







 本文详细回顾了近年来针对目标检测任务的无监督域适应方法,涵盖对抗性特征学习、图像到图像翻译、域随机化、伪标签自我训练、mean-teacher训练和图推理等策略。这些方法旨在减小源域和目标域之间的差异,提高目标检测模型在未标记数据集上的性能。讨论了不同方法的优缺点,分析了各种数据集和评估协议,最后指出了未来可能的研究方向,包括综合评估、利用现实世界约束改进泛化能力等。
本文详细回顾了近年来针对目标检测任务的无监督域适应方法,涵盖对抗性特征学习、图像到图像翻译、域随机化、伪标签自我训练、mean-teacher训练和图推理等策略。这些方法旨在减小源域和目标域之间的差异,提高目标检测模型在未标记数据集上的性能。讨论了不同方法的优缺点,分析了各种数据集和评估协议,最后指出了未来可能的研究方向,包括综合评估、利用现实世界约束改进泛化能力等。
目录
4.2.1、Adverse weather conditions
4.2.2 Synthetic data adaptation
4.2.4 Adaptation between dissimilar domains
4.2.5 Adaptation to Large-scale Dataset
4.4.1 Is one category of adaptation methods better than the other category of approaches?
5.2 Improving generalization with real-world constraints
摘要
深度学习的最新进展导致了各种计算机视觉应用(如目标分类、语义分割和目标检测)的准确和高效模型的发展。 然而,学习高度精确的模型依赖于拥有大量标注图像的数据集。 因此,当在具有视觉上不同图像的标签稀缺数据集上进行评估时模型性能急剧下降,被称为域适配问题。 这个问题通常被称为协变量偏移或数据集偏差。 当学习针对标签稀缺的目标数据集的分类器时,域自适应试图通过利用相关领域标记数据的领域转移特征来解决这个问题。 通过无监督领域自适应,将目标分类和语义分割模型适应于缺乏标签的目标数据集有大量的工作。 考虑到目标检测是计算机视觉中的一项基本任务,最近的许多工作都集中在解决目标检测的领域适应性问题。 在本文中,我们简要介绍了目标检测的领域自适应问题,并概述了迄今为止提出的解决该问题的各种方法。 此外,我们强调了针对这个问题提出的策略和相关的缺点。 随后,我们确定了无监督域自适应检测问题的多个方面,这是最有前途的未来研究领域。 我们相信,本研究将对计算机视觉、生物特征、医学成像、自主导航等领域的模式识别专家介绍该问题,了解目前的研究进展,为未来的研究提供有价值的方向。
1、简介
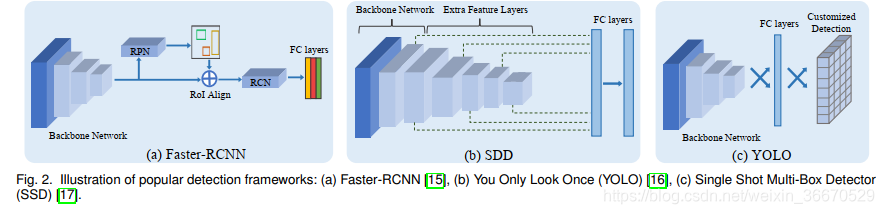
深度学习的兴起对各个领域如括语言处理、机器人、计算机视觉等。 这在计算机视觉方面尤其明显,其中大部分的进展很大程度上是由深度卷积神经网络(DCNN)的成功指导的。 由于它们的学习能力,基于DCNN的模型在许多视觉任务中取得了最先进的性能,如目标分类,语义分割和目标检测。 这导致了DCNN在现实世界的应用中越来越受欢迎,与传统方法相比。 具体来说,目标检测已经成为许多现实世界应用的组成部分,包括视频安全/监控、增强现实、自主导航、人机界面、自助结账便利店。 基于DCNN的目标检测器如Faster-RCNN, You Only Look Once (YOLO)和Single Shot Multi-box Detector (SSD)的主要进步导致了检测性能和速度的显著提高。
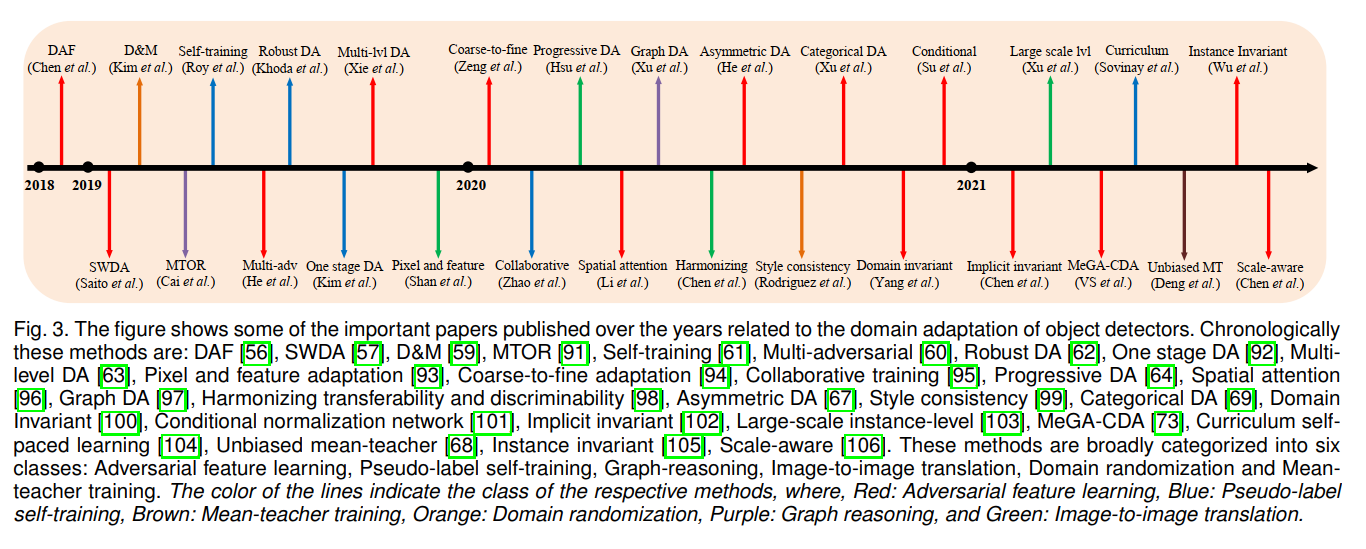
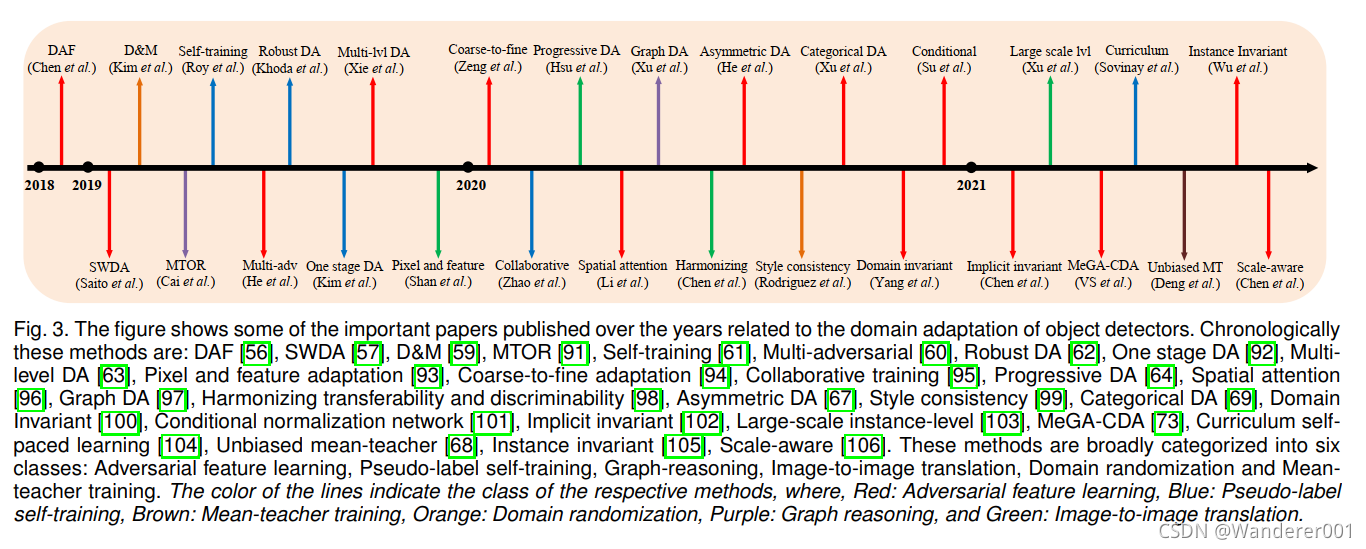
需要注意的是,大多数DCNN模型需要以一种监督的方式进行训练,这是由于有大量数据集,这些数据集包含数千张用ground-truth标签标注的图像。 然而,与训练图像相比,DCNN模型对视觉上明显不同的图像泛化能力较差。 例如,由于场景/对象和/或城市间天气的变化,用罗马收集的数据集训练的检测模型不一定能很好地处理东京的图像,如图1(c)所示。 类似的趋势也显示在晴天到大雾天气(图1(A))、热天气可见(图1(b))和真实世界合成(图1(d))的情况下。 解决这一问题的一个简单方法是在日本城市图像上标注ground-truth 检测标签。 然而,考虑到注释过程的人工成本对于所有视觉上不同的条件可能变得过于昂贵,这可能被证明是不可行的。 为了避免这个问题,许多方法依赖于无监督域自适应的原则,这涉及到训练DCNN模型的标签丰富的源数据集和标签缺乏的目标数据集具有视觉上明显的外观。 利用源域和目标域数据集进行域适配训练提高了泛化能力,从而提高了对目标域的视觉区分性能。 无监督的域适配已经广泛研究的任务分类和语义分割。 然而,不同于分类(图像级类别预测)和语义分割(像素级类别预测),目标检测任务包括边界框定位和边界框级类别预测任务。 这提出了独特的挑战,在解决无监督领域适应目标检测模型。 这引发了人们对无监督域自适应目标检测的兴趣, 图3显示了多年来提出的一些具有里程碑意义的论文。


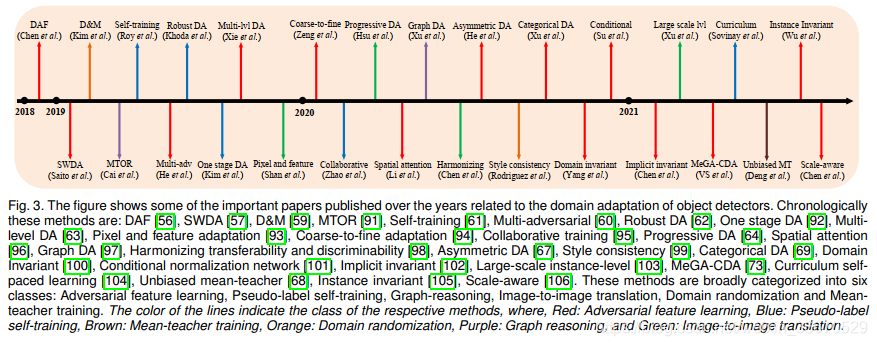
虽然已有多篇综述性论文对分类和语义分割进行了文献综述,但据我们所知,在目标检测方面还没有同样的工作。 Li等人对域适配目标检测的文献进行了简要概述,但缺乏对该方法的详细讨论,也没有对现有方法进行全面比较。 这促使我们对过去几年提出的所有领域自适应目标检测方法进行全面的文献分析,并进行详细的讨论。 这项工作的主要贡献总结如下:
1)、据我们所知,这是第一个覆盖无监督域适配深度目标探测器的全面综述论文。 本文讨论了域适配目标检测的多种检测框架、适应策略、数据集和评估协议。
2)、相对于现有的深度域自适应目标检测的综述,我们对现有的工作进行了详细而深入的讨论,包括最新的方法和文献中各种工作的分类。 此外,我们还讨论了初步的主题,使论文自给自足和有用的读者谁不熟悉目标检测和/或无监督领域适配。
3)、我们对文献中用于无监督域自适应目标检测的所有公开数据集上的现有方法进行了全面比较,简要讨论了方法,并详细比较了其性能以及各自的实验设置。
4)、我们还确定了未来可能有利于该领域的研究人员的研究方向,以进一步提高技术水平。
2、基础
在本节中,我们简要讨论与领域自适应目标检测相关的两个重要方面,即目标检测和无监督领域自适应。 此外,我们正式设置了问题和整个论文中使用的符号。
2.1、目标检测
多年来,基于深度卷积神经网络的目标检测得到了巨大的发展。 关于这一主题有各种各样的综述,涵盖了过去十年中提出的广泛的目标检测技术。 最流行的目标检测框架是Faster R-CNN, You Only Look Once (YOLO)和Single Shot Multi-box Detector (SSD)。 大多数域适配目标检测工作基于Faster-RCNN框架,很少有其他工作使用SSD/YOLO。 最近在域适配目标检测文献中还提出了其他检测框架,即全卷积一阶段(FCOS)目标检测[89]和DEtection TRansformer(DETR)。 然而,这些框架很少用于域适配目标检测器。 下面我们简要介绍一下这三种主要的检测框架,即Faster-RCNN、YOLO和SSD。
