







代码:https://github.com/bojone/KgCLUE-bert4keras
模型图:seq2seq
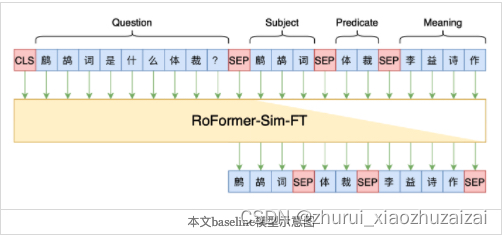
RoFormer-Sim-FT模型,它是利用UniLM模型预训练过的相似问生成模型,
经过对比,用RoFormer-Sim-FT相比直接用RoFormer,效果至少提升2个百分点。
这也说明相似问生成是该方案的一种有效的预训练方式。
1、开始用RoFormer+UniLM按照(S,M,P)顺序预测,验证集EM大约是70多;
2、然后改为(S,P,M)的顺序之后,验证集能做到82了;
3、接着预训练模型换用RoFormer-Sim-FT后,提升到84~85;
4、最后加上“前瞻”策略,就做到当前的89了。
前瞻策略
在“Seq2Seq+前缀树”方案中,生成了S之后,后续容许的P不会太多,所以可以直接逐一枚举容许的P,通过P对问题的覆盖程度,来调整当前token的预测结果。
具体的步骤是:
假设当前问题Q已经解码出S,以及P的前t−1个字符P<t,现在要预测P的第t个字Pt,
那么我们根据S,P<t检索出所有可能的P(1),P(2),⋯,P(n),每个P(k)可以表示为[P<t,P<t(k),P>t(k)]的格式;然后我们用一个覆盖度函数,这里直接用最长公共子序列长度LCS,来算出每个候选的P所能带来的覆盖度增益:
Δ(k)=LCS(P(k),Q)−LCS(P<t,Q)
该增益视为将Pt预测为P(k)t的“潜在收益”,如果多个P<t(k)对应同一个字,那么就取最大者。
这样,对于Pt的所有候选值k,我们都计算出来了一个“潜在收益”Δ(k),我们可以调整Seq2Seq的预测概率,来强化一下Δ(k)的token。笔者用的强化规则为:
pk←pk1/(Δ(k)+1)
也就是如果潜在收益是Δ(k),那么对应的概率就开Δ(k)+1次方,然后重新归一化,由于概率是小于1的,所以开方起到了放大的作用。该策略带来的收益,大概是4个百分点的提升。其他强化规则也可以尝试,这部分主观性比较强,就不一一列举了。
错例分析
观察bad case的时候,发现模型有可能会出现一些非常“简单”的bad case,
比如“海浦东香格里拉大酒店离火车站有多远?”,正确的(S,P)应该是“(上海浦东香格里拉大酒店, 火车站距离)”,但模型却生成了“(上海浦东香格里拉大酒店, 酒店星级)”;
有时候问“XXX讨厌什么”,结果模型却生成了“(XXX, 喜欢)”;
有时候问“XXX主要讲什么课程”,正确的答案应该是“(XXX, 主讲课程)”,结果模型却生成了“(XXX, 主要成就)”。
也就是说,模型似乎会在一些字面上看起来非常简单的问题上犯错(生成错误的P)。
经过思考,笔者认为这种bad case本质上是Seq2Seq本身的固有缺点所导致的,主要包含两方面:
1、训练时的Exposure Bias问题;
2、解码时Beam Search的贪心问题。
首先,由于Seq2Seq在训练时是已知上一真实标签的,这会弱化训练难度,导致模型的“全局观”不够;
其次,解码哪怕用了Beam Search,本质上也是贪心的,很难做到综合后几个token来预测当前token。
比如刚才的“XXX主要讲什么课程”一例,模型生成P的时候,首先就很贪心地生成“主要”两个字,然后按照前缀树的约束,“主要”后面只能接“成就”了(因为“主讲课程”前两个字是“主讲”),所以就出来了“主要成就”。
理论上,应用一些缓解Seq2Seq的Exposure Bias问题的策略,比如《Seq2Seq中Exposure Bias现象的浅析与对策》、《TeaForN:让Teacher Forcing更有“远见”一些》等,应该是对此问题有帮助的。这些方法比较多,复杂度也有所不一样,就留给读者自行尝试了。














 227
227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









