







 本文围绕降低Transformer模型计算量展开,介绍了稀疏Attention、线性化Attention、分块计算、简化attention等优化方法,如OpenAI的Sparse Attention、Reformer、Linformer等。还提及Transformer - VQ,通过对Attention的Key向量序列聚类使复杂度线性化,实验结果优异。
本文围绕降低Transformer模型计算量展开,介绍了稀疏Attention、线性化Attention、分块计算、简化attention等优化方法,如OpenAI的Sparse Attention、Reformer、Linformer等。还提及Transformer - VQ,通过对Attention的Key向量序列聚类使复杂度线性化,实验结果优异。
0 说在开头,线性attention的必要性
Attention和FFN的复杂度:对于base版来说,当序列长度不超过1536时,Transformer的复杂度都是近乎线性的;
当序列长度超过1536时,Transformer的计算量逐渐以Attention为主,复杂度慢慢趋于二次方,直到长度超过4608,才真正以二次项为主
从已有的各个高效Attention的工作中,我们可以得出结论:这些改进工作所关心的序列长度主要都是以千为单位的,有明显计算效率提升的序列长度基本上都要好几千;当然,我们前面的讨论主要针对的还是时间复杂度,对于空间复杂度,也就是显存占用量,降低的幅度一般要比时间复杂度提升的幅度的要大,但总体而言都是长序列才有价值。
所以,如果你的序列长度还只是一两百,那么就完全不要期望Attention本身的改进了,老老实实换个小点的模型就好。你可以期望未来会有更小的模型能达到同样好的效果,但是不要期望同样大的模型通过修改Attention来提升效率,因为说白了,就算把Attention完全去掉,也提升不了多少性能。
稀疏attention:sprse, reformer, linformer, Nvidia-StarAttention, 月之暗面MoBA , native sparse attention(NSA)
线性化attention:去softmax/performer近似QK,Transformer-VQ
分块计算:MQA(Multi-Query Attention)、 GQA(Group Query Attention)
内存优化 flash attention
更快的解码注意力:Flash-Decoding
潜在表示降维:MLA(Multi-Layer Attention)
众所周知,尽管基于Attention机制的Transformer类模型有着良好的并行性能,但它的空间和时间复杂度都是O(n2)级别的,n是序列长度,所以当n比较大时Transformer模型的计算量难以承受。近来,也有不少工作致力于降低Transformer模型的计算量,比如模型剪枝、量化、蒸馏等精简技术,又或者修改Attention结构,使得其复杂度能降低到O(nlogn)甚至O(n)。
1 稀疏Attention
1.1 OpenAI的Sparse Attention
通过“只保留小区域内的数值、强制让大部分注意力为零”的方式,来减少Attention的计算量。经过特殊设计之后,Attention矩阵的大部分元素都是0,因此理论上它也能节省显存占用量和计算量。后续类似工作还有《Explicit Sparse Transformer: Concentrated Attention Through Explicit Selection》、《Longformer: The Long-Document Transformer》等。
但是很明显,这种思路有两个不足之处:
1、如何选择要保留的注意力区域,这是人工主观决定的,带有很大的不智能性;
2、它需要从编程上进行特定的设计优化,才能得到一个高效的实现,所以它不容易推广。
1.2 Reformer
Reformer也是有代表性的改进工作,它将Attention的复杂度降到了𝒪(nlogn)。某种意义上来说,Reformer也是稀疏Attention的一种,只不过它的稀疏Pattern不是事先指定的,而是通过LSH(Locality Sensitive Hashing)技术(近似地)快速地找到最大的若干个Attention值,然后只去计算那若干个值。此外,Reformer通过构造可逆形式的FFN(Feedforward Network)替换掉原来的FFN,然后重新设计反向传播过程,从而降低了显存占用量。
所以,相比前述稀疏Attention,Reformer解决了它的第一个缺点,但是依然有第二个缺点:实现起来复杂度高。要实现LSH形式的Attention比标准的Attention复杂多了,对可逆网络重写反向传播过程对普通读者来说更是遥不可及~
1.3 Linformer