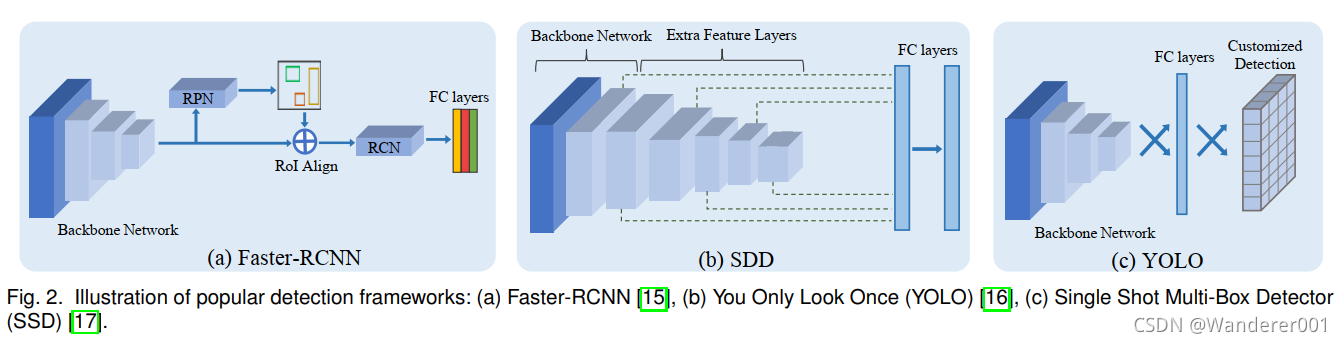
2.1.1 Faster-RCNN
Ren等人[15]提出的Faster-RCNN框架遵循两阶段目标检测方法,该方法由三个主要组件组成,1)共享主干DCNN, 2)区域建议网络(RPN),和3)基于区域兴趣(RoI)的分类器(RCN)。 Faster-RCNN的典型架构如图2(A)所示。 让我们假设一个数据集,![]() ,有
,有![]() 张图片,每一张图片
张图片,每一张图片![]() 都有ground-truth标签
都有ground-truth标签![]() 。这里,ground-truth标签
。这里,ground-truth标签![]() 表示对应图片Xi中的边界框和各自的目标类别。 如图2(a)所示,将输入图像(
表示对应图片Xi中的边界框和各自的目标类别。 如图2(a)所示,将输入图像(![]() )通过卷积网络得到从共享的DCNN中提取的特征图。 然后将这些特征图提供给RPN网络,以获得候选目标建议。 在这里,RPN网络利用多个尺寸和宽高比的预定义锚框来获取候选建议。 随后,每个提议都使用ROI池化转换成固定大小的特征。 最后,利用RCN对每个特征向量进行分类标签预测。 为了训练RPN候选目标,将为每个锚分配一个二进制标签(是否为目标)。 第j个锚被分配一个标签,表示为
)通过卷积网络得到从共享的DCNN中提取的特征图。 然后将这些特征图提供给RPN网络,以获得候选目标建议。 在这里,RPN网络利用多个尺寸和宽高比的预定义锚框来获取候选建议。 随后,每个提议都使用ROI池化转换成固定大小的特征。 最后,利用RCN对每个特征向量进行分类标签预测。 为了训练RPN候选目标,将为每个锚分配一个二进制标签(是否为目标)。 第j个锚被分配一个标签,表示为![]() ,当锚点与其中一个ground-truth框的交集(IoU)最高或锚点与对应图像中的一个ground-truth框的IoU重叠高于0.7时为正(或1)。 类似地,如果所有ground-truth框的IoU比率低于0.3,则给锚分配一个负标签(或0)。 RPN然后负责执行的二进制分类识别候选边界框的提议是否对应于一个图像中的目标和学习之间的抵消真实边界框,表示
,当锚点与其中一个ground-truth框的交集(IoU)最高或锚点与对应图像中的一个ground-truth框的IoU重叠高于0.7时为正(或1)。 类似地,如果所有ground-truth框的IoU比率低于0.3,则给锚分配一个负标签(或0)。 RPN然后负责执行的二进制分类识别候选边界框的提议是否对应于一个图像中的目标和学习之间的抵消真实边界框,表示![]() ,和各自的锚框最后的边界框的预测,表示为
,和各自的锚框最后的边界框的预测,表示为![]() 。 偏移学习是在边界框参数上应用回归损失的帮助下进行监督的。 这两种损失共同造成区域建议网络的最终损失如下:
。 偏移学习是在边界框参数上应用回归损失的帮助下进行监督的。 这两种损失共同造成区域建议网络的最终损失如下:

其中为小批中锚框的索引,
![]() 为分配给各自锚框作为目标的概率。 损失
为分配给各自锚框作为目标的概率。 损失![]()
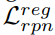 计算给定ground-truth边界框与预测边界框
计算给定ground-truth边界框与预测边界框![]() 之间的平滑L1距离。
之间的平滑L1距离。 ![]() 和
和![]() 都是具有四个包围框参数的向量,即中心x坐标、中心y坐标、高度和宽度来表示一个包围框。 bce为二元交叉熵损失,reg为回归损失,为Faster-RCNN的平滑L1损失。 在这里,
都是具有四个包围框参数的向量,即中心x坐标、中心y坐标、高度和宽度来表示一个包围框。 bce为二元交叉熵损失,reg为回归损失,为Faster-RCNN的平滑L1损失。 在这里,![]() 被归一化为小批量的大小,
被归一化为小批量的大小,![]() 被归一化为包围框位置的数量
被归一化为包围框位置的数量![]() 。
。
然后,训练RCN网络,利用K + 1类分类的交叉熵损失对RoI-pooled特征进行分类,记为![]() RCN。 这里,K表示数据集中类别的数量,其他类表示背景类别。 此外,RCN还负责通过类似于RPN网络的回归损失来预测边界框偏移:
RCN。 这里,K表示数据集中类别的数量,其他类表示背景类别。 此外,RCN还负责通过类似于RPN网络的回归损失来预测边界框偏移:
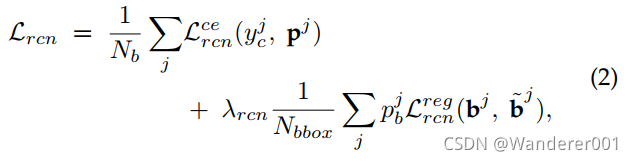
式中![]() 表示第j个RoI-pooled特征的ground-truth类别标签,
表示第j个RoI-pooled特征的ground-truth类别标签,![]() 是预测概率向量,表示分配给所有K + 1类别的概率。 损失
是预测概率向量,表示分配给所有K + 1类别的概率。 损失![]() 为交叉熵损失函数,
为交叉熵损失函数,![]() 损失与RPN网络的损失相同。 最后,利用总体检测损失对模型进行训练,其定义为:
损失与RPN网络的损失相同。 最后,利用总体检测损失对模型进行训练,其定义为:
![]()
关于锚框、边界框回归损失、训练过程和架构的更多细节可以在中找到。 YOLO和SSD框架都是单阶段框架,遵循类似的目标检测方法,只是在其边界框回归损失函数和架构上做了一些修改。
2.1.2、 Single Shot Multi-Box Detector (SSD)
Liu等人提出了SSD检测框架,该框架将每个特征地图位置的边界框输出离散为一组默认框(类似于Faster-RCNN的锚框)。 默认框有不同的长宽比和比例,以更好地匹配图像中的任何物体形状。 此外,SSD结合了来自多个尺度的特征图的预测,以更好地处理与图像相关的目标尺度。 SSD是一种单阶段方法,无需目标建议阶段,与Faster-RCNN方法相比,它更简单、更省时。 我们假设DCNN从任意输入图像X中提取出一个大小为H × W的特征图,SSD中使用的回归损耗是平滑的L1损失,这里表示为![]() 。 对于特征图中的每个单元格,都会有一个与ground-truth边界框相匹配的默认框。 最终的边界框预测是通过在默认框的顶部添加预测偏移量来计算的,并根据匹配的ground-truth边界盒计算回归损失来校正偏移量。 对于给定的第i个预测边界盒
。 对于特征图中的每个单元格,都会有一个与ground-truth边界框相匹配的默认框。 最终的边界框预测是通过在默认框的顶部添加预测偏移量来计算的,并根据匹配的ground-truth边界盒计算回归损失来校正偏移量。 对于给定的第i个预测边界盒![]() 和第j个ground-truth边界框
和第j个ground-truth边界框![]() ,有相应的标签
