







上一章节
本章节代码
目录
三、Linux 与 Windows 系统中创建线程的方式及跨平台解决方案
6、condition_variable 头文件中的常见用法
一、线程与进程的基本概念
1、线程的定义与起源
想象一个繁忙的餐厅,每个服务员负责为不同的顾客提供服务,这里的服务员就好比线程,而餐厅好比就是一个进程。
线程是程序执行流的最小单元,是操作系统能够进行运算调度的基本单位。它被包含在进程之中,是进程中的实际运作单位。
2、线程与进程的关联
进程可以看作是整个餐厅,它拥有自己独立的资源,如餐厅的场地、餐具、食材等。而
线程则是餐厅里的服务员,它们共享进程的资源,在进程提供的环境中执行具体的任务。一个进程可以包含多个线程,这些线程协同工作,共同完成进程的目标。
3、并发实现的优缺点
3.1、进程并发
优点:进程之间
相互独立,一个进程的崩溃不会影响其他进程,就像一家餐厅倒闭了不会影响隔壁餐厅的生意。
这种独立性使得进程并发在处理一些对安全性和稳定性要求较高的任务时非常有用。
缺点:
进程的创建和销毁开销较大,每次创建一个新的进程都需要操作系统分配大量的资源,销毁进程时也需要进行资源回收。而且进程间通信相对复杂,需要使用专门的机制,如管道、消息队列等,这
增加了编程的难度和系统的开销。
3.2、线程并发
优点:
线程的创建和销毁开销较小,创建一个新线程就像在餐厅里多招一个服务员,相对容易且快速。线程间通信也更加方便,
因为它们共享进程的内存空间,可以直接访问共享数据,提高了通信效率。
缺点:由于线程共享资源,容易
出现线程安全问题。多个线程同时访问共享数据时,可能会导致数据不一致,就像多个服务员同时抢着为同一桌顾客服务,可能会造成混乱。
二、通过多线程实现高并发软件系统
要实现高并发的软件系统,多线程是一个关键技术。可以从以下几个方面入手:
1、任务分解
将一个大任务分解成多个小任务,每个小任务由一个线程来执行。例如,在一个 Web 服务器中,每个客户端的请求可以看作一个小任务,服务器可以为每个请求分配一个线程来处理,这样就可以同时处理多个客户端的请求,提高系统的并发处理能力。
2、线程管理
使用线程池来管理线程,避免频繁地创建和销毁线程。
线程池预先创建一定数量的线程,当有任务到来时,从线程池中取出一个空闲的线程来执行任务,任务执行完成后,线程返回线程池等待下一个任务。
这样可以减少线程创建和销毁的开销,提高系统的性能。
3、线程同步
使用同步机制来保证线程安全,避免多个线程同时访问共享数据。
常见的同步机制有互斥锁、信号量、条件变量等。例如,在多个线程同时访问一个共享变量时,可以使用互斥锁来保证同一时间只有一个线程可以访问该变量。
三、Linux 与 Windows 系统中创建线程的方式及跨平台解决方案
1、 Linux 系统
在 Linux 系统中,通常使用
POSIX 线程库(pthread)来创建线程。
以下是一个简单的示例代码:
// linux系统下
#include <pthread.h>
#include <stdio.h>
void* thread_function(void* arg) {
printf("This is a new thread.\n");
return NULL;
}
int main() {
pthread_t thread_id;
int result = pthread_create(&thread_id, NULL, thread_function, NULL);
if (result != 0) {
perror("Thread creation failed");
return 1;
}
pthread_join(thread_id, NULL);
return 0;
}2、Windows 系统
在 Windows 系统中,使用
Windows API 来创建线程。示例代码如下:
/**
* 多线程:这里是在windows系统下
*/
#include <iostream>
#include <windows.h>
#include <stdio.h>
// windows 下API 创建线程的方式
DWORD WINAPI thread_function(LPVOID lpParam) {
printf("This is a new thread. Current thread ID: %lu\n", GetCurrentThreadId());
return 0;
}
int main() {
HANDLE hThread;
DWORD threadId;
// 打印主线程 ID
printf("Main thread ID: %lu\n", GetCurrentThreadId());
// CreateThread(); 创建线程 windows 创建线程的api, 返回的是线程指针
hThread = CreateThread(NULL, 0, thread_function, NULL, 0, &threadId);
if (hThread == NULL) {
printf("Thread creation failed.\n");
return 1;
}
WaitForSingleObject(hThread, INFINITE);
CloseHandle(hThread);
return 0;
}3、跨平台解决方案
为了解决跨平台的问题,可以使用一些跨平台的多线程库,如
Boost.Thread 或 C++11 标准库中的线程库。这些库提供了统一的接口,使得开发者可以在不同的操作系统上使用相同的代码来创建和管理线程。
