









1.基础模型
1.1传统模型(HMM和CRF)
隐马尔可夫模型(Hidden Markov Model),隐马尔可夫模型,一般以文本序列数据为输入,以该序列对应的隐含序列为输出。

CRF(Conditional Random Fields)模型,称为条件随机场,一般也以文本序列数据为输入,以该序列对应的隐含序列为输出。
可用于解决文本序列标注问题,如分词,词性标注,命名实体识别。


感觉黑马视频这一部分讲得不是很好,以后看到了好的理论解释再补充。
1.2 传统RNN模型
RNN(Recurrent Neural Network)循环神经网络,循环使用一个隐藏层单元,将序列信息作为输入,能够很好地利用序列之间的关系。
根据输入输出结构来划分:
- N对N的RNN:输入输出等长都是序列数据,应用如诗句生成;

- N对1的RNN:输入序列数据,生成一种判断预测,应用如文本分类,用户意图识别;

- 1对N的RNN:输入一个结构化输入(如图片),应用如图片生成文字;

- N对M的RNN:输入输出端不规定长度,也常被称为seq2seq,由编码器和解码器组成(相当于N对1+1对M)。
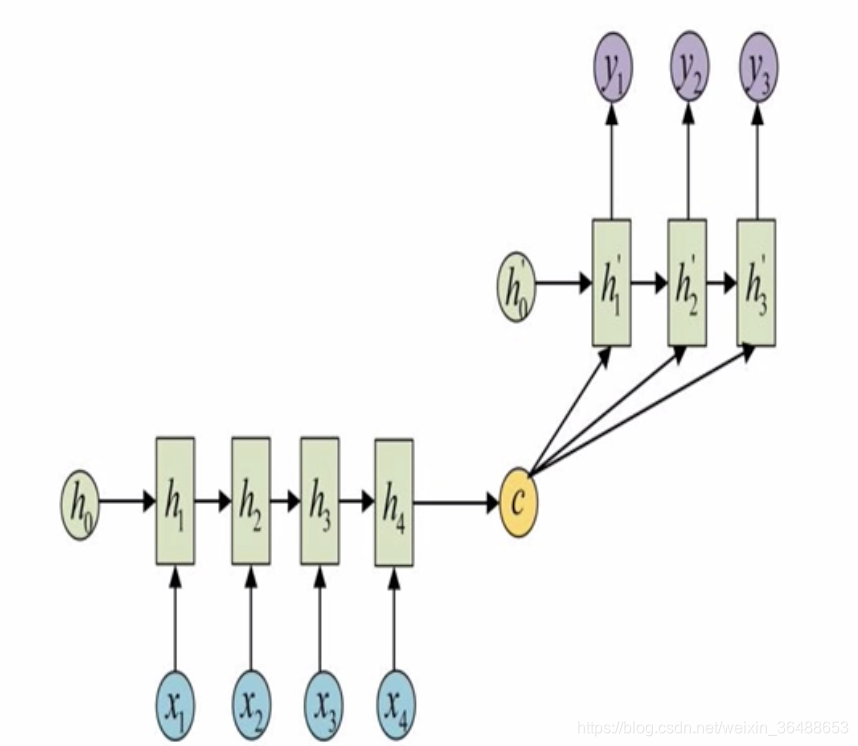
传统RNN内部结构:

RNN基本使用:
import torch
import torch.nn as nn
rnn = nn.RNN(input_size, hidden_size, num_layers)
input = torch.randn(seq_len, batch_size, input_size)
h0 = torch.randn(num_layers, batch_size, hidden_size)
output, hn = rnn(input, h0)
优点:计算资源要求低,短序列任务性能效果比较优异;
缺点:长序列会导致梯度消失或梯度爆炸(反向传播算法和链式求导法则,sigmoid函数导致对特征进行运算后的值范围在[0, 0.025]之间,当权重很大时会导致梯度爆炸,当权重很小时会导致梯度消失)
2. 改进的RNN模型
2.1 LSTM模型
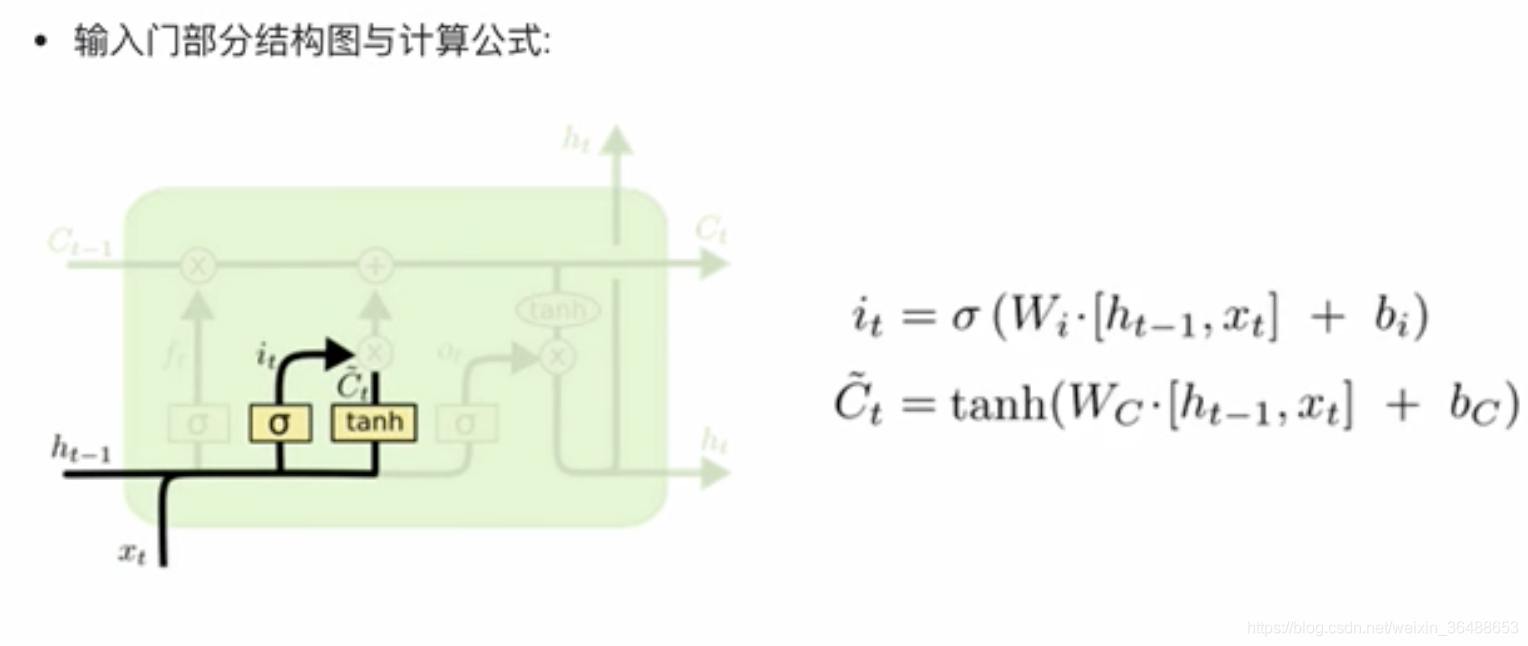
LSTM(Long Short-Term Memory),能够有效捕捉长序列之间的语义关联,缓解梯度消失或爆炸的问题。
LSTM结构:




Bi-LSTM:双向LSTM,模型复杂度翻倍。

pytorch中的LSTM:
"""
nn.LSTM类主要参数:
input_size: 输入张量x中特征维度的大小
hidden_szie: 隐层张量h中特征维度的大小
num_layers: 隐含层的数量
bidirectional: 是否选择双向
nn.LSTM类实例化对象主要参数:
input: 输入张量x
h0:初始化的隐层张量h
c0:初始化的细胞状态张量c
"""
import torch.nn as nn
import torch
# input_size, hidden_size, num_layers
rnn = nn.LSTM(5, 6, 2)
input_tensor = torch.randn(1, 3, 5)
h0 = torch.randn(2, 3, 6)
c0 = torch.randn(2, 3, 6)
output, (hm, cn) = rnn(input_tensor, (h0, c0))
2.1 GRU模型
GRU(Gated Recurrent Unit)也称为门控循环单元结构,核心结构可以分为两个部分:更新门和重置门。