,有相应的标签![]() ,即分别匹配第i个预测框和第j个ground-truth值时为1。 预测的边界框通过使用默认框计算,并通过计算类似Faster-RCNN的差值来预测与ground-truth框匹配的偏移量。 回归损失为:
,即分别匹配第i个预测框和第j个ground-truth值时为1。 预测的边界框通过使用默认框计算,并通过计算类似Faster-RCNN的差值来预测与ground-truth框匹配的偏移量。 回归损失为:
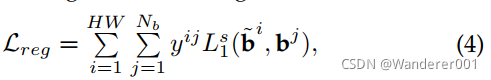
其中![]() 为每张图像的ground-truth边界盒数。
为每张图像的ground-truth边界盒数。![]() 是具有中心x - y位置和高度(h)和宽度(w)的边界盒向量。对于每个预测的边界框,在K + 1个类别上计算一个分类损失,如下所示:
是具有中心x - y位置和高度(h)和宽度(w)的边界盒向量。对于每个预测的边界框,在K + 1个类别上计算一个分类损失,如下所示:
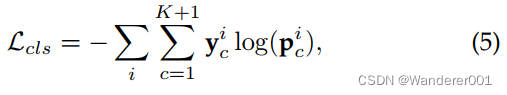
式中![]() 为单热点向量编码,表示类别标签各自的预测边界框,
为单热点向量编码,表示类别标签各自的预测边界框,![]() 为对应的预测概率向量。 c表示第i个边界框属于第c个目标类别的概率。 如前所述,数据集中有K个类别,第K +1个标签表示背景类。 最终的检测损失是回归和分类的结合,定义如下:
为对应的预测概率向量。 c表示第i个边界框属于第c个目标类别的概率。 如前所述,数据集中有K个类别,第K +1个标签表示背景类。 最终的检测损失是回归和分类的结合,定义如下:
![]()
在没有可以与ground-truth边界盒相匹配的预测边界盒的情况下,回归损失被设为零。 关于默认框、框匹配算法边界框回归损失、训练过程和架构细节的更多细节可以在[17]中找到。
2.1.3 You Only Look Once (YOLO)
Redmon等人提出了一种单阶段统一检测模型YOLO,该模型将目标分类器重新用于目标检测任务。 在YOLO中,使用单个检测模型来预测在一次向前传递中包围框参数和目标类概率。 这使得YOLO比Faster-RCNN更省时。 典型的YOLO检测模型如图2(b)所示。 YOLO模型背后的主要思想是将输入图像![]() 划分为S × S网格,网格中的每个单元最多可以预测B个边界框。 每个网格单元预测两个概率得分,即预测的边界框(
划分为S × S网格,网格中的每个单元最多可以预测B个边界框。 每个网格单元预测两个概率得分,即预测的边界框(![]() )是否为目标,即
)是否为目标,即![]() ,假设预测的边界框为目标,则为数据集中所有K个类别的概率得分向量。 网格中每个单元格的边界框预测由与单元格重叠的ground-truth边界框监督。 对整个网络进行监督,检测损失定义如下:
,假设预测的边界框为目标,则为数据集中所有K个类别的概率得分向量。 网格中每个单元格的边界框预测由与单元格重叠的ground-truth边界框监督。 对整个网络进行监督,检测损失定义如下:
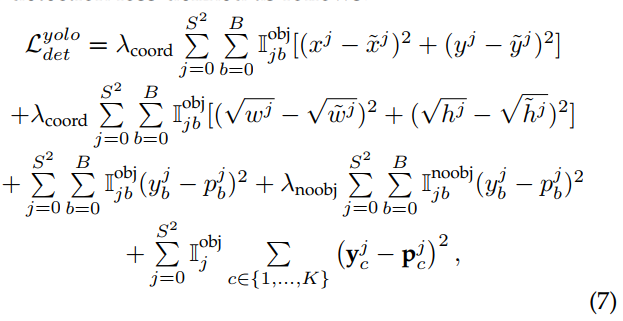
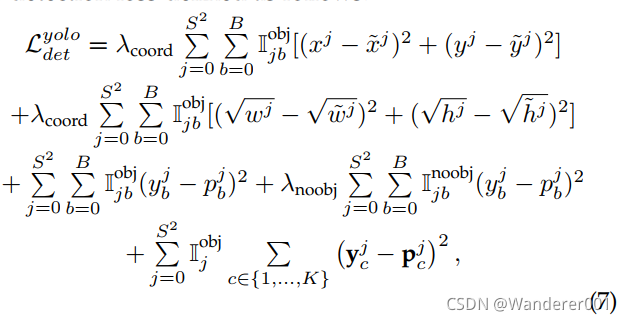
式中,![]() 和
和![]() 分别为平衡回归损失和非物体边界框概率损失的超参数。
分别为平衡回归损失和非物体边界框概率损失的超参数。 ![]() 是第b个边界框包含该目标的概率。
是第b个边界框包含该目标的概率。![]() 表示S × S网格中第j个单元预测的第b个包围框上的二进制标签。
表示S × S网格中第j个单元预测的第b个包围框上的二进制标签。 ![]() 表示一个热向量编码目标类别标签,其中向量中的一个元素为1,其余元素为0,表示目标的标签。
表示一个热向量编码目标类别标签,其中向量中的一个元素为1,其余元素为0,表示目标的标签。 ![]() 是预测概率向量,表示分配给所有K个类别的概率。
是预测概率向量,表示分配给所有K个类别的概率。 ![]() 是一个指示函数,当该cell位置的第j个grid-cell和第b个预测的边界框与输入图像Xj对应的ground-truth边界框重叠时,
是一个指示函数,当该cell位置的第j个grid-cell和第b个预测的边界框与输入图像Xj对应的ground-truth边界框重叠时,![]() 设为1。 类似地,
设为1。 类似地,![]() 是一个不属于图像中任何目标的边界框的指示函数。
是一个不属于图像中任何目标的边界框的指示函数。
2.2、域适配
在域适配问题中,我们考虑两个数据集域,即源域和目标域,分别表示为![]() 和
和![]() 。 假设源域和目标域有不同的数据分布,即
。 假设源域和目标域有不同的数据分布,即![]() 。 大多数域适配范式认为源域数据集是标签丰富的,而目标域数据集在本质上是标签稀缺的。 文献中经常研究的域适配表述的多种变体包括半监督、弱监督和无监督域适配。 在目标检测任务的背景下,半监督域自适应表述假设源域完全被包围框标注和相应的类别标注,只有目标域样本的子集被包围框标注和各自的类别标注。 弱监督域适配范式假设源域是完全标注的,所有目标域样本都有表示存在/不存在任何类别和无边框标注的二进制标注。 最后,无监督域域适配假设源域是完全标注的,而目标域没有标注。 在这些范式中,无监督公式更加实用,也可以采用相应的方法来解决半监督和弱监督的问题。 由于这些原因,我们主要关注于回顾针对目标检测任务的无监督域适应的工作。 在接下来的内容中,我们将正式定义无监督域自适应公式,并提供相同的简要概述。
。 大多数域适配范式认为源域数据集是标签丰富的,而目标域数据集在本质上是标签稀缺的。 文献中经常研究的域适配表述的多种变体包括半监督、弱监督和无监督域适配。 在目标检测任务的背景下,半监督域自适应表述假设源域完全被包围框标注和相应的类别标注,只有目标域样本的子集被包围框标注和各自的类别标注。 弱监督域适配范式假设源域是完全标注的,所有目标域样本都有表示存在/不存在任何类别和无边框标注的二进制标注。 最后,无监督域域适配假设源域是完全标注的,而目标域没有标注。 在这些范式中,无监督公式更加实用,也可以采用相应的方法来解决半监督和弱监督的问题。 由于这些原因,我们主要关注于回顾针对目标检测任务的无监督域适应的工作。 在接下来的内容中,我们将正式定义无监督域自适应公式,并提供相同的简要概述。
2.2.1、无监督域适配
我们将源域数据集表示为![]()
![]() 。 这里,源数据集有
。 这里,源数据集有![]() 个图像,
个图像,![]() 表示第i张图像,
表示第i张图像, ![]() 表示对应的带类别标签的边界框注释。 同样,我们将目标域数据集表示为,
表示对应的带类别标签的边界框注释。 同样,我们将目标域数据集表示为,![]() ,有
,有![]() 个没有ground-truth注释的目标域图像。 Ben等人提出了一个框架来执行领域自适应给定设置,即标记源数据集和未标记目标数据集,目标性能的理论上界。 Ben等设计了