四、C++11 实现多线程的优势及详细介绍(推荐)
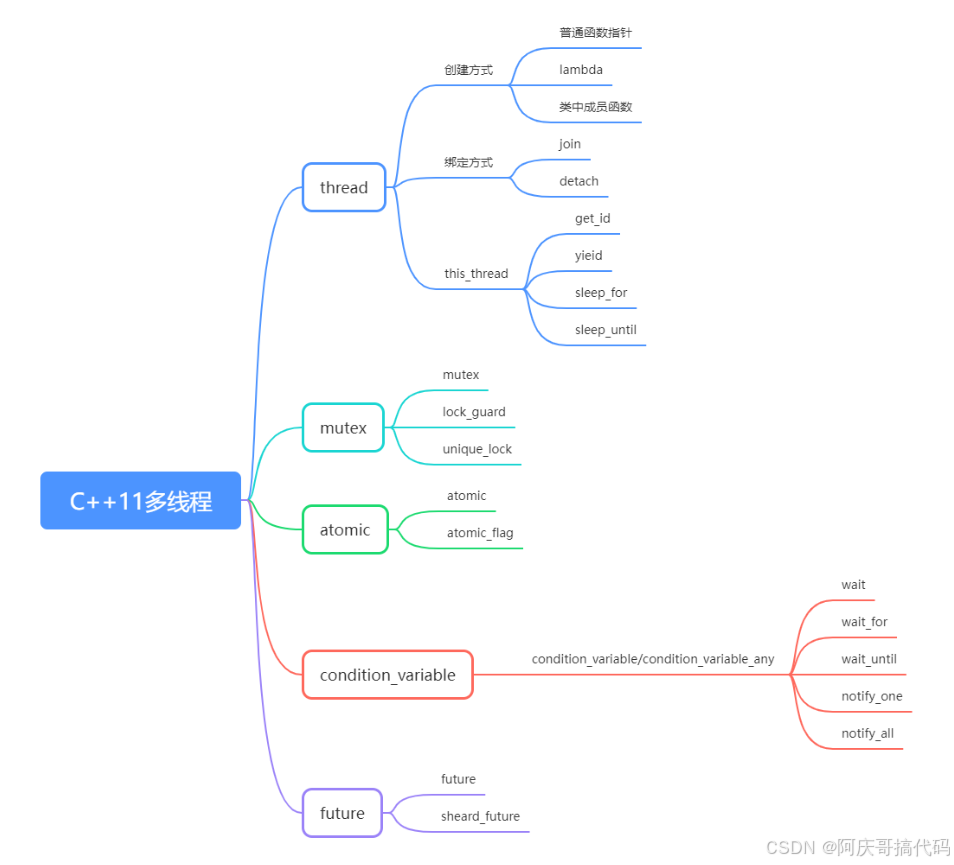
1、C++11 中创建线程的方式及优缺点
1.1、函数指针方式
#include <iostream>
#include <thread>
void func() {
std::cout << "Thread created with function pointer." << std::endl;
}
int main() {
std::thread t(func);
t.join();
return 0;
}
作用:可以方便地调用普通函数作为线程的执行体。
优点:代码简单直接,易于理解和实现。
缺点:只能调用全局函数或静态成员函数,不够灵活。
1.2、Lambda 表达式方式
#include <iostream>
#include <thread>
int main() {
std::thread t([]() {
std::cout << "Thread created with lambda expression." << std::endl;
});
t.join();
return 0;
}
作用:
可以捕获外部变量,方便实现复杂的逻辑。
优点:代码简洁,能够在创建线程时直接定义线程的执行体。
缺点:
如果捕获的变量过多,会增加代码的复杂度和内存开销。
1.3、类的成员函数方式
#include <iostream>
#include <thread>
class MyClass {
public:
void memberFunction() {
std::cout << "Thread created with member function." << std::endl;
}
};
int main() {
MyClass obj;
std::thread t(&MyClass::memberFunction, &obj);
t.join();
return 0;
}
作用:可以调用类的成员函数,方便实现面向对象的多线程编程。
优点:
可以访问类的成员变量和其他成员函数,代码结构更加清晰。
缺点:需要传递对象的指针或引用,使用起来相对复杂一些。
2、join 与 detach 模式创建线程
2.1、join 模式:任务依赖型场景
适用场景:
- 需要获取线程执行结果:例如主线程需要等待子线程完成数据计算后才能继续处理。
- 资源同步回收:避免因线程未执行完毕而导致的内存泄漏或状态不一致。
- 任务串行化依赖:子线程的执行结果是后续操作的前提条件。
#include <iostream>
#include <thread>
void func() {
std::cout << "Thread is running in join mode." << std::endl;
}
int main() {
std::thread t(func);
t.join();
std::cout << "Main thread continues after join." << std::endl;
return 0;
}
在 join 模式下,
主线程会等待子线程执行完毕后再继续执行。这种方式可以确保子线程的资源被正确释放,避免出现资源泄漏的问题。但是,如果子线程执行时间过长,会导致主线程阻塞,影响程序的响应性能。
2.2、detach 模式:独立后台任务
适用场景:
- 后台服务类任务:如日志记录、监控心跳、异步 IO 操作等。
- 无需结果的独立任务:例如定期清理缓存、发送心跳包等。
- 任务执行时间不确定:避免主线程无限期等待。
#include <iostream>
#include <thread>
void func() {
std::cout << "Thread is running in detach mode." << std::endl;
}
int main() {
std::thread t(func);
t.detach();
std::cout << "Main thread continues without waiting." << std::endl;
return 0;
}
在 detach 模式下,
子线程会在后台独立运行,主线程不会等待子线程执行完毕。这种方式可以避免主线程阻塞,提高程序的响应性能。但是,一旦子线程被 detach,就无法再与主线程进行同步,也无法获取子线程的执行结果,而且子线程的资源会在其执行完毕后自动释放,需要确保子线程不会访问已经被销毁的资源。
2.3 joinable() 的作用
`joinable()` 是 `std::thread` 类的一个成员函数,用于判断一个线程是否可以被 `join` 或 `detach`。
如果一个线程对象还没有被 `join` 或 `detach`,则 `joinable()` 返回 `true`;否则返回 `false`。例如:
#include <iostream>
#include <thread>
void func() {
std::cout << "Thread is running." << std::endl;
}
int main() {
std::thread t(func);
if (t.joinable()) {
t.join();
}
return 0;
}3、this_thread 类的常见用法
|
函数
|
用法
|
说明
|
| get_id() |
std::this_thread::get_id()
|
获取当前线程Id
|
| yield() |