它依然保留原始的Scaled-Dot Attention形式,但在进行Attention之前,用两个m×n的矩阵E,F分别对K,V进行投影,即变为
Attention(Q,K,V)=softmax(Q(EK)⊤)FV
这样一来,Q(EK)⊤就只是一个n×m的矩阵,而作者声称对于哪怕对于很大的序列长度n,m也可以保持为一个适中的常数,从而这种Attention也是线性的。跟Linformer类似的思路还出现在更早一些的CV论文《Asymmetric Non-local Neural Networks for Semantic Segmentation》中。
但是,笔者认为“对于超长序列m可以保持不变”这个结论是值得质疑的,对于长序列原论文只做了MLM任务,而很明显MLM并不那么需要长程依赖,所以这个实验没什么说服力。因此,Linformer是不是真的Linear,还有待商榷。
1.4 自回归生成
Linformer的另一个缺点是EK,FV这两个运算直接把整个序列的信息给“糅合”起来了,所以它没法简单地把将来信息给Mask掉(Causal Masking),从而无法做语言模型、Seq2Seq等自回归生成任务,这也是刚才说的原作者只做了MLM任务的原因。相比之下,本文介绍的几种Linear Attention都能做到这一点。
第一种:

这说明这种Attention可以作为一个RNN模型用递归的方式实现,它的空间复杂度最低,但是要串性计算,适合预测解码时使用;
第二种
直接将φ(K),V∈ℝn×d做外积,得到一个n×d×d的矩阵,然后对n那一维执行cumsum运算,这样就一次性得到S1,S2,…,Sn了,它的速度最快,但空间占用最大,适合训练时使用,不过很多时候都有d2≫n,一般情况下训练时都很难承受这个空间复杂度,因此多数还是用RNN形式。
1.5 下采样技术
从结果上来看,Linformer的EK,FV就是将序列变短(下采样)了,而将序列变短的一个最朴素的方法就是Pooling了,
所以笔者之前也尝试过把Pooling技术引入到Transformer中去。
近来也有类似的工作发出来,比如IBM的《PoWER-BERT: Accelerating BERT Inference via Progressive Word-vector Elimination》和Google的《Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing》。
除了Pooling之外,其实还有其他的下采样技术,比如可以通过stride > 1的一维卷积来实现,基于这个思路,或许我们可以把FFN里边的Position-Wise全连接换成stride > 1的一维卷积?总之这方面应该也能玩出很多花样来,不过跟Linformer一样,这样糅合之后做自回归生成就很难了
1.6 Nvidia-StarAttention
阶段一:输入的上下文部分被分割成较小的块,并分配到各个主机。除了第一个块之外,所有块的前面都加上一个初始块,称为「锚点」块(anchor block)。每个主机处理其分配的块,并存储非锚点部分的KV缓存。
阶段二:输入查询被广播到所有主机,每个主机中,它首先访问在第一阶段计算出的本地KV缓存。然后「查询」主机通过聚合所有主机的softmax归一化统计数据来计算全局注意力。这个过程对于每个生成的token都会重复。
1.7 MoonShot-MoBA
月之暗面通过整合来自 FlashAttention 和 MoE 的优化技术,提出了一种名为 MoBA的注意力机制,即 Mixture of Block Attention,可以直译为「块注意力混合」。
MoBA 是「一种将混合专家(MoE)原理应用于注意力机制的创新方法。」该方法遵循「更少结构」原则,并不会引入预定义的偏见,而是让模型自主决定关注哪些位置。
MoBA 注意力机制使模型能够自适应且动态地关注上下文中最有信息量的块。这在处理涉及长文档或序列的任务时尤其有益,因为在这些任务中,关注整个上下文可能是不必要的,并且计算代价高昂。MoBA 选择性地关注相关块的能力,使得信息处理更加细致且高效。
MoBA 主要包括如下部分:
- 可训练的块稀疏注意力:将完整上下文分割成若干块,每个查询 token 都会学习关注最相关的 KV 块,从而实现长序列的高效处理。
- 无参数门控机制:引入了一种新颖的无参数 top-k 门控机制,为每个查询 token 选择最相关的块,确保模型只关注最具信息量的内容。
- 完全注意力与稀疏注意力的无缝切换:MoBA 被设计为完全注意力机制的灵活替代方案,能够在完全注意力和稀疏注意力模式之间实现平滑过渡。
MoBA 模型与 Full Attention 模型(Llama-8B-1M-Full)性能相当。特别是在最具挑战性的 RULER 基准测试中,即使在 62.5% 的稀疏度下,MoBA 模型仍达到了 0.7818 的得分,几乎与 Full Attention 模型的 0.7849 持平。对于需要处理 100 万 token 的「大海捞针」测试集中,模型同样展现出优秀的能力。