个没有ground-truth注释的目标域图像。 Ben等人提出了一个框架来执行领域自适应给定设置,即标记源数据集和未标记目标数据集,目标性能的理论上界。 Ben等设计了![]() 来度量两组数据分布不同的样本之间的散度,域自适应问题也是如此。 我们考虑任意源域图像
来度量两组数据分布不同的样本之间的散度,域自适应问题也是如此。 我们考虑任意源域图像![]() 和任意目标域图像
和任意目标域图像![]() 。 此外,让我们考虑一个域鉴别器,记为:
。 此外,让我们考虑一个域鉴别器,记为:![]() ,它取任意图像
,它取任意图像![]() ,并预测输入图像的域。 将源域图像
,并预测输入图像的域。 将源域图像![]() 划分为标签0,目标域图像
划分为标签0,目标域图像![]() 划分为标签1。 考虑H是一组可能的域鉴别器,
划分为标签1。 考虑H是一组可能的域鉴别器,![]() 可以定义为:
可以定义为:
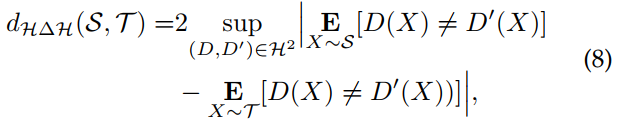
其中![]() 和
和![]() 分别表示源和目标域数据集上的预期域分类错误。 更准确地说,式8测量了从
分别表示源和目标域数据集上的预期域分类错误。 更准确地说,式8测量了从![]() 取样的假设的不一致而产生的散度。理想联合假设被定义为,
取样的假设的不一致而产生的散度。理想联合假设被定义为,![]()
![]() 。
。
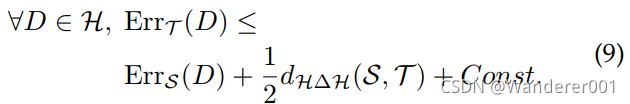
从式9可以看出,目标误差的上限为3项,即源域上的预期预测误差、式8中的域散度和少数常数项。 关于式8和式9的更多细节都包括证明提供。 文献中大部分的域自适应工作都依赖于这一公式,并侧重于通过减少源域和目标域之间的域发散来最小化上界。 在接下来的内容中,我们将讨论文献中专门用于解决目标检测任务的不同策略。
3、方法
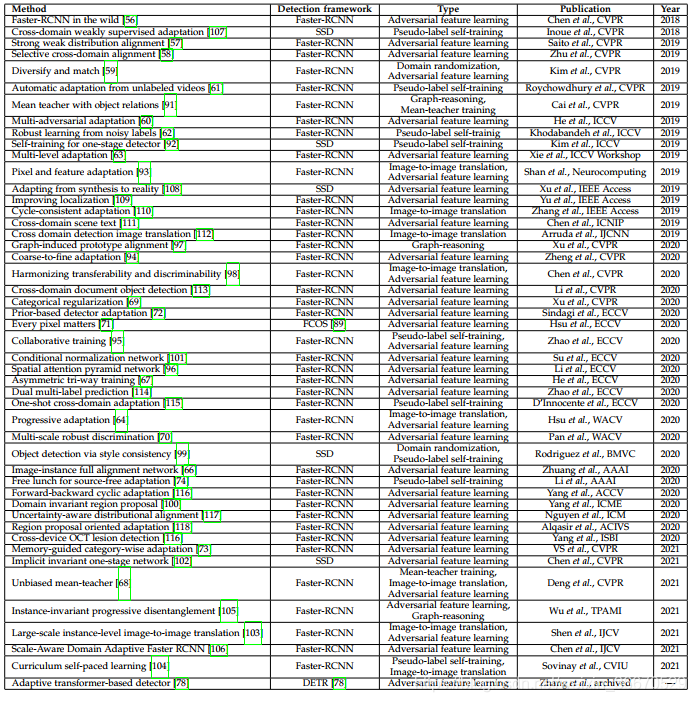
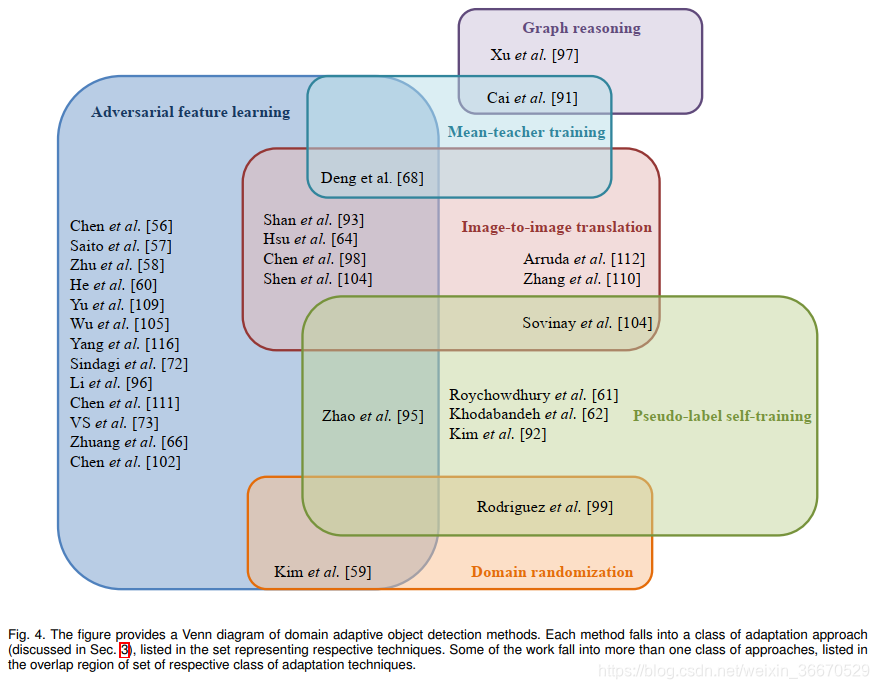
如前所述,在域适配目标检测任务中,已经提出了多种方法。 经过对这些方法的仔细回顾,我们将它们分为以下几类:1)、对抗性特征学习,2)、图像到图像的翻译,3)、领域随机化,4)、伪标签自我训练,5)、均值-教师训练,6)图推理。 表1列出了现有方法的全面列表。 图4说明了各种方法的分类。 下面,我们将讨论多年来提出的与各类别有关的最重要文件。
3.1、对抗特征学习
3.1.1、通过梯度倒转来进行特征学习
对抗性特征学习基于Ben等人提出的理论(详见第2.2.1节)。 具体来说,总体策略是通过直接最小化![]() 来最小化式9中给出的上界。 由式8中给出的
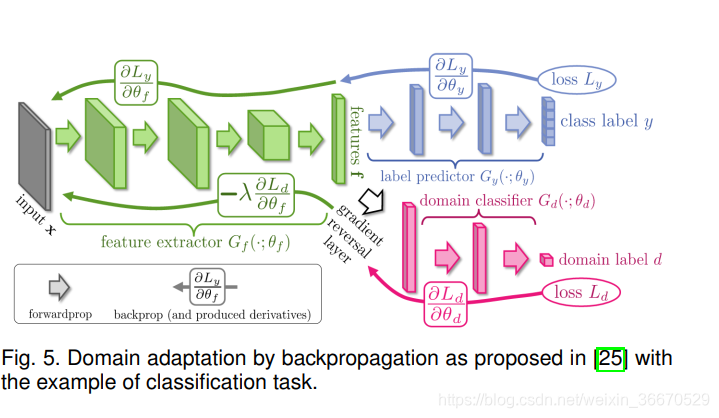
来最小化式9中给出的上界。 由式8中给出的![]() 可以看出。 该距离与域分类器d的错误率成反比。域自适应场景的目标是减少该距离,即增加域分类器的错误率。 Ganin等人利用这一点提出了一种新的梯度反转方法来训练任何神经网络模型进行域自适应。 其总体目标是在基于神经网络的域分类器的帮助下实现主干网的域不变特征空间。 假设我们将一个域分类器网络表示为D,骨干特征提取网络表示为F。 在这种情况下,特征提取网络也试图增加域分类器的损失。 网络F试图最小化特定任务的损失(分类/分割/检测损失),最大化整个训练管道中的域分类损失。 对网络D进行训练,使域分类损失最小化。 除了特定于任务的损失外,还添加了涉及域分类的额外丢失。 这种损失称为对抗性损失[25],可以记为:
可以看出。 该距离与域分类器d的错误率成反比。域自适应场景的目标是减少该距离,即增加域分类器的错误率。 Ganin等人利用这一点提出了一种新的梯度反转方法来训练任何神经网络模型进行域自适应。 其总体目标是在基于神经网络的域分类器的帮助下实现主干网的域不变特征空间。 假设我们将一个域分类器网络表示为D,骨干特征提取网络表示为F。 在这种情况下,特征提取网络也试图增加域分类器的损失。 网络F试图最小化特定任务的损失(分类/分割/检测损失),最大化整个训练管道中的域分类损失。 对网络D进行训练,使域分类损失最小化。 除了特定于任务的损失外,还添加了涉及域分类的额外丢失。 这种损失称为对抗性损失[25],可以记为:
![]()
其中H为领域分类器的假设空间,F为特征提取网络。 ![]() 和
和![]() 分别表示源域和目标域的期望域分类误差。 如图5所示,在域分类器输入之前应用梯度反转层来实现式10。 前馈过程中的梯度反转层作为恒等函数,反向传播过程中梯度乘以−1。 实际上,这迫使特征提取器F最大化域分类损失,同时最小化特定任务的损失,从而产生域不变特征空间,这一点由Ben等人证明。 所有的方法都利用该策略来适应一个使用标记源和未标记目标域的检测器模型,并将其归入对抗性特征学习范畴 。
分别表示源域和目标域的期望域分类误差。 如图5所示,在域分类器输入之前应用梯度反转层来实现式10。 前馈过程中的梯度反转层作为恒等函数,反向传播过程中梯度乘以−1。 实际上,这迫使特征提取器F最大化域分类损失,同时最小化特定任务的损失,从而产生域不变特征空间,这一点由Ben等人证明。 所有的方法都利用该策略来适应一个使用标记源和未标记目标域的检测器模型,并将其归入对抗性特征学习范畴 。
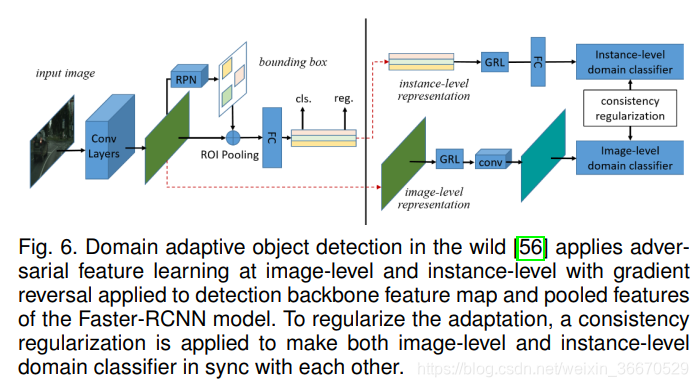
3.1.2、通过对抗训练来进行域适应检测
Chen等人是第一个在目标检测任务中提出域自适应问题的人。 他们的方法框图如图6所示。 可以看到,他们的方法采用了第3.1.1节中描述的梯度反转层的对抗训练。 考虑到第2.2.1节中讨论的关于源S和目标T域的问题设置,该方法利用Faster-RCNN检测框架,并提出在检测框架的多个阶段利用梯度反转训练。 具体来说,在检测模型中给出一个骨干网![]() 、RCN网络
、RCN网络![]() 和RPN网络
和RPN网络![]() ,它们对从骨干网
,它们对从骨干网![]() 中提取的图像级特征和从RCN网络
中提取的图像级特征和从RCN网络![]() 中提取的实例级特征都进行了对抗训练。 假设从主干中提取的特征大小为
中提取的实例级特征都进行了对抗训练。 假设从主干中提取的特征大小为![]() ,其中C表示通道数量,H和W分别表示特征图的高度和宽度。 将图像级和实例级用于对抗训练的鉴别器网络分别表示为
,其中C表示通道数量,H和W分别表示特征图的高度和宽度。 将图像级和实例级用于对抗训练的鉴别器网络分别表示为![]() 和
和![]() 。 然后定义图像级域分类损失为:
。 然后定义图像级域分类损失为:
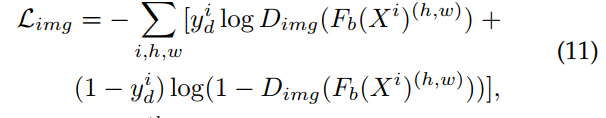
其中i表示batch中的第i个图像,![]()
![]() 表示位置
表示位置![]() 在特征图中。 鉴别器网络
在特征图中。 鉴别器网络![]() 的输出是指示给定图像是来自源域还是目标域的概率分数。 这里是