std::this_thread::yieid()
|
放弃线程执行,回到就绪状态
|
| sleep_for() |
std::this_thread::sleep_for(std::chrono::seconds(1));
|
暂停1秒
|
| sleep_until() |
this_thread::sleep_until(system_clock::from_time_t(mktime(ptm)));
|
到什么时间后执行
|
3.1、get_id()
#include <iostream>
#include <thread>
void func() {
std::cout << "Thread ID: " << std::this_thread::get_id() << std::endl;
}
int main() {
std::thread t(func);
std::cout << "Main thread ID: " << std::this_thread::get_id() << std::endl;
t.join();
return 0;
}
功能:获取当前线程的唯一标识符。
使用场景:
在调试或日志记录中,用于区分不同的线程。
3.2、yield()
#include <iostream>
#include <thread>
void func() {
for (int i = 0; i < 5; ++i) {
std::this_thread::yield();
std::cout << "Thread is working: " << i << std::endl;
}
}
int main() {
std::thread t(func);
t.join();
return 0;
}
功能:
当前线程放弃执行,让操作系统调度其他线程执行。
使用场景:当线程暂时没有紧急任务时,主动让出 CPU 资源,提高系统的整体性能。
3.3、sleep_for()
#include <iostream>
#include <thread>
#include <chrono>
void func() {
std::this_thread::sleep_for(std::chrono::seconds(2));
std::cout << "Thread woke up after 2 seconds." << std::endl;
}
int main() {
std::thread t(func);
t.join();
return 0;
}
功能:让当前线程休眠指定的时间。
使用场景:在需要延迟执行或模拟耗时操作时使用。
4、 mutex 类的介绍及线程间数据安全
4.1、常见加锁方式
std::mutex
#include <iostream>
#include <thread>
#include <mutex>
std::mutex mtx;
int shared_data = 0;
void increment() {
for (int i = 0; i < 100; ++i) {
mtx.lock();
++shared_data;
printf("shared_data:%d\n", shared_data);
mtx.unlock();
}
}
int main() {
std::thread t1(increment);
std::thread t2(increment);
t1.join();
t2.join();
std::cout << "Shared data: " << shared_data << std::endl;
return 0;
}std::lock_guard
#include <iostream>
#include <thread>
#include <mutex>
std::mutex mtx;
int shared_data = 0;
void increment() {
for (int i = 0; i < 10; ++i) {
std::lock_guard<std::mutex> lock(mtx);
++shared_data;
// 获取当前线程Id;
printf("lock_guard id:%d -> shared_data:%d\n",std::this_thread::get_id(), shared_data);
}
}
int main() {
std::thread t1(increment);
std::thread t2(increment);
t1.join();
t2.join();
std::cout << "Shared data: " << shared_data << std::endl;
return 0;
}线程间数据安全
mutex 类用于保护共享数据,
确保同一时间只有一个线程可以访问共享数据。通过加锁和解锁操作,避免了多个线程同时修改共享数据导致的数据不一致问题。std::lock_guard
是一个 RAII(资源获取即初始化)类,它在构造时自动加锁,在析构时自动解锁,避免了手动加锁和解锁可能导致的忘记解锁问题,提高了代码的安全性。
5、atomic 的常见用法
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<int> atomic_data(0);
void atomic_increment() {
for (int i = 0; i < 20; ++i) {
++atomic_data;
