






L3-图论-第03课 拓扑排序
有向无环图 (DAG) 和 拓扑排序
定义
如果一个有向图不存在环,也就是任意结点都无法通过一些有向边回到自身,那么称这个有向图为有向无环图。英文名叫 Directed Acyclic Graph,缩写是 DAG。
对一个有向无环图 G 进行拓扑排序,是将 G 中所有顶点排成一个线性序列,使得图中任意一对顶点 u 和 v ,若边 ∈ E(G),则 u 在线性序列中出现在 v 之前。通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称拓扑序列。简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序。
性质
- 能拓扑排序的图,一定是有向无环图;
如果有环,那么环上的任意两个节点在任意序列中都不满足条件了。
- 有向无环图,一定能拓扑排序;
如何判定一个图是否是有向无环图呢?
检验它是否可以进行 拓扑排序 即可。
用途
拓扑排序有何作用?
拓扑排序主要用来解决有向图中的依赖解析(dependency resolution)问题。
游戏升级的先后顺序也是一个拓扑序.
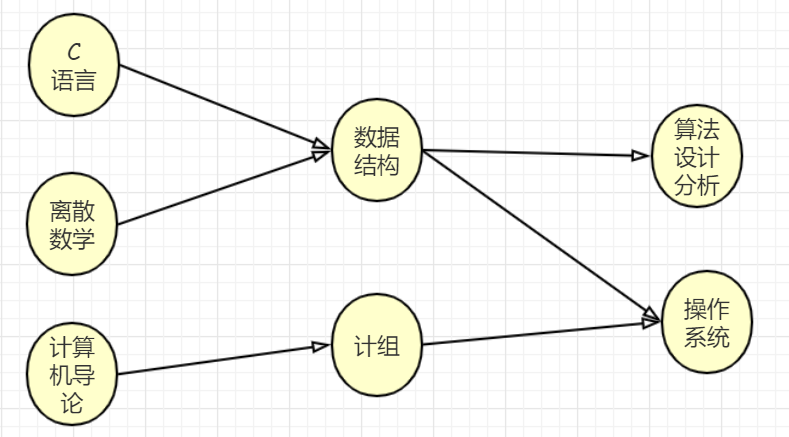
用计算机专业的几门课程的学习次序来描述拓扑关系 ,显然对于一门课来说,必须先学习它的先导课程才能更好地学习这门课程,比如学数据结构必须先学习C语言和离散数学,而且先导课程中不能有环,否则没有尽头了

拓扑排序的结果不唯一,比如“C语言”和“离散数学”就可以换下顺序,又或者把“计算机导论”向前放在任何一个位置都可以。总结一下就是,如果某一门课没有先导课程或是所有的先导课程都已经学习完毕,那么这门课就可以学习了。
算法描述
对于一个有向无环图
- 初始化一个 int[] inDegree 保存每一个结点的入度。
- 对于图中的每一个结点的子结点,将其子结点的入度加1。
- 选取入度为 0 的结点开始遍历,并将该节点加入输出。
- 对于遍历过的每个结点,更新其子结点的入度:将子结点的入度减1。
- 重复步骤3,直到遍历完所有的结点。
- 如果无法遍历完所有的结点,则意味着当前的图不是有向无环图。不存在拓扑排序。
解释一下,假设A为一个入度为0的结点,就表示A结点没有前驱结点,可以直接做,把A完成后,对于A的所有后继结点来说,前驱结点就完成了一个,入度进行−1。
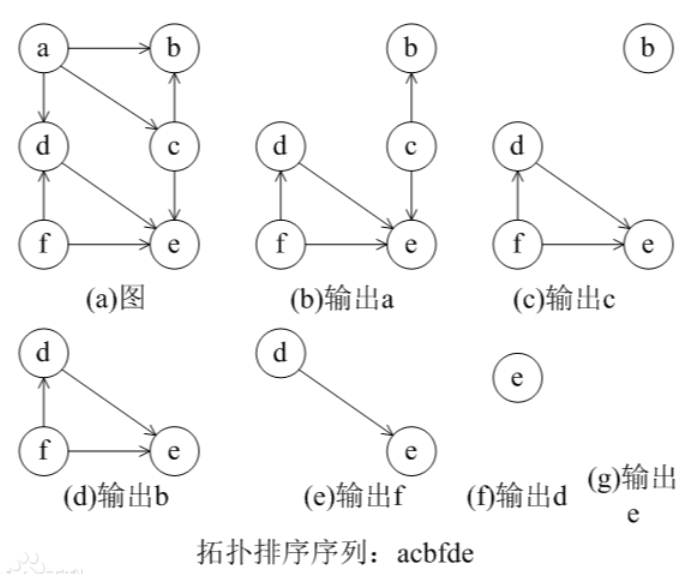
时间复杂度
如果 DAG 网络有 n 个顶点,m 条边,在拓扑排序的过程中,搜索入度为零的顶点所需的时间是 O(n)。在正常情况下,每个顶点进一次队列,出一次队列,所需时间 O(n)。每个顶点入度减 1 的运算共执行了 m 次。所以总的时间复杂为 O(n+m)。
因为拓扑排序的结果不唯一,所以题目一般会要求按某种顺序输出,就需要使用优先级队列,这里采取了最小字典序输出。
模板
void tpsort() {
queue q;for (int i = 1; i <= n; i++) {if (!in[i]) {
q.push(i);
}
}while (!q.empty()) {
int u = q.front();
q.pop();
ans[++idx] = u;for (int i = hd[u]; i ; i = e[i].nxt) {
int to = e[i].to;in[to]--;if (!in[to])
q.push(to);
}
}
}DFS 拓扑排序
#include
using namespace std;
const int maxn = 1000 + 10;
const int INF = 1e9 + 7;
int T, n, m, cases;
vector<int>Map[maxn];
// 标记数组c[i] = 0 表示还未访问过点
// c[i] = 1表示已经访问过点i,并且还递归访问过它的所有子孙?
// c[i] = -1表示正在访问中,尚未返回
int c[maxn];
int topo[maxn], t;
bool dfs(int u)//从u出发{
c[u] = -1;//访问标志
for(int i = 0; i {
int v = Map[u][i];
//如果子孙比父亲先访问,说明存在有向环,失败退出
if(c[v] 0)return false;
else if(!c[v] && !dfs(v))
return false;