的输出是指示给定图像是来自源域还是目标域的概率分数。 这里是![]() 表示域标签为0,当为
表示域标签为0,当为![]() 和1时,当为
和1时,当为![]() 时。 类似地,实例级域分类损失可以描述为:
时。 类似地,实例级域分类损失可以描述为:
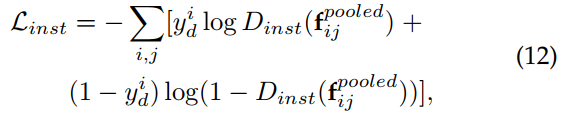
其中![]() 表示来自图像
表示来自图像![]() 的第j个目标提议的大小为1 × d的ROI池化特征。 由于图像和实例域鉴别器网络都是独立训练的,并且对于任何图像
的第j个目标提议的大小为1 × d的ROI池化特征。 由于图像和实例域鉴别器网络都是独立训练的,并且对于任何图像![]() 都应该产生相同的域预测,Chen等人引入了一种正则化,使域鉴别器的预测保持一致。 这个一致性正则化被定义为:
都应该产生相同的域预测,Chen等人引入了一种正则化,使域鉴别器的预测保持一致。 这个一致性正则化被定义为:
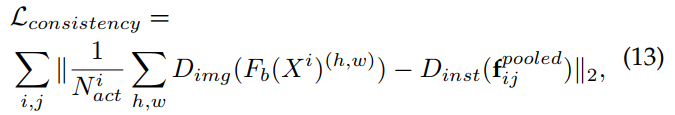
其中![]() 表示给定图像
表示给定图像![]() 的特征图
的特征图![]() 中的激活次数,
中的激活次数,![]() 表示
表示范数。让我们将整个检测模型表示为
![]()
![]() 。结合所有这些损失函数,最终训练目标如下:
。结合所有这些损失函数,最终训练目标如下:
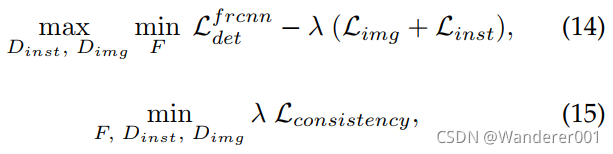
其中![]() 是用于平衡对抗损失和一致性损失的权衡参数。 用最终目标方程(式14和式15)训练检测网络和鉴别网络。 总结最终目标,检测网络F的目标是最小化检测损失,最大化图像级和实例级域分类损失。 鉴别网络的目标是最小化域分类损失。 请注意,检测器和鉴别器都以最小化一致性损失为目标。 检测损失仅适用于源数据,因为目标数据没有任何标签注释。 对已标记源数据和未标记目标数据分别进行了域分类损失和一致性正则化。
是用于平衡对抗损失和一致性损失的权衡参数。 用最终目标方程(式14和式15)训练检测网络和鉴别网络。 总结最终目标,检测网络F的目标是最小化检测损失,最大化图像级和实例级域分类损失。 鉴别网络的目标是最小化域分类损失。 请注意,检测器和鉴别器都以最小化一致性损失为目标。 检测损失仅适用于源数据,因为目标数据没有任何标签注释。 对已标记源数据和未标记目标数据分别进行了域分类损失和一致性正则化。
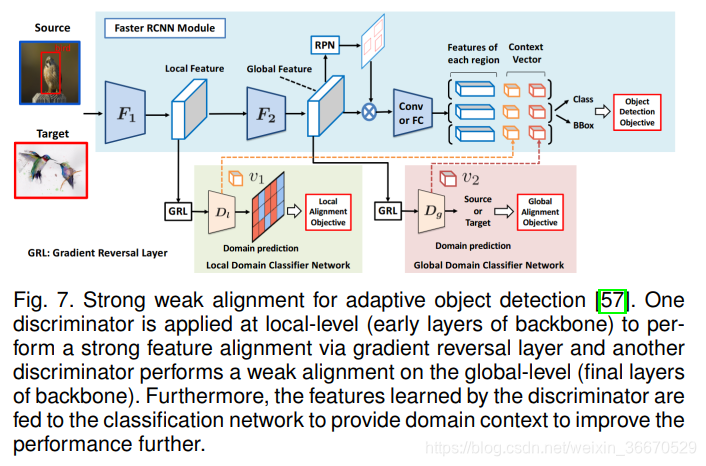
Saito等人认为在骨干网的多个层次上直接应用梯度反转并不一定是最优的。 由于骨干的较浅的卷积层捕获局部信息,直接应用对敌损失将有利于学习源和目标数据之间的域不变局部特征,他们称之为强对齐。 此外,由于骨干中较深的层捕获全局信息,执行强对齐将不是最佳的原因。 例如,当源域和目标域数据从不同的城市采样时,场景中的目标数量、目标共现、场景布局等可能会有很大的不同。 考虑源域图像只包含一个目标,而目标图像包含多个目标的情况,强对齐有不对齐的风险。 为了解决这个问题,论文[57]修改了全局层次(后面的层次)的对抗性损失,用Focal Loss代替了传统使用的二元交叉熵损失。 这种策略在论文[57]中被称为弱对齐。 整体方法同时利用局部强对齐和全局弱匹配来减小源数据和目标数据之间的域间隙,从而提高目标图像的检测性能。 假设一个检测骨干网络![]() 分为两个级联网络,即全局特征提取器
分为两个级联网络,即全局特征提取器![]() 和局部特征提取器
和局部特征提取器,使
![]() 。 强对齐的对抗性损失定义为:
。 强对齐的对抗性损失定义为:
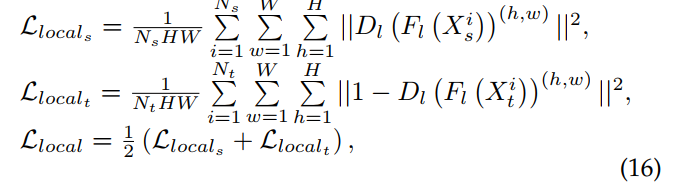
其中![]() 为局部域判别器,
为局部域判别器,![]() 和
和![]() 分别为源例数和目标例数, 其中
分别为源例数和目标例数, 其中![]() 和
和![]() 分别是应用于源域图像和目标域图像的弱全局对齐损失,
分别是应用于源域图像和目标域图像的弱全局对齐损失,![]() 分别是源域和目标域的局部特征图。表示全局鉴别器网络为
分别是源域和目标域的局部特征图。表示全局鉴别器网络为![]() ,弱对准损失定义为:
,弱对准损失定义为:
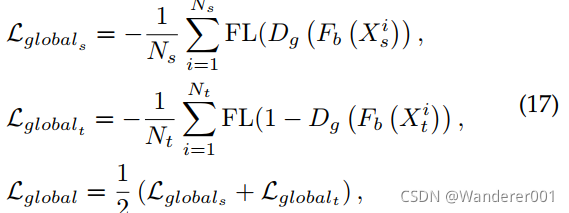
其中![]() 和
和![]() 分别是应用于源域图像和目标域图像的弱全局对齐损失。
分别是应用于源域图像和目标域图像的弱全局对齐损失。 ![]() 提取全局特征,
提取全局特征,![]() 表示全局特征来自源域或目标域的概率。 FL表示焦损失,定义为:
表示全局特征来自源域或目标域的概率。 FL表示焦损失,定义为:
![]()
其中![]() 是一个焦点损失参数,控制难以分类的例子的权重。 具体来说,γ > 1的值对容易样品分配低损失值,对难样品分配高损失值,从而在训练时以难样本为重点。 这样,在全局层次上使用梯度反转层进行对抗性训练时,会使难目标样本更加集中,而容易分类的目标样本不会被迫与源域对齐。 本文用这种强弱对齐策略论证了Faster-RCNN框架中的适应性,并具体说明了弱对齐在全球层面上的意义。 此外,为了进一步提高局部和全局域鉴别器的性能,将
是一个焦点损失参数,控制难以分类的例子的权重。 具体来说,γ > 1的值对容易样品分配低损失值,对难样品分配高损失值,从而在训练时以难样本为重点。 这样,在全局层次上使用梯度反转层进行对抗性训练时,会使难目标样本更加集中,而容易分类的目标样本不会被迫与源域对齐。 本文用这种强弱对齐策略论证了Faster-RCNN框架中的适应性,并具体说明了弱对齐在全球层面上的意义。 此外,为了进一步提高局部和全局域鉴别器的性能,将![]() 和
和![]() 与RCNN特征相连接,添加领域特定的上下文信息用于目标分类,如图7所示。 网络的最终目标定义为:
与RCNN特征相连接,添加领域特定的上下文信息用于目标分类,如图7所示。 网络的最终目标定义为:
![]()
其中λ为折中超参数,F为整个检测网络。
到目前为止所讨论的方法的一个主要缺点是,它们试图利用整个特征图来执行对齐。 然而,更优的方法是对检测中目标对应的区域进行特征对齐。 Zhu等人的方法基于这一观察结果,通过挖掘有区别的区域,选择性地对齐源域和目标域数据的特征。 为此,作者利用了Faster-RCNN检测框架的区域提议网络。 他们的方法分为两部分,即“看哪里”和“如何对齐”,如图8所示。 在“where to look”阶段,RPN网络生成的区域建议被挖掘,以在特征图中找到组。 为了克服RPN网络的噪声建议,利用这些建议的中心坐标进行K-means聚类。 通过K-means得到的聚类中心被用作分组区域。 基于这些挖掘出的组,将固定数量的特征重新分配给每个组(即聚类簇)。 与其使用梯度反转层对这些分组特征进行对齐,不如使用基于生成对抗网络的策略通过生成执行间接特征对齐。 在分类[39]的情况下,一种类似的策略被证明是有效的。 具体来说,它们利用一组特征通过域内(即![]() )和跨域(即
)和跨域(即![]() )重建。 将域特指定生成器分别表示为
