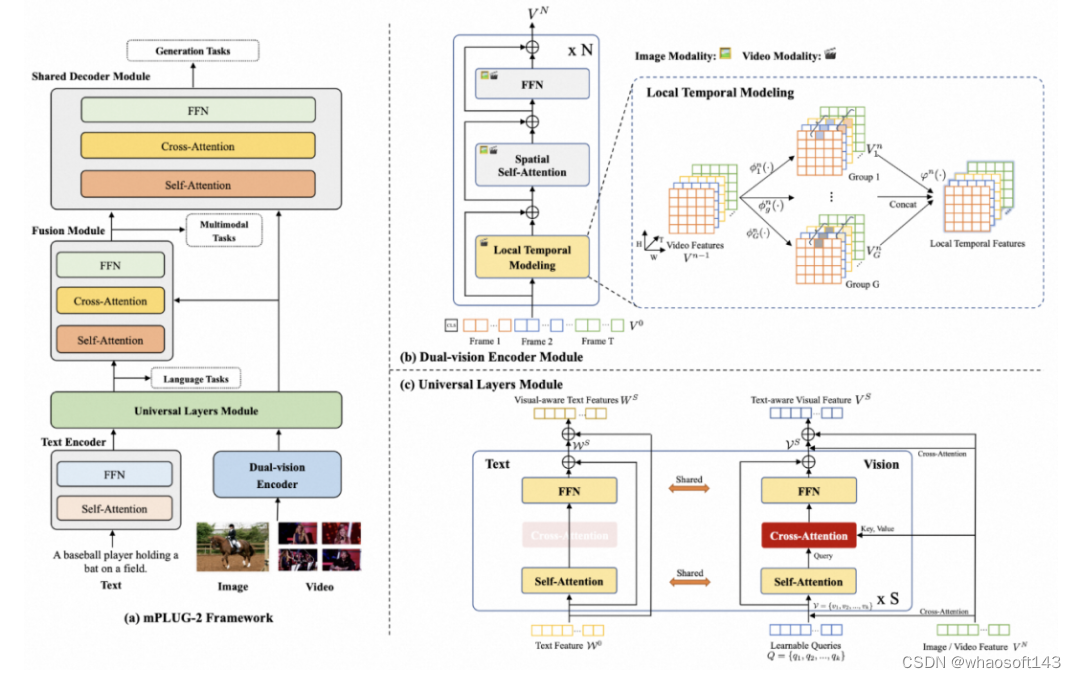
如图所示,mPLUG-2的主体结构包含文本编码器、视觉编码器、通用层模块、多模态融合模块以及一个共享的解码器模块。作者首先利用文本和视觉编码器,分别从文本、图像/视频中提取相应模态的信息,再通过参数共享的通用层模块(Universal Layers Module)将不同模态映射到共享的语义空间中。对于多模态任务,融合模块(Fusion Module)被用来产生视觉-语言融合的跨模态表征。最终,这些单模态和跨模态表征被送入一个共享的解码器模块中,以应对不同种类的生成任务。下面对作者设计的双视觉编码器和通用层模块做详细的介绍。
(1)双视觉编码器