1.6 Native Sparse Attention(NSA)
DeepSeek近期发布了NSA(Native Sparse Attention),目的就是进一步减少部署的成本
Native Sparse Attention: Hardware-Aligned and NativelyTrainable Sparse Attentionh
1.6.1 总结
这篇文章要解决的问题是长上下文建模的高计算成本问题。
该问题的研究难点包括:如何在保持模型能力的前提下提高效率,如何实现端到端训练以减少预训练计算量而不牺牲模型性能。
该问题的研究相关工作有:KV缓存淘汰方法、块状KV缓存选择方法、采样、聚类或哈希选择方法等。然而,这些方法在实际部署中往往未能达到理论上的加速效果,且主要集中于推理阶段,缺乏有效的训练时支持。
总体结论:
本文提出的NSA架构通过集成层次化令牌压缩和块状令牌选择在可训练架构中,实现了加速训练和推理,同时保持了全注意力性能。
NSA在一般基准测试中与全注意力基线匹配,在长上下文评估中超越了建模能力,并在推理能力上得到了增强,同时显著减少了计算延迟并实现了显著的速度提升。
核心创新:NSA的三大设计
Native Sparse:
- 指一种从模型架构设计阶段原生支持稀疏性的注意力机制,而非通过后处理(如剪枝)实现。
其核心在于通过算法创新直接构建稀疏计算模式,既减少计算量又保持模型性能。与传统稀疏方法不同,它通过动态分层策略(如压缩、选择、滑动窗口三路并行)实现全局与局部信息的平衡,同时支持端到端训练。- 创新点:避免传统稀疏方法因强行剪枝导致的性能下降,通过预训练阶段学习稀疏模式,确保模型能力与效率的同步优化。
Hardware-Aligned(硬件对齐)
- 意义:指算法设计与现代硬件特性(如GPU的Tensor Core、内存带宽)深度适配,最大化实际加速效果。NSA通过块级连续内存访问、算术强度均衡、Triton内核优化等技术,减少内存碎片化并提升计算吞吐量。
- 技术细节:例如,将键值序列分块处理以适配GPU并行计算单元,优化内存访问模式,使计算与硬件资源利用率达到平衡,从而在解码阶段实现11.6倍加速。
Natively Trainable(可原生训练)
- 意义:强调稀疏注意力机制在训练阶段即可原生支持,而非仅在推理阶段应用。NSA通过可微分操作(如动态门控权重、可逆压缩解码)实现梯度传播,避免传统方法中离散操作(如聚类、哈希)导致的训练不稳定问题。
- 优势:从预训练开始学习稀疏模式,降低长序列训练的计算成本(如64k序列的前向传播提速9倍),同时保持模型性能,甚至在某些任务中超越全注意力基线。
1.6.2 动态分层稀疏策略:三路注意力融合
NSA将输入序列分为三条并行路径处理,兼顾全局、局部与关键信息:
整体如下图,把KV向量分别输入三个分支,以不同的attention进行计算,然后最后加权在一起,后面会详细通俗展开介绍
- 左图:该框架通过三个并行的注意力分支处理输入序列:对于给定的查询,前面的键和值被处理为粗粒度模式(patterns)的压缩注意力、重要 token 块的选定注意力和局部上下文的滑动注意力。
- 右图:每个分支产生的不同注意力模式(patterns)的可视化。绿色区域表示需要计算注意力分数的区域,而白色区域表示可以跳过的区域。
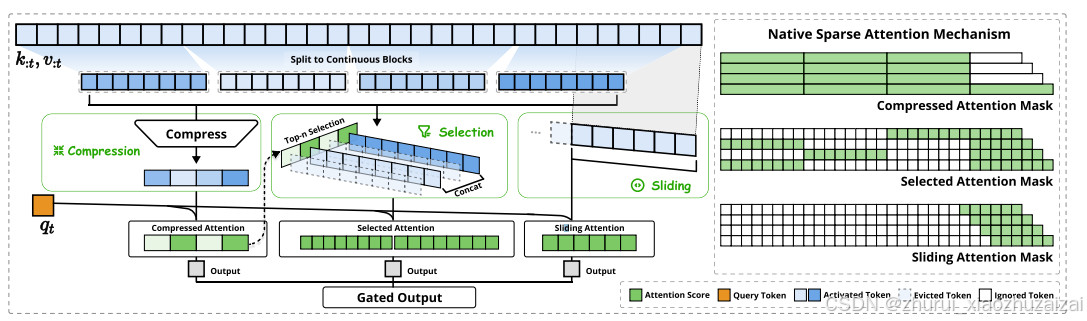
- 压缩路径(Compression):将长序列划分为块级(如每块512个token),通过可学习的MLP压缩为粗粒度表示,捕获全局语义(类似“一目十行”)。
- 选择路径(Selection):基于压缩块的注意力分数筛选出Top-N关键块,还原细粒度信息(类似“重点精读”)。
- 滑动窗口(Sliding Window):固定窗口覆盖最近的局部token,确保上下文连贯性(类似“实时关注最新动态”)。
三条路径的结果通过门控机制动态加权融合,避免模型因局部信息优势而忽略全局(如网页5所述“防止猪突思维”)。
在长序列处理中,传统注意力机制因计算量过大而效率低下,而简单稀疏方法往往顾此失彼。NSA通过动态分层稀疏策略,将序列拆解为不同粒度的信息流,再动态融合,实现了效率与精度的平衡。这一策略的核心是三路并行处理+门控融合,下面通过一个通俗案例展开解析。
假设模型需要分析一篇5万字的学术论文(约64k tokens),传统方法需让模型"逐字逐
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4132
4132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