//如果子孙未被访问,访问子孙返回假,说明也是失败
}
c[u] = 1;
topo[--t] = u;
//在递归结束才加入topo排序中?
// 这是由于在最深层次递归中,已经访问到了尽头,
//此时才是拓扑排序中的最后一个元素
return true;
}
bool tpsort(){
t = n;
memset(c, 0, sizeof(c));
for(int u = 1; u <= n; u++)if(!c[u])
if(!dfs(u))return false;
return true;
}
int main(){
while(cin >> n >> m)
{
if(!n && !m)break;
int u, v;
for(int i = 0; i <= n; i++)Map[i].clear();
for(int i = 0; i {
cin >> u >> v;
Map[u].push_back(v);
}
if(tpsort())
{
cout<<"Great! There is not cycle."<<endl;
for(int i = 0; i cout<" ";cout<<endl;
}else cout<<"Network has a cycle!"<<endl;
}return 0;
}拓扑排序 + 字典序
U107394 拓扑排序模板
题目描述
有向无环图上有n个点,m条边。求这张图字典序最小的拓扑排序的结果。字典序最小指希望排好序的结果中,比较靠前的数字尽可能小。
输入格式
第一行是用空格隔开的两个整数n和m,表示n个点和m条边。
接下来是m行,每行用空格隔开的两个数u和v,表示有一条从u到v的边。
输出格式
输出一行,拓扑排序的结果,数字之间用空格隔开
输入输出样例
- 输入 #1复制
5 3
1 2
2 4
4 3
- 输出 #1复制
1 2 4 3 5
说明/提示
模板代码
#include
#include
#include
#include
using namespace std;
const int N = 1e5 + 6;
int n, m, ecnt;
struct Edge
{
int to, nxt;
} e[N];
int hd[N], in[N], ans[N], idx;
void add(int u, int v){
e[++ecnt].to = v;
e[ecnt].nxt = hd[u];
hd[u] = ecnt;
}
void tpsort() {
priority_queue<int, vector<int>, greater<int> > q;
for (int i = 1; i <= n; i++) {
if (!in[i]) {
q.push(i);
}
}
while (!q.empty()) {
int u = q.top();
q.pop();
ans[++idx] = u;
for (int i = hd[u]; i ; i = e[i].nxt) {
int to = e[i].to;
in[to]--;
if (!in[to])
q.push(to);
}
}
}
int main(){
scanf("%d %d", &n, &m);
for (int i = 0; i int u, v;
scanf("%d%d", &u, &v);
add(u, v);
in[v]++;
}
tpsort();
for(int i = 1; i <= idx; i++)
printf("%d ", ans[i]);
return 0;
}
拓扑排序 + 动规
P4017 最大食物链计数
题目背景
你知道食物链吗?Delia 生物考试的时候,数食物链条数的题目全都错了,因为她总是重复数了几条或漏掉了几条。于是她来就来求助你,然而你也不会啊!写一个程序来帮帮她吧。
题目描述
给你一个食物网,你要求出这个食物网中最大食物链的数量。
(这里的“最大食物链”,指的是生物学意义上的食物链,即最左端是不会捕食其他生物的生产者,最右端是不会被其他生物捕食的消费者。)
Delia 非常急,所以你只有 11 秒的时间。
由于这个结果可能过大,你只需要输出总数模上 80112002 的结果。
输入格式
第一行,两个正整数 n、m,表示生物种类 n 和吃与被吃的关系数 m。
接下来 m 行,每行两个正整数,表示被吃的生物 A 和吃 A 的生物 B。
输出格式
一行一个整数,为最大食物链数量模上 80112002 的结果。
输入输出样例
- 输入 #1复制
5 7
