







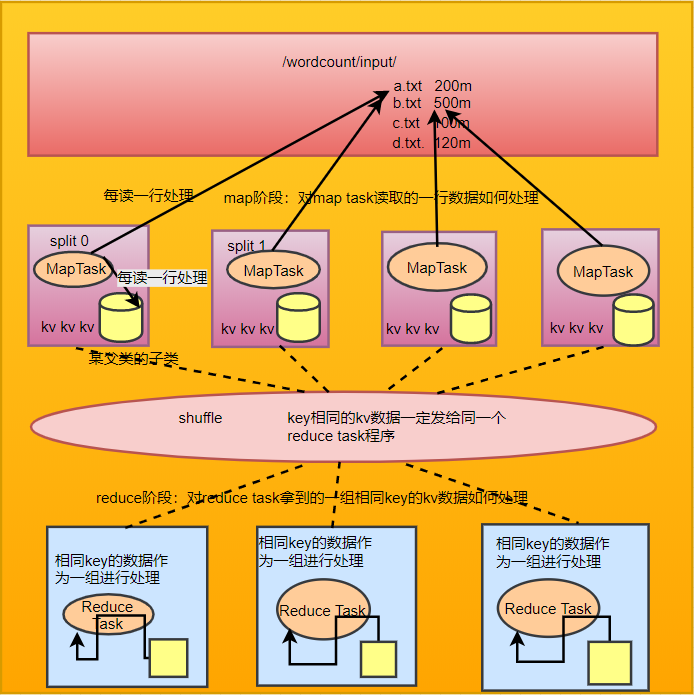
 wordcount示例开发map阶段:将每行文本数据变成这样的k,v数据reduce阶段:将相同单词的一组kv数据进行聚合,累加所有的v注意事项mapreduce程序中:map阶段的进,出数据reduce阶段的进,出数据类型都应该是实现了Hadoop序列化框架类型比如:String对应Text;Integer对应IntWritable;Long对应LongWritablewordcount程序整体...
wordcount示例开发map阶段:将每行文本数据变成这样的k,v数据reduce阶段:将相同单词的一组kv数据进行聚合,累加所有的v注意事项mapreduce程序中:map阶段的进,出数据reduce阶段的进,出数据类型都应该是实现了Hadoop序列化框架类型比如:String对应Text;Integer对应IntWritable;Long对应LongWritablewordcount程序整体...
wordcount示例开发
map阶段:将每行文本数据变成这样的k,v数据
reduce阶段:将相同单词的一组kv数据进行聚合,累加所有的v
注意事项
mapreduce程序中:
map阶段的进,出数据
reduce阶段的进,出数据
类型都应该是实现了Hadoop序列化框架类型
比如:String对应Text;Integer对应IntWritable;Long对应LongWritable
wordcount程序整体运行流程示意图
1.yarn的基本概念
yarn是一个分布式程序的运行调度平台
yarn中有两大核心角色:
1、Resource Manager
接受用户提交的分布式计算程序,并为其划分资源
管理、监控各个Node Manager上的资源情况,以便于均衡负载
2、Node Manager
管理它所在机器的运算资源(cpu + 内存)
负责接受Resource Manager分配的任务,创建容器、回收资源
2.YARN的安装
node manager在物理上应该跟data node部署在一起
resource manager在物理上应该独立部署在一台专门的机器上
2.1修改配置文件
cd /root/apps/hadoop-2.7.2/etc/hadoop
vi yarn-site.xml
在里面添加
yarn.resourcemanager.hostname
hdp-01
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.resource.memory-mb
2048
yarn.nodemanager.resource.cpu-vcores
2
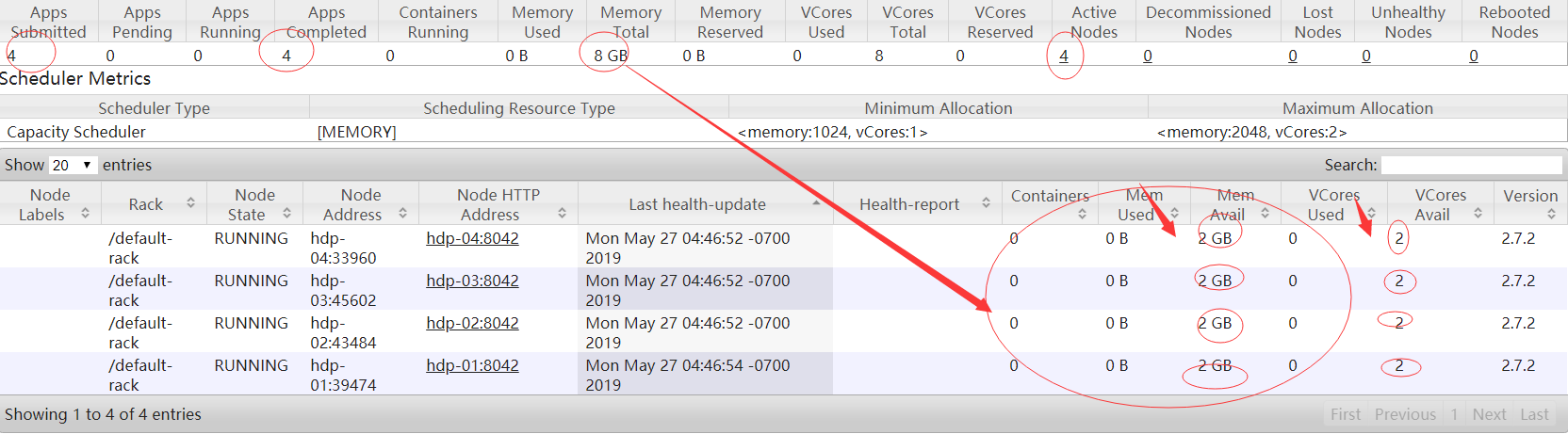
2.2拷贝配置文件到其它节点上
scp yarn-site.xml hdp-02:$PWD
scp yarn-site.xml hdp-03:$PWD
scp yarn-site.xml hdp-04:$PWD
3.启动和停止hdfs集群和yarn集群命令
1.hdfs:
stop-dfs.sh:停止配置的namenode datanode
start-dfs.sh:启动namenode datanode
2.yarn:
start-yarn.sh:启动resourcemanager和nodemanager(注:该命令应该在resourcemanager所在的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2910
2910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