printf("atomic id:%d -> shared_data:",std::this_thread::get_id());
std::cout << atomic_data <<std::endl;
}
}
int main() {
std::thread t1(atomic_increment);
std::thread t2(atomic_increment);
t1.join();
t2.join();
std::cout << "Atomic data: " << atomic_data << std::endl;
return 0;
}
`std::atomic` 类
提供了原子操作,保证对共享数据的操作是原子的,避免了线程安全问题。原子操作是不可分割的,不会被其他线程打断。在多线程环境中,对一些简单的数据(如计数器)进行并发访问时,使用 `std::atomic` 可以避免使用互斥锁带来的性能开销。
6、condition_variable 头文件中的常见用法
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
std::mutex mtx;
std::condition_variable cv;
bool ready = false;
void worker() {
std::unique_lock<std::mutex> lock(mtx);
std::cout << "thread Id:"<< std::this_thread::get_id() << " Worker thread enter." << std::endl;
cv.wait(lock, [] { return ready; });
std::cout << "thread Id:"<< std::this_thread::get_id() << " Worker thread is working." << std::endl;
}
int main() {
std::thread t(worker);
t.detach();
{
std::lock_guard<std::mutex> lock(mtx);
ready = true;
std::cout << "Main thread Id:"<< std::this_thread::get_id() << " state changed:" << ready << std::endl;
}
cv.notify_all();
//
std::cout << "condition_variable Main thread working" <<std::endl;
return 0;
}
`std::condition_variable` 用于线程间的同步,
一个线程可以等待某个条件满足,另一个线程可以在条件满足时通知等待的线程。在生产者 - 消费者模型中,消费者线程可以等待生产者线程生产出数据后再进行消费,通过 `std::condition_variable` 可以实现这种同步机制。
7、 future 的常见用法及使用场景
#include <iostream>
#include <thread>
#include <future>
int calculate() {
std::this_thread::sleep_for(std::chrono::seconds(2));
return 42;
}
int main() {
std::future<int> result = std::async(calculate);
std::cout << "Waiting for the result..." << std::endl;
std::cout << "Result: " << result.get() << std::endl;
return 0;
}
`std::future` 用于获取异步操作的结果。
`std::async` 可以启动一个异步任务,并返回一个 `std::future` 对象,通过 `get()` 方法可以获取任务的返回值。在需要进行耗时操作时,使用 `std::async` 可以让操作在另一个线程中异步执行,主线程可以继续执行其他任务,提高程序的响应性能。当需要获取耗时操作的结果时,再调用 `get()` 方法等待结果返回。
五、线程池:概念、背景及解决的问题
1、线程池的定义
线程池就像是一个员工储备库,预先创建一定数量的线程,当有任务到来时,从线程池中取出一个空闲的线程来执行任务,任务执行完成后,线程返回线程池等待下一个任务。
2、线程池出现的背景
在传统的多线程编程中,
每次有任务到来时都创建一个新的线程,任务执行完成后销毁线程。这种方式会带来很大的开销,尤其是在高并发的情况下,频繁的线程创建和销毁会消耗大量的系统资源,降低系统的性能。
3、 线程池解决的问题
线程池通过预先创建线程,避免了频繁的线程创建和销毁,减少了系统开销。同时,
线程池可以对线程进行统一的管理,控制线程的数量,避免了线程过多导致的系统资源耗尽问题。
六、线程池的应用实例及使用场景介绍
1、应用实例
#include <iostream>
#include <vector>
#include <queue>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <functional>
#include <future>
class ThreadPool
{
public:
ThreadPool(size_t numThreads) : m_stop(false)
{
