







来源:ACL2019
论文:《COMET : Commonsense Transformers for Automatic Knowledge Graph Construction》
Abstract
我们首次全面研究了两种流行常识知识图的自动知识库构建:ATOMIC(Sap et al.,2019)和ConceptNet(Speer et al.,2017)。与许多使用规范模板存储知识的传统知识库相反,常识知识库只存储结构松散的、文本描述开放的知识。我们认为,实现常识自动完成的一个重要步骤是开发常识知识的生成模型,并提出了Commonsense Transformers(COMET),来学习生成自然语言里丰富且多样的常识描述。尽管有常识建模的挑战,我们的研究显示,当深层预训练语言模型的内隐知识被转移到常识知识图谱中生成外显知识时,会有很好的结果。实验结果表明,COMET能够产生人类认为高质量的新知识,top1高达77.5%(ATOMIC)和91.7%(ConceptNet)的精度在前1名,这接近人类对这些资源的表现。我们的发现表明,使用生成性常识模型自动完成常识知识库可能很快成为提取方法的一种可行的替代方法。
Introduction
Previous work

最近在训练深层语境化语言模型方面的进展(Peters等人,2018;Radford等人,2018;Devlin等人,2018)提供了一个机会,可以作为除了提取方法以外的常识知识库构建途径。当这些大型语言模型的底层表示被微调以解决最终任务时,它们显示出良好的性能,从而在各种复杂问题上获得最新的结果。
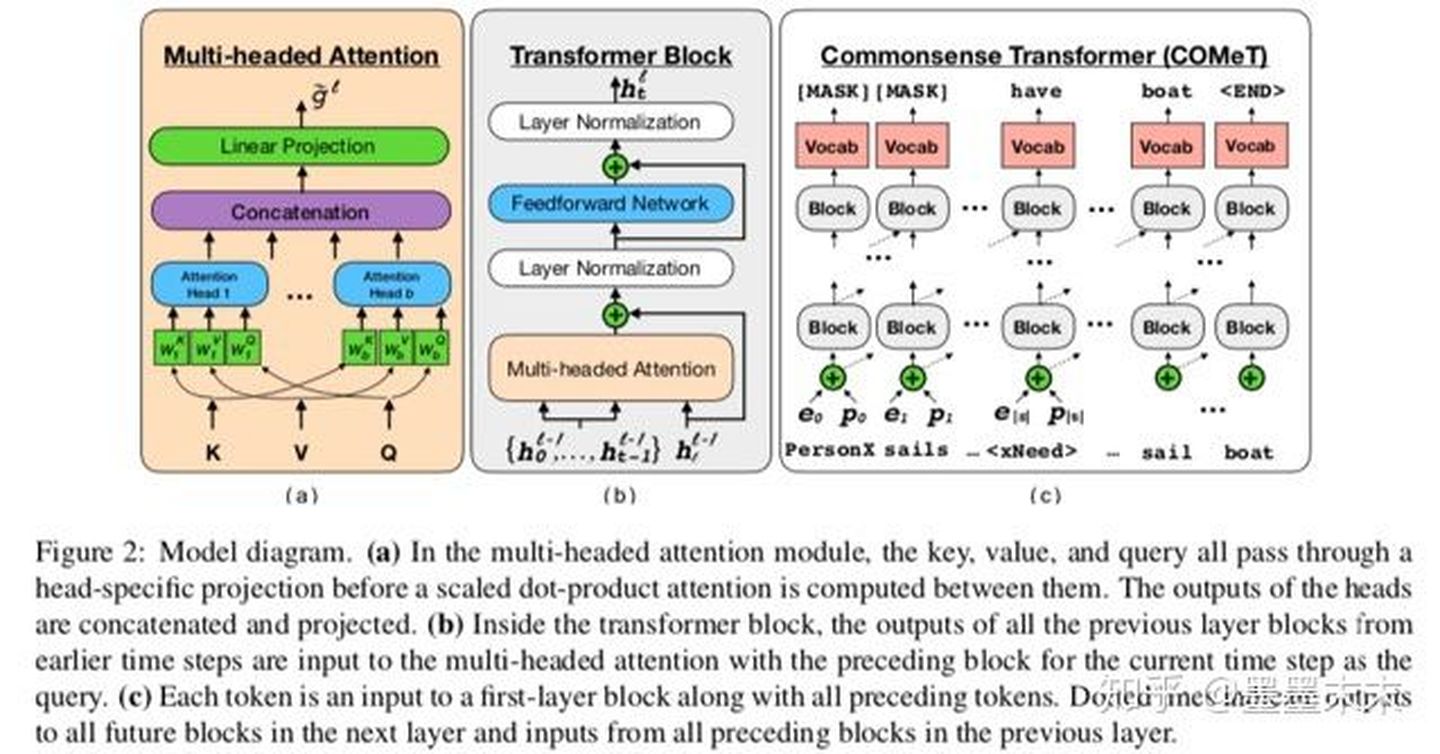
在本文中,我们定义了COMET:通过对已有的三元组作为种子知识集进行训练来构建常识知识库。利用这个种子集,一个预先训练的语言模型进行学习适用于知识生成的表示,并产生高质量的新元组。
contributions
1、开发了知识库构建的生成方法。模型必须学习生成新节点,并通过生成连贯地完善现有种子的短语和关系类型来识别与现有节点之间的边缘。
2、开发了一个使用大型transformer语言模型来学习生成常识知识元组的框架。
3、最后,我们对两个领域的常识知识(ATOMIC and ConceptNet)的质量、新颖性和多样性进行了实证研究;对学习一个有效的知识模型需要的种子元组数目的有效性研究。
Learning to Generate Commonsense
COMET是一个自适应框架,用于通过在知识元组的种子集上训练语言模型,从语言模型构建常识知识库。这些元组为COMET提供了必须学习的知识库结构和关系,COMET学习适应预训练模型从中学习语言模型表示,以向种子知识图添加新的节点和边。
Task
更具体地说,该问题假
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4228
4228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