为了提取图像、视频等视觉模态的信息,作者提出双视觉编码器。为了缓解视频时空建模中序列长度过大导致的学习困难问题,将视频分解为空间和时间表示,如图(b)所示,利用Transformer的自注意力层和前馈层进行空间建模,并针对视频输入,提出一种新颖的局部时序建模模块。该模块将视频特征在通道维度分组,对不同组的特征应用不同的时序建模参数(如时序卷积),从而在不同的表征子空间中学习更为丰富的时序特征。此外,空间和时间信息的解耦,使得双视觉编码器能够实现图像和视频的参数共享,从而更加高效地学习空间和时间表征。
(2)通用层模块
为了使模型能够从不同模态数据的协作中受益,作者提出通用层模块使得视觉和语言模态共享语义空间。如图(c)所示,为了降低通用层的计算复杂度,作者设置固定数量的视觉query,并将来自双视觉编码器的图像或视频特征作为交叉注意力层的输入。在每个通用层中,视觉query和文本特征通过共享参数的自注意力层来对齐语义,然后视觉query通过交叉注意力从原始视觉特征中提取视觉信息,之后视觉query和文本特征通过共享参数的前馈层进行特征变换。训练阶段,mPLUG-2使用掩码语言恢复(MLM)、视觉-文本对比学习(VLC)和视觉-文本匹配(VLM)等预训练任务,并利用基于指令的语言模型损失来统一各种生成任务。推理阶段,mPLUG-2的模块化设计,使其能够针对不同的单模态和跨模态任务选择不同的模块组合。
实验结果
多模态任务
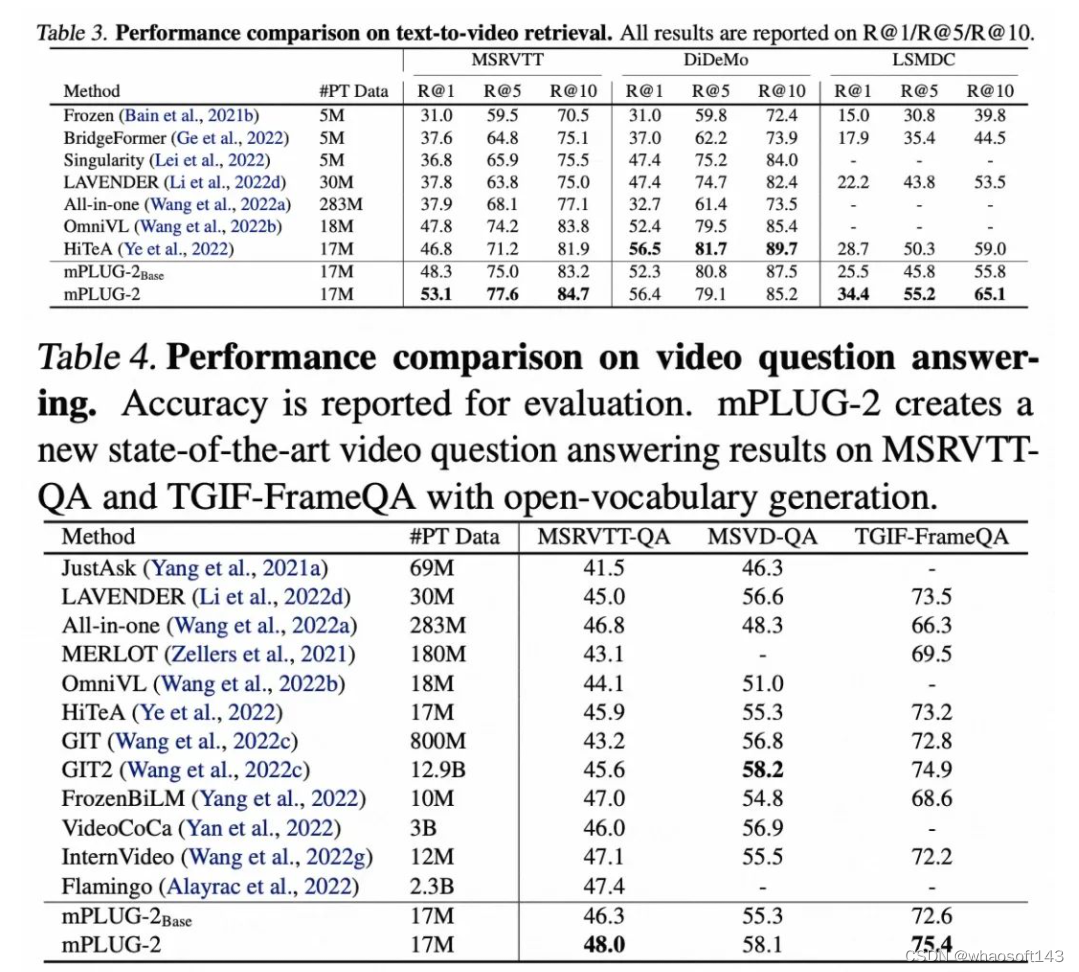
实验结果表明,mPLUG-2在视频、图像的跨模态检索、问答、描述及视觉定位等多种多模态任务上,相比采用相近预训练数据和模型规模的方法,取得了SOTA性能。
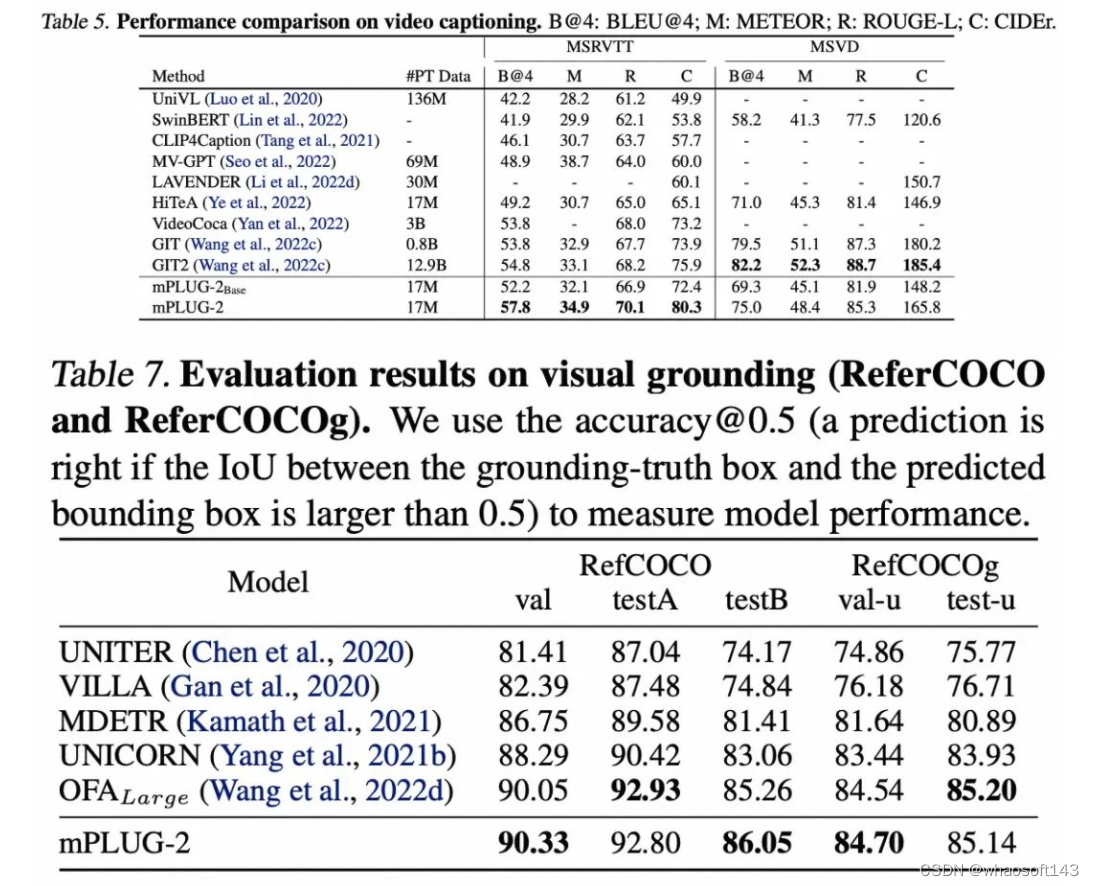