for (size_t i = 0; i < numThreads; ++i)
{
// 创建线程
m_vecWorkers.emplace_back(
[this, i] {
while (true)
{
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(this->m_queueMutex);
// 任务队列不为空
this->m_condition.wait(lock, [this] { return this->m_stop || !this->m_queTasks.empty(); });
if (this->m_stop && this->m_queTasks.empty())
{
std::cout << "thread Id:"<< std::this_thread::get_id() << " 线程运行停止并且任务结束" <<std::endl;
return;
}
task = std::move(this->m_queTasks.front());
this->m_queTasks.pop();
}
task();
}
}
);
}
}
~ThreadPool()
{
{
std::unique_lock<std::mutex> lock(m_queueMutex);
std::cout << "thread Id:"<< std::this_thread::get_id() << " ThreadPool 析构" << std::endl;
m_stop = true;
}
m_condition.notify_all();
for (std::thread& worker : m_vecWorkers)
{
// std::cout << "thread Id:"<< std::this_thread::get_id() << "child thead join" << std::endl;
worker.join();
}
}
template<class F, class... Args>
auto enqueue(F&& f, Args&&... args) -> std::future<typename std::result_of<F(Args...)>::type>
{
using return_type = typename std::result_of<F(Args...)>::type;
auto task = std::make_shared< std::packaged_task<return_type()>>(std::bind(std::forward<F>(f), std::forward<Args>(args)...));
std::future<return_type> res = task->get_future();
{
std::unique_lock<std::mutex> lock(m_queueMutex);
if (m_stop)
{
throw std::runtime_error("enqueue on stopped ThreadPool");
}
// 队列尾部增加一个函数
m_queTasks.emplace([task]() { (*task)(); });
}
m_condition.notify_one();
return res;
}
private:
std::vector<std::thread> m_vecWorkers;
// std::function 是 C++ 标准库 <functional> 头文件中提供的一个通用的多态函数包装器
std::queue<std::function<void()>> m_queTasks;
std::mutex m_queueMutex;
std::condition_variable m_condition;
bool m_stop;
};
// 使用示例
void exampleTask(int id) {
std::cout << "thread Id:"<< std::this_thread::get_id() << " Task " << id << " is running." << std::endl;
}
int main() {
ThreadPool pool(4);
std::vector< std::future<void> > futures;
for (int i = 0; i < 8; ++i) {
futures.emplace_back(
pool.enqueue(exampleTask, i)
);
}
for (auto& future : futures) {
future.wait();
}
return 0;
}2、使用场景
Web 服务器:
处理大量的客户端请求,每个请求可以由线程池中的一个线程来处理,提高服务器的并发处理能力。
数据库服务器:
并发地处理多个查询请求,减少用户的等待时间。
多媒体处理:如视频编码、音频处理等,
将不同的处理任务分配给线程池中的线程,提高处理效率。
七、总结
多线程编程是一门复杂而又强大的技术,
它能够让程序充分发挥多核处理器的优势,提高程序的性能和响应速度。通过合理地使用线程和线程池,以及掌握 C++11 提供的多线程工具,开发者可以编写出高效、稳定的多线程程序。


















 2387
2387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









