






前言
最近杂七杂八的事情比较多,难得抽出时间来弥补一下之前的系列,欠大家的埋点系列现在开始走起来
为什么需要埋点系统
电影中
前端开发攻城狮开开心心的 coding,非常自豪的进行了业务、UI 分离开发,各种设计模式、算法优化轮番上阵,代码写的 Perfect(劳资代码天下第一),没有 BUG,程序完美,兼容性 No.1,代码能打能抗质量高。下班轻松打卡,回家看娃。
现实中
实际上,开发环境与生产环境并不能等同,并且测试的过程再完善,依然会有漏测的情况存在。考虑到用户使用客户端环境、网络环境等等一系列的不确定因素存在。
所以在开发过程中一定要记得三大原则(我胡诌的)
没有完美的代码,只有没发现的 BUG
绝对不要相信测试环境,没有一种测试环境都涵盖所有线上情况
如果线上没有一点反馈,不要怀疑,问题应该藏得很深、很深
什么是埋点系统
埋点就像城市中的摄像头,从产品的角度考虑,它可以监控到用户在我们产品里的行为轨迹,为产品的迭代、项目的稳定提供依据,WHO、WHEN、WHERE、HOW、WHAT 是埋点采集数据的基础维度。
对前端开发而言,可以监控页面资源加载性能,异常等等,提供了页面体验和健康指数,为后续性能优化提供依据,及时上报异常和发生场景。从而能够及时修正问题,提高项目质量等。
埋点可以大概分为三类:
无痕埋点 - 无差别收集页面所有信息包括页面进出、事件点击等等,需要进行数据冲洗才能获取到有用信息
可视化埋点 - 根据生成的页面结构获取特定点位,单独埋点分析
业务代码手动埋点 - 根据具体复杂的业务,除掉上述两种不能涵盖的地方进行业务代码埋点
| 代码埋点 | 可视化埋点 | 无痕埋点 | |
|---|---|---|---|
| 典型场景 | 无痕埋点无法覆盖到,比如需要业务数据 | 简单规范的页面场景 | 简单规范的页面场景, |
| 优势 | 业务数据明确 | 开发成本低,运营人员可直接进行相关埋点配置 | 无需配置,数据可回溯 |
| 不足 | 数据不可回溯,开发成本高 | 不能关联业务数据,数据不可回溯 | 数据量较大,不能关联业务数据 |
大部分情况,我们可以通过无痕埋点收集到所有的信息数据,再配合可视化埋点,能够具体定位到某一个点位,这样大部分的埋点信息都据此分析出来。
在特殊情况下,可以多加上业务代码手动埋点,处理一下特别的场景(大部分情况是走强业务与正常的点击,刷新事件无关需要上报的信息)
埋点 SDK 开发
埋点数据收集分析
事件基本数据
事件发生时间
发生时页面信息快照
页面
页面 PV,UV
用户页面停留时长
页面跳转事件
页面进入后台
用户离开页面
用户信息
用户 uid
用户设备指纹
设备信息
ip
定位
用户操作行为
点击目标
用户点击
页面 AJAX 请求
请求成功
请求失败
请求超时
页面报错
资源加载报错
JS 运行报错
资源加载新性能
图片
脚本
页面加载性能
上面的数据通过 3 个维度来定义埋点事件
·
LEVEL: 描述埋点数据的日志级别INFO:一些用户操作,请求成功,资源加载等等正常的数据记录ERROR:JS报错,接口报错等等错误类型的数据记录DEBUG:预留开发人员通过手动调用的方式回传排除bug的数据记录WARN:预留开发人员通过手动调用的方式回传非正常用户行为的的数据记录
CATEGORY:描述埋点数据的分类WILL_MOUNT:sdk对象即将初始化加载,生成一个默认ID,跟踪全部相关事件DID_MOUNTED:sdk对象初始化完成,主要获取设备指纹等等的异步操作完成TRACK: 埋点SDK对象的生命周期管理整个埋点数据。AJAX: AJAX相关数据ERROR:页面中的异常相关数据PERFORMANCE:关于性能相关数据OPERATION:用户操作相关数据
EVENT_NAME:具体的事件名称
根据上述的维度,我们可以简单设计如下的架构
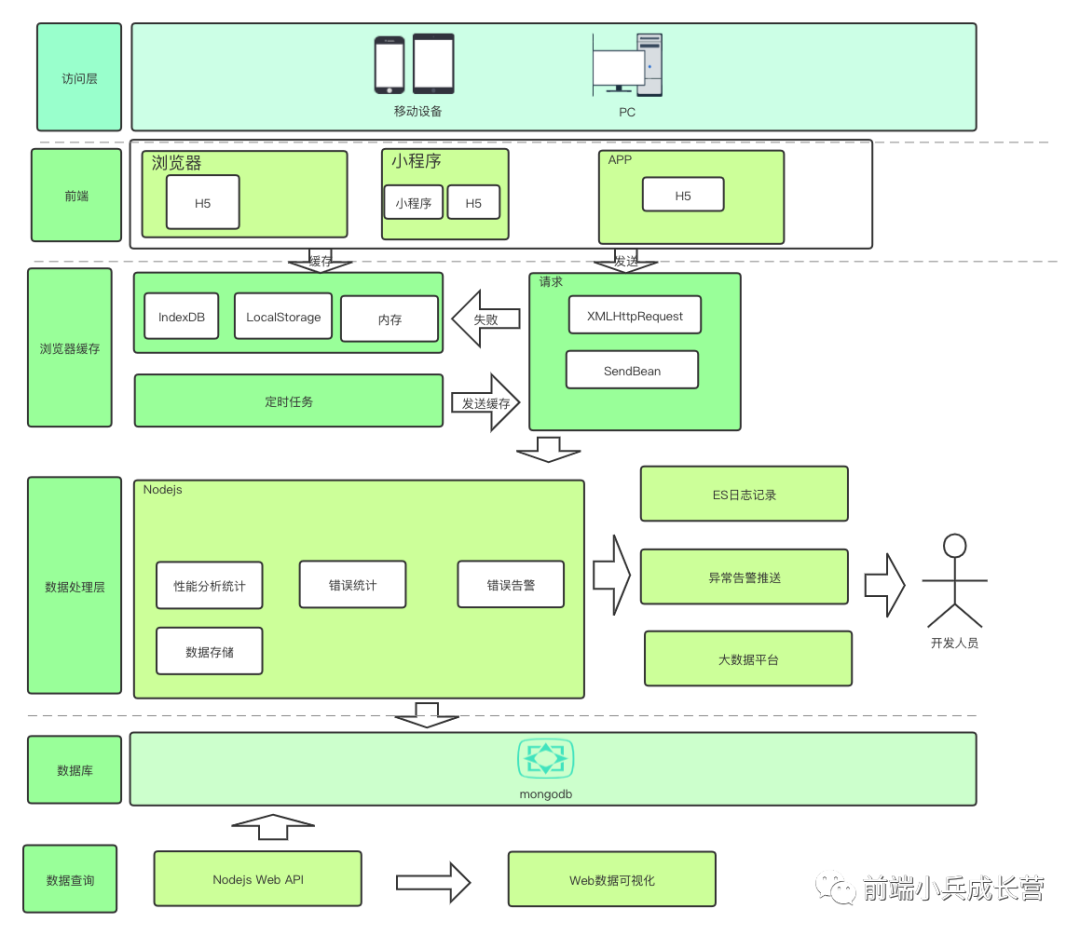
根据上图的架构,再进行下面的具体代码开发
代理请求
在浏览器中现在主要有 2 种请求方式,一个是 XMLHttpRequest, 一个是 Fetch。