1 2
1 3
2 3
3 5
2 5
4 5
3 4
- 输出 #1复制
5
说明/提示
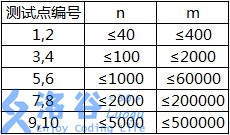
各测试点满足以下约定:
参考代码
#include
using namespace std;
const int MOD = 80112002;
const int N = 5002;
int a, b, n, m, ecnt;
int hd[N], in[N], out[N], f[N], ans;
struct Edge {
int to, nxt;
} e[5000002];
void add(int u, int v){
e[++ecnt].to = v;
e[ecnt].nxt = hd[u];
hd[u] = ecnt;
}
void tpsort(){
queue<int> q;
for(int i = 1; i <= n; i++) {
if(in[i] == 0) {
f[i] = 1;
q.push(i);
}
}
while(!q.empty()) {
int a = q.front();
q.pop();
for(int i = hd[a]; i; i = e[i].nxt){
int b = e[i].to;
f[b] += f[a];
f[b] %= MOD;
in[b]--;
if(in[b] == 0) {
if(out[b] == 0){
ans += f[b];
ans %= MOD;
}
else q.push(b);
}
}
}
}
int main(){
int i;
scanf("%d %d", &n, &m);
for(i = 1; i <= m; i++) {
scanf("%d %d", &a, &b);
add(a, b);
out[a]++;
in[b]++;
}
tpsort();
printf("%d\n", ans);
}
拓扑排序 + 数学
P7113 排水系统
题目描述
对于一个城市来说,排水系统是极其重要的一个部分。
有一天,小 C 拿到了某座城市排水系统的设计图。排水系统由 n 个排水结点(它们从 编号)和若干个单向排水管道构成。每一个排水结点有若干个管道用于汇集其他排水结点的污水(简称为该结点的汇集管道),也有若干个管道向其他的排水结点排出污水(简称为该结点的排出管道)。
排水系统的结点中有 m 个污水接收口,它们的编号分别为 ,污水只能从这些接收口流入排水系统,并且这些结点没有汇集管道。排水系统中还有若干个最终排水口,它们将污水运送到污水处理厂,没有排出管道的结点便可视为一个最终排水口。
现在各个污水接收口分别都接收了 1 吨污水,污水进入每个结点后,会均等地从当前结点的每一个排出管道流向其他排水结点,而最终排水口将把污水排出系统。
现在小 C 想知道,在该城市的排水系统中,每个最终排水口会排出多少污水。该城市的排水系统设计科学,管道不会形成回路,即不会发生污水形成环流的情况。
输入格式
第一个两个用单个空格分隔的整数 n, m。分别表示排水结点数与接收口数量。
接下来 n 行,第 i 行用于描述结点 i 的所有排出管道。其中每行第一个整数 表示其排出管道的数量,接下来 个用单个空格分隔的整数 依次表示管道的目标排水结点。
保证不会出现两条起始结点与目标结点均相同的管道。
输出格式
输出若干行,按照编号从小到大的顺序,给出每个最终排水口排出的污水体积。其中体积使用分数形式进行输出,即每行输出两个用单个空格分隔的整数 p,q,表示排出的污水体积为 。要求 p 与 q 互素,q = 1q=1 时也需要输出 qq。
输入输出样例
- 输入 #1复制
5 1
3 2 3 5
2 4 5
2 5 4
0
0
- 输出 #1复制
1 3
2 3
【样例 #1 解释】
1 号结点是接收口,4, 5 号结点没有排出管道,因此是最终排水口。
1 吨污水流入 1 号结点后,均等地流向 2,3,5 号结点,三个结点各流入 吨污水。2 号结点流入的 吨污水将均等地流向 4,5 号结点,两结点各流入 吨污水。3 号结点流入的 吨污水将均等地流向 4,5 号结点,两结点各流入 吨污水。最终,4 号结点排出 吨污水 5 号结点排出 \frac{1}{3} + \frac{1}{6} + \frac{1}{6} = \frac{2}{3} 吨污水。
【数据范围】
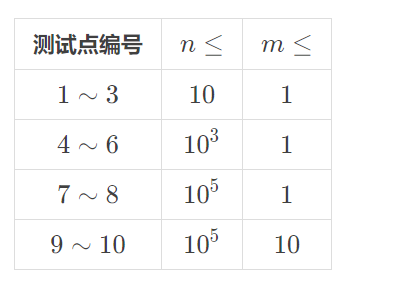
对于全部的测试点,保证 ,,
