






Pytorch-lightning可以非常简洁得构建深度学习代码。但是其实大部分人用不到很多复杂得功能,并且用的时候稍微有一些不灵活。
Pytorch-lightning(以下简称pl)可以非常简洁得构建深度学习代码。但是其实大部分人用不到很多复杂得功能。而pl有时候包装得过于深了,用的时候稍微有一些不灵活。通常来说,在你的模型搭建好之后,大部分的功能都会被封装在一个叫trainer的类里面。一些比较麻烦但是需要的功能通常如下:
- 保存checkpoints
- 输出log信息
- resume training 即重载训练,我们希望可以接着上一次的epoch继续训练
- 记录模型训练的过程(通常使用tensorboard)
- 设置seed,即保证训练过程可以复制
好在这些功能在pl中都已经实现。
由于doc上的很多解释并不是很清楚,而且网上例子也不是特别多。下面分享一点我自己的使用心得。
首先关于设置全局的种子:
只需要import如上的seed_everything函数即可。它应该和如下的函数是等价的:
def seed_all(seed_value):
random.seed(seed_value) # Python
np.random.seed(seed_value) # cpu vars
torch.manual_seed(seed_value) # cpu vars
if torch.cuda.is_available():
print ('CUDA is available')
torch.cuda.manual_seed(seed_value)
torch.cuda.manual_seed_all(seed_value) # gpu vars
torch.backends.cudnn.deterministic = True #needed
torch.backends.cudnn.benchmark = False
seed=42
seed_all(seed)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
但经过我的测试,好像pl的seed_everything函数应该更全一点。
下面通过一个具体的例子来说明一些使用方法:
先下载、导入必要的包和下载数据集:
!pip install pytorch-lightning
!wget https://download.pytorch.org/tutorial/hymenoptera_data.zip
!unzip -q hymenoptera_data.zip
!rm hymenoptera_data.zip
import pytorch_lightning as pl
import os
import numpy as np
import random
import matplotlib.pyplot as plt
import torch
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
以下代码种加入!的代码是在terminal中运行的。在google colab中运行linux命令需要在之前加!
如果是使用google colab,由于它创建的是一个虚拟机,不能及时保存,所以如果需要保存,挂载自己google云盘也是有必要的。使用如下的代码:
先如下定义如下的LightningModule和main函数。
class CoolSystem(pl.LightningModule):
def __init__(self, hparams):
super(CoolSystem, self).__init__()
self.params = hparams
self.data_dir = self.params.data_dir
self.num_classes = self.params.num_classes
########## define the model ##########
arch = torchvision.models.resnet18(pretrained=True)
num_ftrs = arch.fc.in_features
modules = list(arch.children())[:-1] # ResNet18 has 10 children
self.backbone = torch.nn.Sequential(*modules) # [bs, 512, 1, 1]
self.final = torch.nn.Sequential(
torch.nn.Linear(num_ftrs, 128),
torch.nn.ReLU(inplace=True),
torch.nn.Linear(128, self.num_classes),
torch.nn.Softmax(dim=1))
def forward(self, x):
x = self.backbone(x)
x = x.reshape(x.size(0), -1)
x = self.final(x)
return x
def configure_optimizers(self):
# REQUIRED
optimizer = torch.optim.SGD([
{'params': self.backbone.parameters()},
{'params': self.final.parameters(), 'lr': 1e-2}
], lr=1e-3, momentum=0.9)
exp_lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
return [optimizer], [exp_lr_scheduler]
def training_step(self, batch, batch_idx):
# REQUIRED
x, y = batch
y_hat = self.forward(x)
loss = F.cross_entropy(y_hat, y)
_, preds = torch.max(y_hat, dim=1)
acc = torch.sum(preds == y.data) / (y.shape[0] * 1.0)
self.log('train_loss', loss)
self.log('train_acc', acc)
return {'loss': loss, 'train_acc': acc}
def validation_step(self, batch, batch_idx):
# OPTIONAL
x, y = batch
y_hat = self.forward(x)
loss = F.cross_entropy(y_hat, y)
_, preds = torch.max(y_hat, 1)
acc = torch.sum(preds == y.data) / (y.shape[0] * 1.0)
self.log('val_loss', loss)
self.log('val_acc', acc)
return {'val_loss': loss, 'val_acc': acc}
def test_step(self, batch, batch_idx):
# OPTIONAL
x, y = batch
y_hat = self.forward(x)
loss = F.cross_entropy(y_hat, y)
_, preds = torch.max(y_hat, 1)
acc = torch.sum(preds == y.data) / (y.shape[0] * 1.0)
return {'test_loss': loss, 'test_acc': acc}
def train_dataloader(self):
# REQUIRED
transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
train_set = torchvision.datasets.ImageFolder(os.path.join(self.data_dir, 'train'), transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True, num_workers=4)
return train_loader
def val_dataloader(self):
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val_set = torchvision.datasets.ImageFolder(os.path.join(self.data_dir, 'val'), transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=32, shuffle=True, num_workers=4)
return val_loader
def test_dataloader(self):
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val_set = torchvision.datasets.ImageFolder(os.path.join(self.data_dir, 'val'), transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=8, shuffle=True, num_workers=4)
return val_loader
def main(hparams):
model = CoolSystem(hparams)
trainer = pl.Trainer(
max_epochs=hparams.epochs,
gpus=1,
accelerator='dp'
)
trainer.fit(model)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.
- 122.
- 123.
- 124.
- 125.
- 126.
- 127.
- 128.
- 129.
- 130.
- 131.
- 132.
- 133.
- 134.
- 135.
- 136.
- 137.
下面是run的部分:
如果希望重载训练的话,可以按如下方式:
# resume training
RESUME = True
if RESUME:
resume_checkpoint_dir = './lightning_logs/version_0/checkpoints/'
checkpoint_path = os.listdir(resume_checkpoint_dir)[0]
resume_checkpoint_path = resume_checkpoint_dir + checkpoint_path
args = {
'num_classes': 2,
'data_dir': "/content/hymenoptera_data"}
hparams = Namespace(**args)
model = CoolSystem(hparams)
trainer = pl.Trainer(gpus=1,
max_epochs=10,
accelerator='dp',
resume_from_checkpoint = resume_checkpoint_path)
trainer.fit(model)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
如果我们想要从checkpoint加载模型,并进行使用可以按如下操作来:
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(inp):
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
plt.show()
classes = ['ants', 'bees']
checkpoint_dir = 'lightning_logs/version_1/checkpoints/'
checkpoint_path = checkpoint_dir + os.listdir(checkpoint_dir)[0]
checkpoint = torch.load(checkpoint_path)
model_infer = CoolSystem(hparams)
model_infer.load_state_dict(checkpoint['state_dict'])
try_dataloader = model_infer.test_dataloader()
inputs, labels = next(iter(try_dataloader))
# print images and ground truth
imshow(torchvision.utils.make_grid(inputs))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(8)))
# inference
outputs = model_infer(inputs)
_, preds = torch.max(outputs, dim=1)
# print (preds)
print (torch.sum(preds == labels.data) / (labels.shape[0] * 1.0))
print('Predicted: ', ' '.join('%5s' % classes[preds[j]] for j in range(8)))- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.