语言任务
相比单模态的预训练语言模型和其他多模态预训练模型,mPLUG-2在GLUE benchmark上取得了有竞争力的表现。这一实验结果验证了利用通用层模块进行模态协作的有效性。
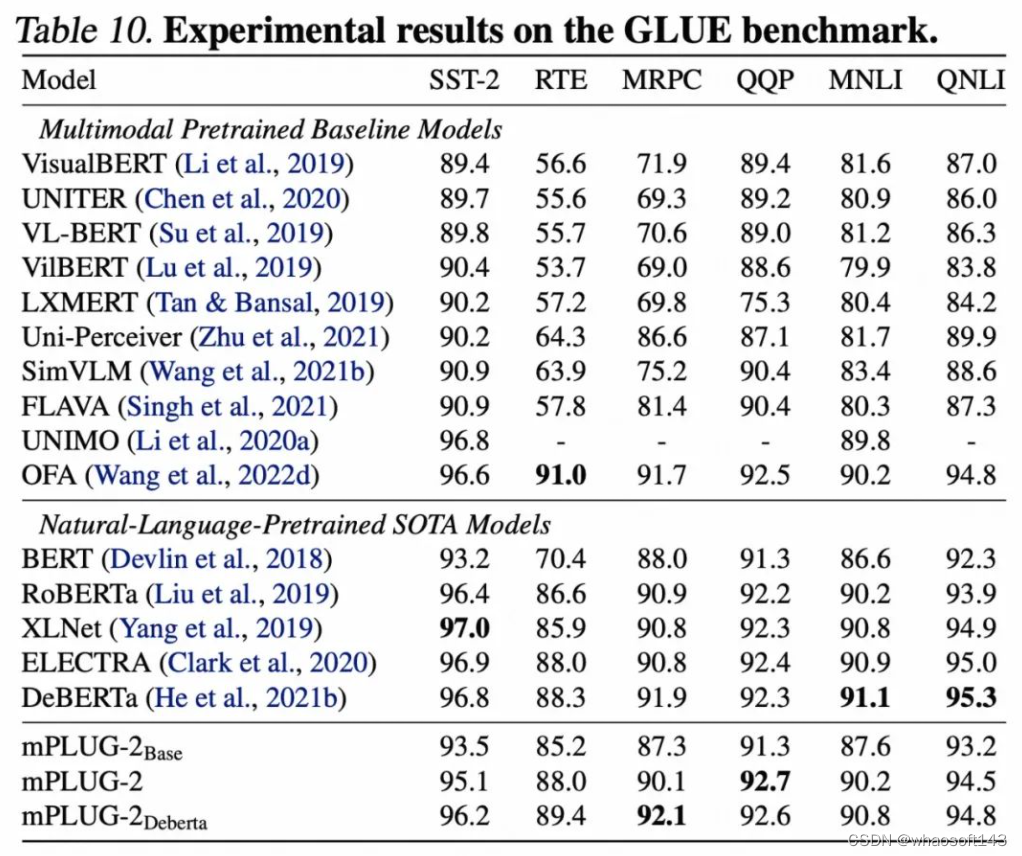
视觉任务
此外,在视频行为识别、图像分类等纯视觉任务上,mPLUG-2也取得了有竞争力的结果。
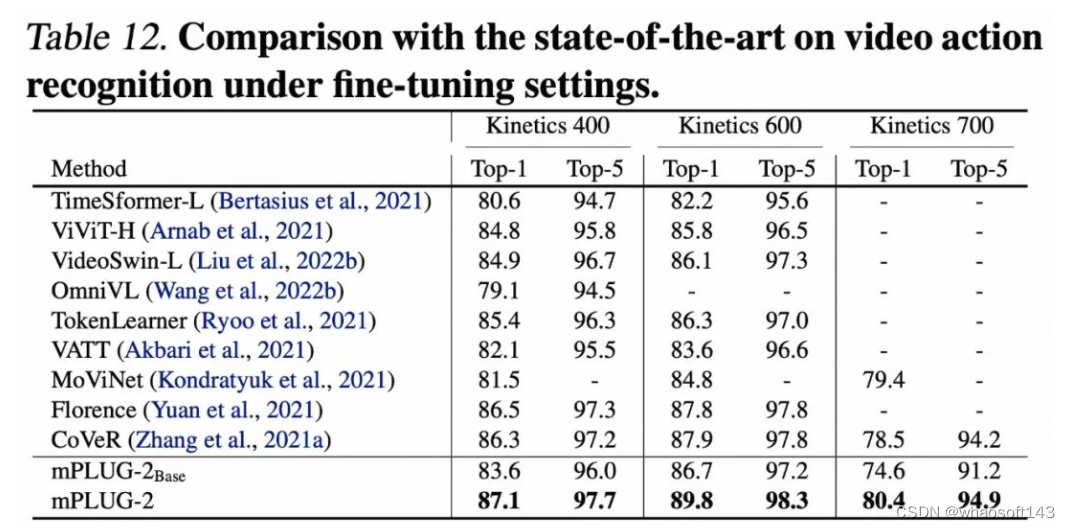
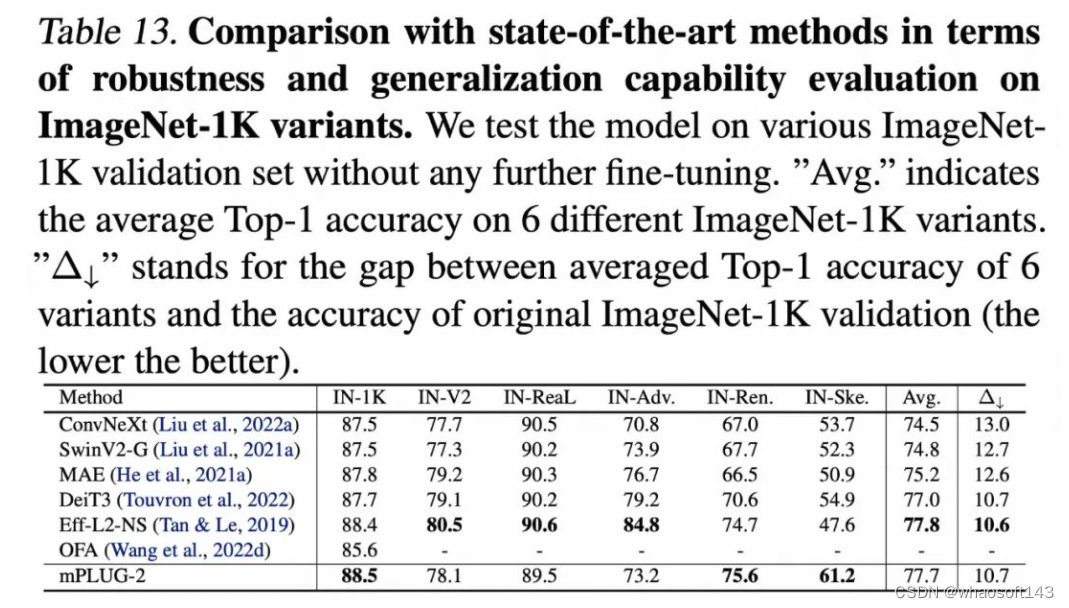















 1186
1186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