)重建。 将域特指定生成器分别表示为![]() 和
和![]() ,域指定鉴别器分别表示为源域和目标域的
,域指定鉴别器分别表示为源域和目标域的![]() 和
和![]() ,则patch重建对抗性联合损失定义为:
,则patch重建对抗性联合损失定义为:
![]()
在这里,损失函数![]() 和
和![]() 是域内损失,通过将真实输入预测为真实输入,将虚假输入预测为虚假输入,试图最小化补丁的真实/虚假分类损失。 相比之下,对于生成器网络损失
是域内损失,通过将真实输入预测为真实输入,将虚假输入预测为虚假输入,试图最小化补丁的真实/虚假分类损失。 相比之下,对于生成器网络损失![]() 和
和![]() 则试图欺骗鉴别网络,迫使它们在同一域内将假识别为真,将真识别为假。 检测模型F以最小化跨域patch重建损失为目标,即将假源划分为真源,将假目标划分为真源。 [39],[124]在分类任务中也使用了类似的策略。 通过最小化跨域patch重建,网络F将学习一个域不变的特征空间,从而减少源域和目标域之间的差距。 这一策略与前面解释的梯度反转训练密切相关。 然而,这种损失并不是直接在特征空间上应用对抗性损失,而是应用于重建的patch图像。 此外,还添加了一个权值估计网络
则试图欺骗鉴别网络,迫使它们在同一域内将假识别为真,将真识别为假。 检测模型F以最小化跨域patch重建损失为目标,即将假源划分为真源,将假目标划分为真源。 [39],[124]在分类任务中也使用了类似的策略。 通过最小化跨域patch重建,网络F将学习一个域不变的特征空间,从而减少源域和目标域之间的差距。 这一策略与前面解释的梯度反转训练密切相关。 然而,这种损失并不是直接在特征空间上应用对抗性损失,而是应用于重建的patch图像。 此外,还添加了一个权值估计网络![]() 来平衡源域和目标域的对抗性损失。 用二元交叉熵损失训练权值估计网络。 将源域和目标域roi池特征组分别表示为
来平衡源域和目标域的对抗性损失。 用二元交叉熵损失训练权值估计网络。 将源域和目标域roi池特征组分别表示为![]() 和
和![]() ,定义权值估计损失为:
,定义权值估计损失为:
![]()
使用权值估计网络的主要好处是,它根据目标patch与源域patch的相似性来权衡对齐损失。 如果我们将目标域合并特征的权值估计网络的输出表示为![]() ,则该方法的最终目标函数为:
,则该方法的最终目标函数为:
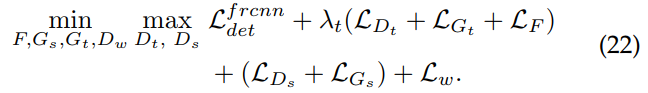
网络训练分阶段进行,分别更新监督检测损失、鉴别器损失、权值损失、跨域损失和域内生成损失。
3.1.3、权重对抗特征对齐
基于对抗性特征学习的自适应检测文献的大部分工作都集中在改进梯度反转训练以获得更好的特征对齐。 各种方法都建立在前面讨论的方法的基础上,并广泛遵循引入一个模块,通过损失加权来控制梯度反转信息流,以及使用正则化技术来补充所提出的加权模块的策略。 如Zheng等在检测骨干网的多个层次上应用域分类器,利用梯度反转层进行对抗性特征学习,如图9所示。 然后将这些对抗性损失乘以从骨干网中提取的权重。 为了获得权重,将骨干网的最终特征图在通道维度上平均,以获得突出显示潜在有目标的区域的注意图。 这些权值被用来调节对抗性损失,这种策略被称为基于注意的区域转移(ART)。 此外,借助源真实边界框和目标域的预测对象建议,通过特征平均学习类别特定原型。 在每一步中,每个类别的源域原型和目标域原型都通过原型相似度的损失进行对齐,该策略被称为原型相似度对齐(PSA)。 由于ART的丢失,梯度反转训练可以去除非目标区域的噪声信息,从而获得更好的对齐效果,而原型对齐在适应目标域的同时保持了语义一致性。
类似地,He等人提出了一种Multi-Adversarial Faster-RCNN (MAF)方法,扩展了[56]的工作。 MAF的第一个变化是在骨干网的多层应用图像级对齐。 此外,减少了通道维度中的特性映射,以对齐聚合的信息,而不是单个组件。 MAF还包括实例级对齐,但与[56]不同的是,它将实例对抗损失与RCN网络产生的预测概率进行加权。 图10给出了MAF的总体方法。
Xu等人提出了一种分类正则化策略,该策略可与基于对抗性特征学习的方法相结合,以进一步增强源域和目标域之间的特征对齐。 分类正则化策略利用了来自已标记源域数据的实例级注释,并在检测损失之外增加了多标签分类损失,如图11所示。 该策略可以通过多标签分类器提取特征映射中目标的弱定位。 然后利用弱定位地图来屏蔽图像级域分类损失,在突出目标区域的同时屏蔽不必要的信息。 本文将这种通过弱定位的图像级加权称为图像级分类正则化(ICR)。 随后,将实例级正则化应用于ROI池化特性。 具体来说,利用RCN预测概率与相应的集合特征的类别对应的多标签分类概率的差值对实例级域分类损失进行加权。 这种正则化在文中被称为范畴一致性正则化(CCR)损失。 徐等人通过修改[56]和[57]对齐策略,加入ICR和CCR损失函数,证明了所提分类正则化的有效性。
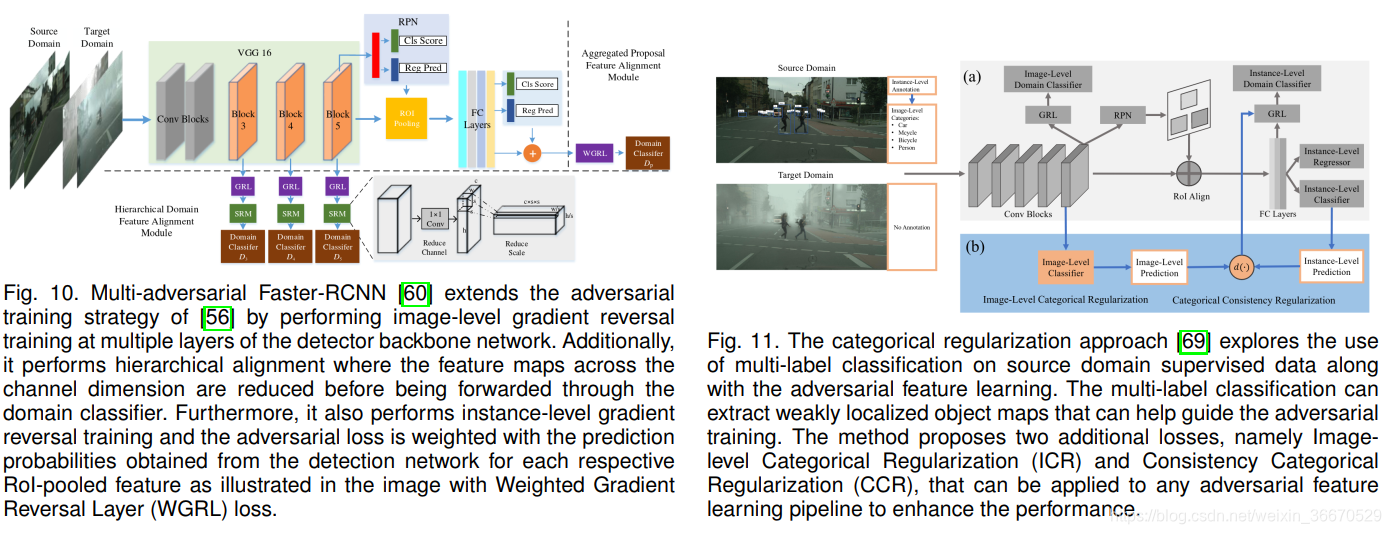
Zhao等人将多标签分类策略与弱全局对齐策略相结合。 具体来说,在源标记数据的帮助下,多标记分类器和检测网络一起额外训练。 多标签分类器预测的概率分数用于约束骨干网最后一层的域鉴别器。 该调节机制利用多线性映射函数,将从骨干网提取的特征映射和表示所有K个目标在图像中的概率的多标签概率向量结合起来。 弱全局对齐采用与相似的策略,即利用Focal Loss进行全局特征对齐。 为了进一步规范化特征对齐训练,通过对称Kullback-Leibler散度最小化多标签分类器的重构预测概率评分向量与RCN网络预测概率评分之间的距离。
Sindagi等人将不利天气条件视为领域适应性的一个特殊案例,并提出了基于先验的对抗性损失。 他们认为,在恶劣天气的情况下,可以使用定义良好的模型,用数学公式计算相机如何捕捉各自的条件。 利用这些模型,他们提取了在论文中称为“先验”的特定天气信息。 然后利用这些先验将传统的域分类损失修改为先验预测损失。 该训练遵循类似的策略,使用之前的预测损失执行梯度反转基于层对齐。 即检测模型的骨干网尽量使先验预测损失最大化,而先验预测网络尽量使其最小化。 在他们的论文中,这种策略被称为事先对抗性训练,并被证明是有效的,特别是在雾蒙蒙和多雨的天气条件下。
与现有的域自适应目标检测方法相比,Hsu等[71]没有使用Faster-RCNN检测框架,而是采用了FCOS[89]单阶段检测框架,该框架在监督检测中除了目标分类和边界盒回归损失外,还存在中心损失。 Hsu等人[71]专门利用FCOS框架提出了一种中心感知的特征对齐策略。 由于FCOS是用标记源数据的中心损失来训练的,因此它提供了一个显示目标位置的中心聚焦热图的粗略预测。 他们利用这个中心信息来创建一个类别不可知的目标特征图,并将其与骨干网的最终特征地图联系起来。 在各自的特征映射上分别应用全局和中心感知的鉴别器进行领域分类。 对齐是通过基于梯度反转层的对抗训练进行的,其中域鉴别器负责中心感知特征对齐,同时剔除背景中的任何噪声信息,更多地关注对象实例的突出部分。 与其他方法相似,特征对齐在骨干网的多个层次上进行。
