







来自模型训练的方式:
unlikelihood training:
straight to gradient:方案4:
另外,针对<HJIKL, HJIKLL, HJIKLL…>的分布几乎相同的各向异性,就是L的分布与前面t-1词的分布趋同,可以认为是L这个词的input embedding并没有学好!最简单的解决方式,先在通用数据上大批量跑出来哪些词时容易重复的,再对他们组成的词汇单独的pre训练,强行改变他们的分布,也能在不降低生成质量的情况下,大幅度改善重复的问题。方案5:
还有一个很trick的方法,也就是对容易出现重复生成的文本,做对应词语L的缺词文本构造,生成多个扩充文本放到训练集里训练。这个无论是在翻译、QA还是对话里都比较有效,毕竟数据为王嘛,就是让模型对semi-distinctive的样本多多学习下。方案6:
分析指出,Self-reinforcement effect 是重复的核心问题。我们进一步提出了DITTO, 一种非常的简单的方法,在训练阶段纠正模型分布的方法来解决重复问题。 实验证明在generation的各种decoding 算法[greedy, top-p, top-k] 以及 abstractive summarization 任务上都有显著提高。
https://arxiv.org/abs/2206.02369
来自解码decode的方式:
方案1:
这种问题首先可以通过Beam search或者Random search缓解,比如在LLAMA和NLLB的原始Transformers代码中,beam search是默认为false,如果打开并将seeds设置为2,那整体的重复生成情况能减少到原来的40%;方案2:
对比搜索的方式 contrastive sampling [1,2] ,据说是能够达到与人类匹配的水平。方案3:
另一种比较实际的操作,这个其实是从predict softmax分布上发现的,一个词重复生成,也就是说下一个位置它的概率值依然是最大的,那么你可以先对前面的句子做n-gram的重复检测,对出现重复的词在next prediction时做mask,强行控制模型不选前面t-n~t-1出现的重复词时,重复性大大减少,翻译的准确率也会明显提升!就是这么简单粗暴,其实原理也类似于Reward,强制模型朝着信息熵高的方向来生成。
origin MLE:
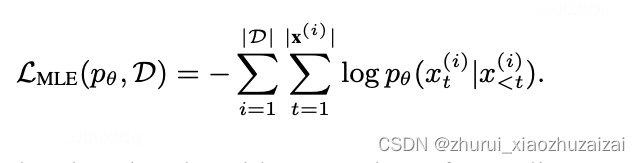
来自模型训练的方式
1 Unlikelihood Training
Unlikelihood training方法通过在训练中加入对重复词的抑制来减少重复输出[3],
具体来说:下式中集合C代表上文生成的token,本身l
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1156
1156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