代理 XMLHttpRequest
function NewXHR() {
var realXHR: any = new OldXHR(); // 代理模式里面有提到过
realXHR.id = guid()
const oldSend = realXHR.send;
realXHR.send = function (body) {
oldSend.call(this, body)
//记录埋点
}
realXHR.addEventListener('load', function () {
//记录埋点
}, false);
realXHR.addEventListener('abort', function () {
//记录埋点
}, false);
realXHR.addEventListener('error', function () {
//记录埋点
}, false);
realXHR.addEventListener('timeout', function () {
//记录埋点
}, false);
return realXHR;
}
代理 Fetch
const oldFetch = window.fetch;
function newFetch(url, init) {
const fetchObj = {
url: url,
method: method,
body: body,
}
ajaxEventTrigger.call(fetchObj, AJAX_START);
return oldFetch.apply(this, arguments).then(function (response) {
if (response.ok) {
//记录埋点
} else {
//上报错误
}
return response
}).catch(function (error) {
fetchObj.error = error
//记录埋点
throw error
})
}
监听页面的 PV,UV
在进入页面时,我们通过算法生成一个唯一 session id,作为这次埋点行为的全局 id,上报用户 id,设备指纹,设备信息。在用户未登录的情况下,通过设备指纹来计算 UV,通过 session id计算 PV。
异常捕获
异常就是干扰程序的正常流程的不寻常事故
RUNTIME ERROR
在JS中可以通过 window.onerror和window.addEventListener('error', callback) 捕捉运行时异常,一般使用window.onerror,它兼容性更好。
window.onerror = function(message, url, lineno, columnNo, error) {
const lowCashMessage = message.toLowerCase()
if(lowCashMessage.indexOf('script error') > -1) {
return
}
const detail = {
url: url
filename: filename,
columnNo: columnNo,
lineno: lineno,
stack: error.stack,
message: message
}
//记录埋点
}
Script Error
在这里我们过滤了 Script Error, 它产生的原因主要是页面中加载的第三方跨域脚本报错,比如托管在第三方 CDN 中的 js 脚本。这类问题比较难以排查。解决的方法有:
打开
CORS(Cross Origin Resource Sharing,跨域资源共享),如下步骤修改
Access-Control-Allow-Origin: * | 指定域名
使用
try catch














 960
960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