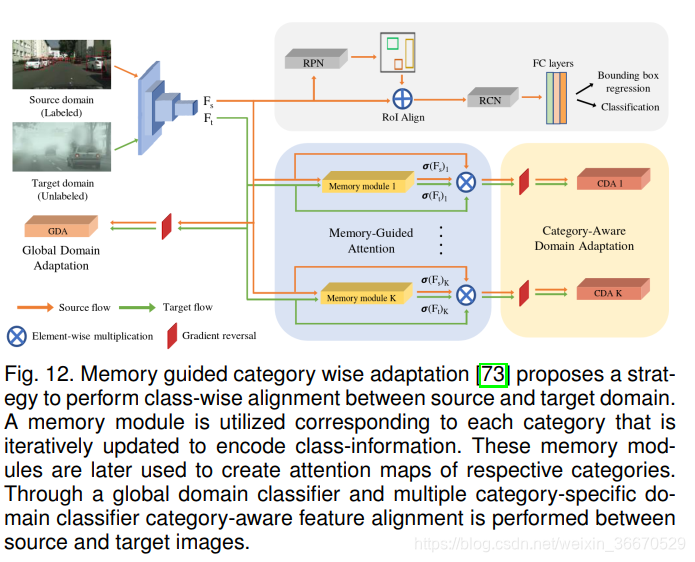
VS等人指出,现有的基于对抗性学习的方法容易出现类别负迁移问题。 梯度反转训练和域分类器训练只能保证特征成为域不变性。 然而,当源域和目标域都包含多个类别时(通常是这种情况),目标特性和源特性的不同类别之间有可能不一致。 VS等人[73]通过提出记忆引导注意的类别意识域适应(MeGA-CDA)来解决负迁移的问题。 他们的关键思想是利用K + 1类别特定的领域鉴别器来分别对齐每个类别。 但是,目标数据集的标签信息是不可用的,这禁止使用特定于类别的域标识符。 为了克服这一问题,作者在骨干网提取的特征图中引入了一个存储模块,生成关注各自类别特征的注意图,同时屏蔽来自其他类别的信息。 图12说明了他们使用内存模块生成特定于类别的信息的总体方法及其在特定于类的领域对齐中的后续用法。 记忆模块与网络的其他组件一起进行训练,这种端到端的训练确保了类别特定的注意图在训练过程中逐步得到改进。 请注意,它们还使用与类别无关的域对齐,这与[57]的强对齐策略类似。 这确保了源域和目标域之间的总体特性映射是一致的,而附加的特定于类别的鉴别器通过执行类对齐来防止负迁移。
假设![]() 为检测模型的骨干网络,
为检测模型的骨干网络,![]() 和
和![]() 分别为任意源域图像和目标域图像,本节讨论的大多数方法所使用的典型加权域分类损失(
分别为任意源域图像和目标域图像,本节讨论的大多数方法所使用的典型加权域分类损失( ![]() )可以表示为:
)可以表示为:
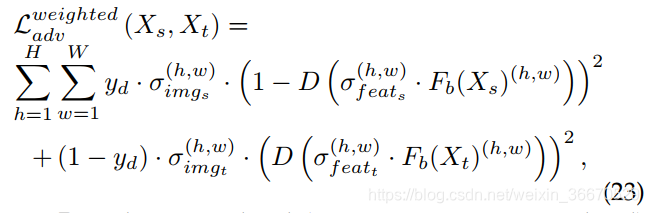
其中D是图像级(在某些情况下是实例级)域分类器,![]() 为域标签,源域为1,目标域为0,
为域标签,源域为1,目标域为0,![]() ;
; ![]()
![]() 是应用于域分类损失的图像级权重,
是应用于域分类损失的图像级权重,![]() ;
; ![]() 是用于屏蔽无关信息和突出显示有助于源和目标域对齐的重要特性的特征级权重。 根据方法的不同,将
是用于屏蔽无关信息和突出显示有助于源和目标域对齐的重要特性的特征级权重。 根据方法的不同,将![]() 或
或![]() 设置为一样的,并将图像级或特征级的权重应用于损失计算。 [94]、[60]、[69]、[72]、[114]等方法仅利用
设置为一样的,并将图像级或特征级的权重应用于损失计算。 [94]、[60]、[69]、[72]、[114]等方法仅利用![]() 权值来适当平衡敌对损失。 而其他方法,如[71],[73]只应用特性级别的权重σfeat。 每种方法的贡献来自于对
权值来适当平衡敌对损失。 而其他方法,如[71],[73]只应用特性级别的权重σfeat。 每种方法的贡献来自于对![]() 和
和![]() 的建模方式。 例如,Xu等人利用多标签分类概率向量对
的建模方式。 例如,Xu等人利用多标签分类概率向量对![]() 进行建模,VS等人利用特定类别记忆模块对
进行建模,VS等人利用特定类别记忆模块对![]() 进行建模。
进行建模。
3.1.4、额外的方法
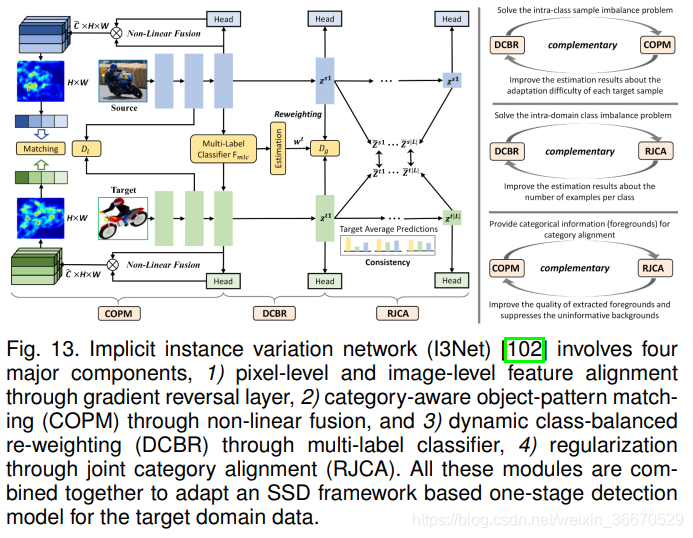
Chen等人[为SSD检测框架提供了一种对齐源域和目标域特征的策略,称为I3Net。 它们的主要策略类似于多级域鉴权器,在像素级和图像级进行对齐,如图13所示。 此外,用于训练图像级鉴别器的图像级域损失由多标签分类器获得的概率进行加权,类似于。 此外,I3Net通过利用SSD架构来实现对象模式匹配,SSD架构可以预测从骨干网中提取的每个特征地图位置的概率。 然后,这些特定于类别的概率映射将在各自类别的源域图像和目标域图像之间进行匹配,以加强源域激活和目标域激活之间的一致性。 通过最小化类内距离和最大化类间距离,类别特征得到了进一步的改进。 通过SSD检测框架获得的分类概率模式计算原型,并通过指数移动平均更新。
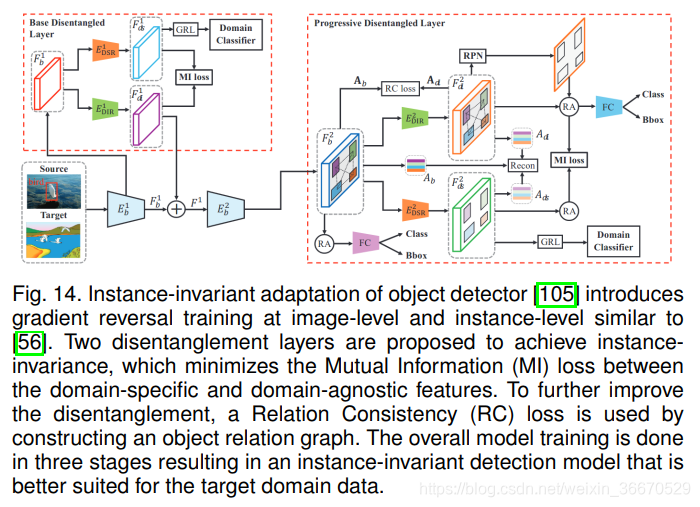
Wu等人指出,特征级或像素级对齐策略存在忽视实例级目标特征的风险。 为了实现这一点,需要将通过训练学到的特性分解为领域不变的和领域特定的部分。 Wu等人[105]提出了一种渐进解缠策略,对Fast RCNN进行分期训练。 如图14所示,采用图像级和实例级域分类器,梯度反转层类似[56]。 将互信息损失应用于分离的特征上,从领域特有的特征中分离出领域不变的特征。 MI损失公式借鉴了互信息神经估计(MINE)方法。 具体来说,基于mine的MI损失将难以处理的互信息最大化转化为可端到端训练的易于处理的二值分类目标。 为了进一步规范化训练,通过考虑原始的和领域不变的特征映射,对每幅输入图像利用领域不变特征创建目标关系图。 由于这两个特征都是从同一幅图像中提取的,所以它们在各自的位置上包含相同的目标。 因此,为了维护跨两个特性映射的类间关系,必须损失目标关系一致性(RC)。
随后的一些研究如[66]、[76]、[63]、[54]、[96]、[70]、[100]、[106]利用了本节讨论的对抗性特征学习策略。 这些方法大多用于自动驾驶/监控应用的跨域检测。 一些在其他应用中解决域漂移问题的著名工作包括Yang等人,该作品借助基于梯度反转层的对抗训练实现OCT病变检测,解决了医疗任务中的检测器适配问题。 在其他任务中,Chen等人提出了类似的对抗特征训练,将场景文本检测模型从合成数据适应到室外设置, Li等人利用应用于骨干网多个卷积层的多级特征对齐来训练一个用于文档跨域检测的检测器。 此外,Li等人建立了文档空间跨域检测任务的基准。 在不同类型的领域自适应检测技术中,对抗特征学习是最流行的方法,有不同的变体。
3.2、用伪标签进行自训练
利用基于伪标签的监督在目标域上对目标检测器进行自训练是使源训练模型适应目标域的最简单方法之一。 给定一个源预训练的检测模型![]() ,该模型在标注的源域数据集
,该模型在标注的源域数据集![]() 上进行训练,用于在目标域数据
上进行训练,用于在目标域数据![]() 上生成伪标签。 伪标签
上生成伪标签。 伪标签![]() ,与目标数据集的图像组成一个新的数据集
,与目标数据集的图像组成一个新的数据集![]() 。 其中
。 其中![]() 表示由源训练的检测器模型
表示由源训练的检测器模型![]() 对第i个目标域图像
对第i个目标域图像![]() 获得的伪标签。 自训练通常包括使用这些伪标签在目标数据上重新训练网络。 实际上,这些伪标签有潜在的干扰,而且往往不正确。 因此,直接使用这些伪注释来训练模型可能会导致错误不断在网络中得到强化的情况。 我们使用了一种过滤策略来克服这个问题,它包括删除不确定的注释。 大多数现有的工作都围绕着开发复杂而精确的滤波技术来处理伪标签中存在的噪声。 注意,这种带有伪标签的训练策略很简单,但非常有效,因为它试图直接最小化目标域预测错误,而不像对抗性特征学习,其策略是最小化目标预测错误的上界。