GRU的pytorch实现:
"""
类参数和LSTM类似
nn.GRU实例化对象主要参数:
input: 输入张量x
h0:初始化的隐层张量h
"""
import torch
import torch.nn as nn
rnn = nn.GRU(5, 6, 2)
input_tensor = torch.randn(1, 3, 5)
h0 = torch.randn(2, 3, 6)
output, hn = rnn(input_tensor, h0)
2.3 注意力机制
注意力机制计算规则:需要三个指定的输入Q(query)、K(key)、V(value),然后通过计算公式得到注意力的结构,这个结果代表query在key和value作用下的注意力表示,当输入的Q=K=V表示自注意力机制。
常见的注意力计算规则:
将Q,K进行纵轴拼接,做一次线性变化,再使用softmax处理获得结果后与V做张量乘法:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( L i n e a r ( [ Q , K ] ) ) ⋅ V Attention(Q,K,V)=softmax(Linear([Q,K]))·V Attention(Q,K,V)=softmax(Linear([Q,K]))⋅V
将Q,K进行纵轴拼接,做一次线性变化后再使用tanh函数激活,然后再进行内部求和,最后使用softmax处理获得结果再与V做张量乘法:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( ∑ ( t a n h ( L i n e a r ( [ Q , K ] ) ) ) ) ⋅ V Attention(Q,K,V)=softmax(\sum(tanh(Linear([Q,K]))))·V Attention(Q,K,V)=softmax(∑(tanh(Linear([Q,K]))))⋅V
将Q与K的转置做点积运算,然后除以一个缩放系数,再使用softmax处理获得结果最后与V做张量乘法:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q ⋅ K T d k ) ) ⋅ V Attention(Q,K,V)=softmax(\frac {Q·K^T}{\sqrt d_k}))·V Attention(Q,K,V)=softmax(dkQ⋅KT))⋅V
注:当注意力权重矩阵和V都是三维张量👎第一维度表示batch_size时,则做bmm运算:
# shape1(b*n*m) shpae2(b*m*p) shape3(b*n*p)
input_tensor = torch.randn(10, 3, 4)
mat2 = torch.randn(10, 4, 5)
res = torch.bmm(input_tensor, mat2)
print(res.size)
# torch.Size([10, 3, 5])
注意力机制的作用:
- 在解码器端的注意力机制:能够根据模型目标有效的聚焦编码器输出结果,当其作为解码器的输入时提升效果,改善以往编码器输出时单一定长张量,无法存储过多信息的情况;
- 在编码器端的注意力机制:主要解决表征问题,相当于特征提取过程,得到输入的注意力表示,一般使用自注意力。
pytorch实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Attn(nn.Module):
def __init__(self, query_size, key_size, value_szie1, value_size2, output_size):
super(Attn, self).__init__()
self.query_size = query_size
self.key_size = key_size
self.value_szie1 = value_szie1
self.value_szie2 = value_szie2
self.output_size = output_size
# 初始化注意力机制实现第一步中需要的线性层
self.attn = nn.Linear(self.query_size + self.key_size, value_size1)
# 初始化注意力机制实现第三步中需要的线性层
self.attn_combine = nn.Linear(self.query_size + self.value_size2, output_szie)
def forward(self, Q, K, V):
# 第一步按照计算规则
# 将Q,K进行纵轴拼接,做一次线性变化,再使用softmax处理获得结果
attn_weights = F.softmax(self.attn(torch.cat(Q[0], K[0]), 1)), dim=1)
# 与V进行矩阵乘法运算
attn_applied = torch.bmm(attn_weights.unsqueeze(0), V)
output = torch.cat(Q[0], attn_applied[0], 1)
output = self.attn_combine(output).unsqueeze(0)
return output, attn_weights














 1030
1030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