数据保证,污水在从一个接收口流向一个最终排水口的过程中,不会经过超过 1010 个中间排水结点(即接收口和最终排水口不算在内)。
分析
- 深搜, 从每个入口点开始, 计算流过的每个结点所能分配到的水量, 最后在出口处累加.
- 拓扑排序, 从头开始, 按层次依次计算每个结点所能得到的水量, 直到最终出水口
参考代码
#include
using namespace std;
#define ll __int128
const int N = 1e5 + 5, M = 5e5 + 5;
int n, m;
ll gcd(ll a, ll b){
return b == 0 ? a : gcd(b, a % b);
}
ll lcm(ll a, ll b){
return a / gcd(a, b) * b;
}
struct Node {
ll p, q;
Node(ll p1 = 0, ll q1 = 1) {
p = p1;
q = q1;
}
Node operator * (const Node &x) const {
Node res;
res.p = p * x.p;
res.q = q * x.q;
ll g = gcd(res.p, res.q);
res.p /= g, res.q /= g;
return res;
}
Node operator + (const Node &x) const {
Node res;
res.q = lcm(q, x.q);
res.p += p * (res.q / q);
res.p += x.p * (res.q / x.q);
ll g = gcd(res.p, res.q);
res.p /= g, res.q /= g;
return res;
}
} val[N];
struct Edge {
int to, nxt;
} e[M];
int hd[N], ecnt, in[N], out[N], ans[N], idx;
void add(int from, int to) {
e[++ecnt].to = to;
e[ecnt].nxt = hd[from];
hd[from] = ecnt;
}
void tpsort(){
queue<int> q;
for (int i = 1; i <= m; i++)
if (in[i] == 0)
q.push(i);
while(!q.empty()) {
int u = q.front();
q.pop();
Node uout = Node(1, out[u]);
uout = uout * val[u];
for (int i = hd[u]; i; i = e[i].nxt) {
int to = e[i].to;
val[to] = val[to] + uout;
in[to]--;
if (in[to] == 0)
q.push(to);
}
}
}
void print(ll n) {
if(n > 9)
print(n / 10);
putchar(n % 10 + '0');
}
void printval(Node &x){
print(x.p);
putchar(' ');
print(x.q);
putchar('\n');
}
int main(void) {
scanf("%d %d", &n, &m);
for (int i = 1; i <= n; i++) {
if (i <= m)
val[i].p = 1;
scanf("%d", &out[i]);
if (out[i] == 0)
ans[++idx] = i;
for (int j = 1; j <= out[i]; j++) {
int to;
scanf("%d", &to);
add(i, to);
in[to]++;
}
}
tpsort();
for (int i = 1; i<= idx; i++) {
printval(val[ans[i]]);
}
return 0;
}
题单 拓扑排序 + 各种算法
- U107394 拓扑排序模板
- P1113 杂务
- P1983 车站分级
- P1347 排序
- P1807 最长路
- P4017 最大食物链计数
- P7077 函数调用
- P7113 排水系统
云帆编程老师联系方式:
云帆老师
微信:














 669
669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