预测结果如上。
如果希望检测训练过程(第一部分+重载训练的部分),如下:
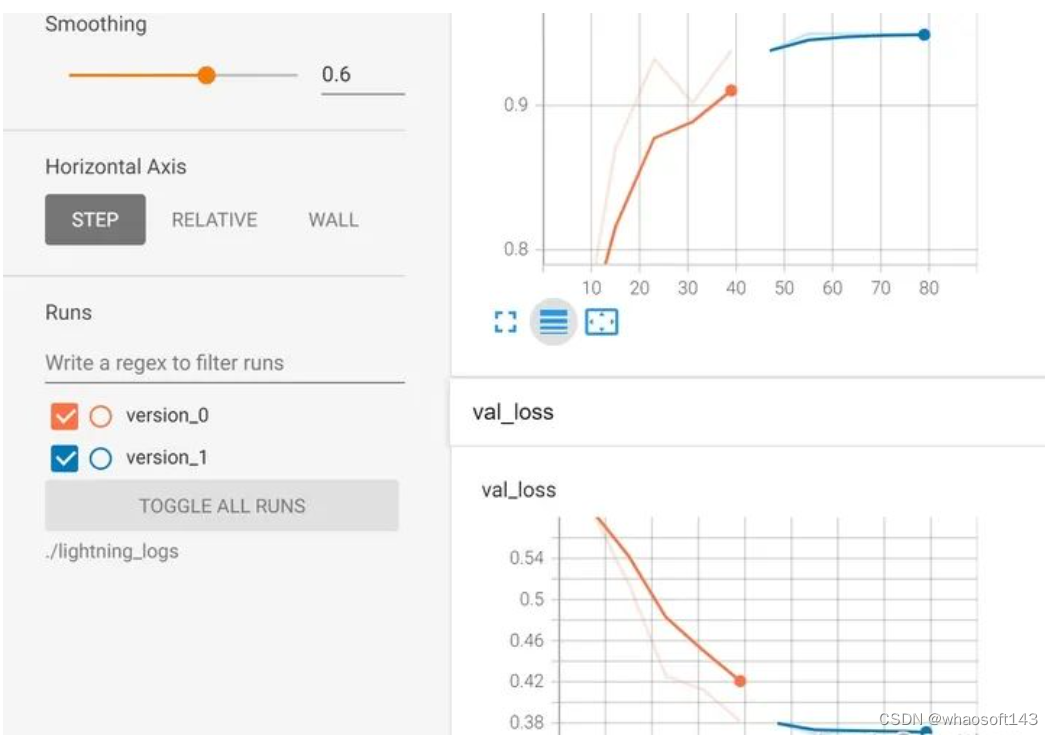
训练过程在tensorboard里面记录,version0是第一次的训练,version1是重载后的结果。
完整的code在这里.















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









