






费话不多少,主要是靠接口爬取,那么怎么获得接口就是一个问题了。
开始的页面是这样的:
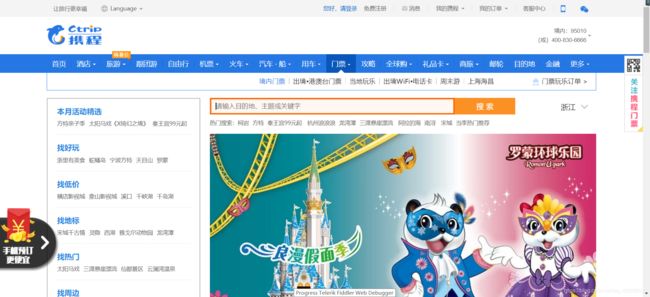
输入杭州后,然后打开fiddler开始抓包,注意这是最大的错误,就是这个错误导致了我一直找不到接口,这样点击搜索后是找不到返回数据的接口的,因为在你杭州输入搜索框后即使没有点击搜索按钮,这个时候已经返回了数据。所以在你输入杭州之前就应该打开了fiddler。ok,正确的接口如下(8.1测试时的接口):
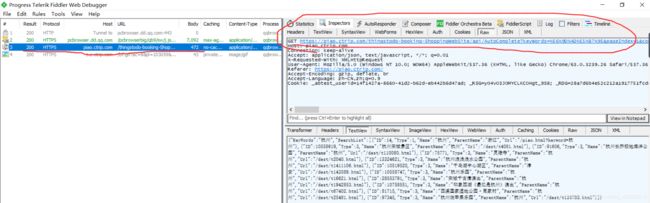
点击webForms看到参数:

这样就很明了了。
但是实际应用时发现无论更改index为多少返回的都是第一页的值,如果手动翻页,发现相应的请求和下边获得评论的请求方式是一样的(建议先跳过这一段看完下边获取评论的请求后再来看这里,这是因为这部分是后来补充的)。像这样:
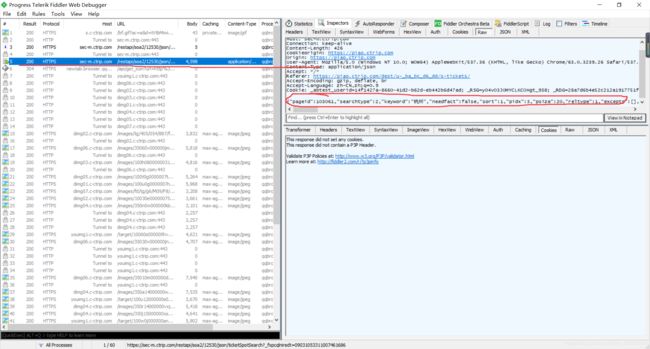
但是没找到这个pageid参数在哪出现的,所以就没办法了。
那我们就换一种方法,不从这里获得景点信息。而是从这里
https://you.ctrip.com/sight/zhangjiajie23.html
这是第一页,而如果翻页的话url会变,例如:
https://you.ctrip.com/sight/zhangjiajie23/s0-p2.html
这是第二页,很明显我们可以通过控制s0-p2,后边这个2来控制页数。但是这样会有问题,就是说解析出来的详情页的url会跳转到门票这一栏,就是说正常情况下解析出来的url是这种 https://you.ctrip.com/sight/wulingyuan120559/2441.html,但是会有重定向,定向到这里 https://piao.ctrip.com/ticket/dest/t56867.html,两者内容一样,前者的详情页url会更好解析评论(对于有经验的人来说很简单,这就不说了),后者的详情页的url的评论的解析会在下边。
ok,再看返回的数据
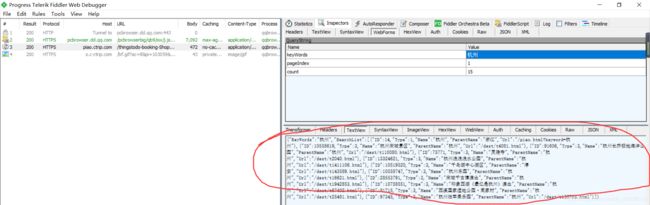
返回的数据有各个景点详情页的url。
接下来对评论进行分析。
先找个景点的详情页点进去(写这篇博客时用到的详情页https://piao.ctrip.com/ticket/dest/t4081.html)。然后多点击几页评论,用fiddler看看这些获得评论的请求有什么不同。
红色下划线画出的就是获得评论数据的url,但是有的返回的是5个字节,而且显示的是options请求、

options请求相当于一个预请求,先看看这个网站是不是支持我想要的数据的格式(大概意思是这样,勿喷),返回200后就进行真正的post请求。
在这里我们不用管。
再看返回了评论的请求。
一开始我是先比较webForms,然后比较headers,然后比较url,发现这些都一样,就很纳闷了,最后在Raw里看到了一样东西。
在比较不同的获得评论的请求发现这个东西就是获取数据的关键,但是不知道这是什么东西,气,百度后发现这是另一种post请求传输数据的形式。application/json形式。
常见的四种post提交数据的形式
ok,知道后就去百度,怎么用requests以application/json的形式提交数据,原来是把上边圈中(就上张图)的那个字典以json.dumps(字典)传给data参数就可以了。
去试一下:
测试代码
import requests
import json
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6788.400 QQBrowser/10.3.2843.400',
}
url = "https://sec-m.ctrip.com/restapi/soa2/12530/json/viewCommentList"
requestdata = {"pageid":10650000804,"viewid":4081,"tagid":0,"pagenum":6,"pagesize":10,"contentType":"json","head":{"appid":"100013776","cid":"09031053311007461686","ctok":"","cver":"1.0","lang":"01","sid":"8888","syscode":"09","auth":"","extension":[]},"ver":"7.10.3.0319180000"}
resp = requests.post(url=url,headers=headers,data=json.dumps(requestdata))
print(json.loads(resp.text))
ok正确反回了评论信息,但是如何得到字典中的数据呢,
首先是pageid,在景点详情页中搜一下(右键,查看网页源代码 ,crtl + F,输入pageid的值) 搜到了:

viewid是4081,刚好和详情页的url中的数字对应(https://piao.ctrip.com/ticket/dest/t4081.html)
tagid试了几页应该是0
其他的就比较常规,而head中有几项找不到,试了下head:{},发现也可以获得数据
就是说这段代码和上边那段代码效果是一样的。
import requests
import json
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6788.400 QQBrowser/10.3.2843.400',
}
url = "https://sec-m.ctrip.com/restapi/soa2/12530/json/viewCommentList"
requestdata = {"pageid":10650000804,"viewid":4081,"tagid":0,"pagenum":6,"pagesize":10,"contentType":"json","head":{}}
resp = requests.post(url=url,headers=headers,data=json.dumps(requestdata))
print(json.loads(resp.text))















 2818
2818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