获得的伪标签。 自训练通常包括使用这些伪标签在目标数据上重新训练网络。 实际上,这些伪标签有潜在的干扰,而且往往不正确。 因此,直接使用这些伪注释来训练模型可能会导致错误不断在网络中得到强化的情况。 我们使用了一种过滤策略来克服这个问题,它包括删除不确定的注释。 大多数现有的工作都围绕着开发复杂而精确的滤波技术来处理伪标签中存在的噪声。 注意,这种带有伪标签的训练策略很简单,但非常有效,因为它试图直接最小化目标域预测错误,而不像对抗性特征学习,其策略是最小化目标预测错误的上界。
Roychowdhry等人提出了一种基于自训练的方法,利用视频数据自动计算伪标签。 具体来说,它们利用相邻帧之间的时间一致性来跟踪由源训练模型检测,如图15所示。 这有助于挖掘更多检测模型可能遗漏的伪标签。 因此,目标数据集的伪标签现在包含了来自检测网络和跟踪器的预测。 该算法同时在标记源数据集和伪标记目标数据集上进行训练,使检测器适应目标数据。 无论以何种方式收集(从检测器模型还是通过跟踪),目标域伪标签都被分配为同一个类别标签,即正类![]() ,负类
,负类![]() 。 然而,正伪标签中有两种类型:从检测模型中提取的预测和使用跟踪器提取的伪标签。 它们都被分配了一个分数值来计算一个内插标签。 分数分配如下:
。 然而,正伪标签中有两种类型:从检测模型中提取的预测和使用跟踪器提取的伪标签。 它们都被分配了一个分数值来计算一个内插标签。 分数分配如下:
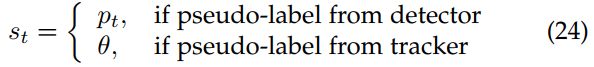
其中,![]() 为所有伪标签的评分,
为所有伪标签的评分,![]() 为检测器模型得到的概率,θ为对跟踪器伪标签的置信度,无论其置信度如何,都将评分提高到该恒定值,以强调其在训练中的重要性。 使用分配给每个伪标签的分数值,通过用分数值插值标签得到一个软标签。 内插标签的计算方法如下:
为检测器模型得到的概率,θ为对跟踪器伪标签的置信度,无论其置信度如何,都将评分提高到该恒定值,以强调其在训练中的重要性。 使用分配给每个伪标签的分数值,通过用分数值插值标签得到一个软标签。 内插标签的计算方法如下:
![]()
其中λ为插值参数,![]() 为第i个边界框式24给出的硬标记。 最后,在源域数据和目标域数据上同时使用ground-truth和pseudo-labels对检测器模型进行训练。 对于任意图像
为第i个边界框式24给出的硬标记。 最后,在源域数据和目标域数据上同时使用ground-truth和pseudo-labels对检测器模型进行训练。 对于任意图像![]() ,检测损失为:
,检测损失为:
![]()
其中,![]() 为Faster-RCNN检测损失,
为Faster-RCNN检测损失,![]() 为分别包含边框信息和类别标签的源图像对应的标注,
为分别包含边框信息和类别标签的源图像对应的标注,![]() 为分别包含边框信息和插值类别标签
为分别包含边框信息和插值类别标签![]() 的目标图像对应的伪标签。 随着训练的进行,基于跟踪器的伪标签的侧重点有助于提高对目标域数据的适应性。
的目标图像对应的伪标签。 随着训练的进行,基于跟踪器的伪标签的侧重点有助于提高对目标域数据的适应性。
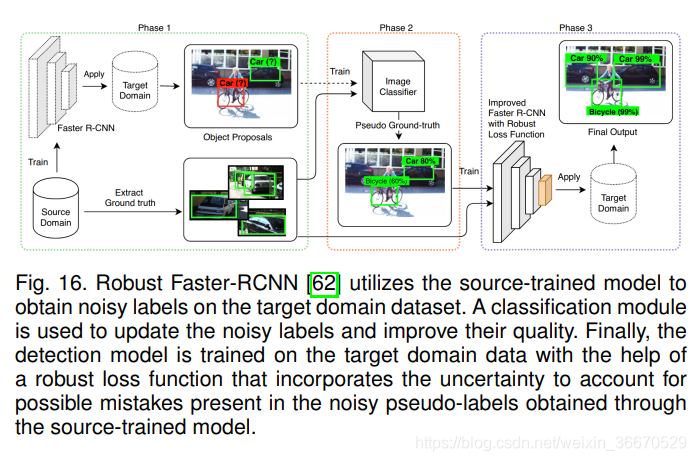
虽然利用视频数据的时间一致性挖掘伪标签是获得更多注释的有效策略,但它在很大程度上依赖于视频数据的可用性,而这并非总是可能的。 因此,开发基于单幅图像的伪标签训练策略是非常重要的。 Khodabandeh等人[62]提出了一种专门针对单图像目标数据集伪标签中存在的噪声的方法。 他们的方法被称为Robust Faster-RCNN,遵循一种三阶段训练策略。 所有相如图16中与每个相对应的方框图所示。 在第一阶段,使用具有ground-truth注释的源域数据集,使用监督检测损失![]() 对检测网络进行训练。 在第二阶段,利用源训练的检测器模型获取目标域数据集的伪标签。 随后,使用在大规模分类数据集上预先训练的额外分类器网络进一步细化伪标签。 细化策略既利用检测器模型预测,又利用分类器网络预测。 在改进标签的帮助下,第三阶段涉及用新设计的损失来训练检测器模型,该损失考虑了伪标签中潜在的噪声,并帮助检测器更好地学习。 让我们考虑,
对检测网络进行训练。 在第二阶段,利用源训练的检测器模型获取目标域数据集的伪标签。 随后,使用在大规模分类数据集上预先训练的额外分类器网络进一步细化伪标签。 细化策略既利用检测器模型预测,又利用分类器网络预测。 在改进标签的帮助下,第三阶段涉及用新设计的损失来训练检测器模型,该损失考虑了伪标签中潜在的噪声,并帮助检测器更好地学习。 让我们考虑,![]() 和
和![]() 分别是来自检测器模型和预先训练的图像分类网络的预测的概率向量。 此外,让
分别是来自检测器模型和预先训练的图像分类网络的预测的概率向量。 此外,让![]() 和
和![]() 分别表示检测器模型的预测和预先训练的图像分类网络的预测的logits(分数向量)。
分别表示检测器模型的预测和预先训练的图像分类网络的预测的logits(分数向量)。 ![]() 和
和![]() 分别表示第一阶段采集的包围框伪标签和检测器模型预测的现在的包围框。 鲁棒Faster-RCNN[62]训练利用这些预测来细化伪注释,然后用这些伪注释作为监督来训练目标数据上的检测模型。 以下方程描述了细化过程:
分别表示第一阶段采集的包围框伪标签和检测器模型预测的现在的包围框。 鲁棒Faster-RCNN[62]训练利用这些预测来细化伪注释,然后用这些伪注释作为监督来训练目标数据上的检测模型。 以下方程描述了细化过程:
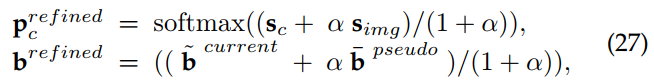
α是一个超参数,控制这两项之间的权衡。 α从一个较大的值开始,随着第三阶段训练的进行逐渐减小到较小的值。 导致改进方程Eq. 27的理论公式见。 用精炼的注释进行训练有助于检测器模型更好地对抗伪标签中的噪声。
以往进行自我训练的方法都是基于Faster-RCNN框架,并依赖于后续假设来处理获得的伪标签中的噪声。 Kim等人提出了一种专注于对单阶段目标检测器模型进行自的策略,特别是针对基于SSD的模型。 作者先对伪标签进行硬负挖掘,然后采用弱负挖掘策略,如图17所示。 在难挖掘阶段,利用阈值![]() 对假-负边界盒提案进行过滤,最终进行边界框预测。 弱挖掘阶段通过分配使用基于支持区域的可靠评分(SRRS)计算的实例级评分来降低假阳性的风险,从而进一步改进伪标签。 该分数由满足硬采矿阈值
对假-负边界盒提案进行过滤,最终进行边界框预测。 弱挖掘阶段通过分配使用基于支持区域的可靠评分(SRRS)计算的实例级评分来降低假阳性的风险,从而进一步改进伪标签。 该分数由满足硬采矿阈值![]() 的检测模型预测的一组roi来计算。 如果存在符合任意检测器边界框预测
的检测模型预测的一组roi来计算。 如果存在符合任意检测器边界框预测![]() 的
的![]() -IoU阈值的
-IoU阈值的![]() ,其置信值为
,其置信值为![]() ,则相应边界框预测对应的SRRS评分可计算为:
,则相应边界框预测对应的SRRS评分可计算为:
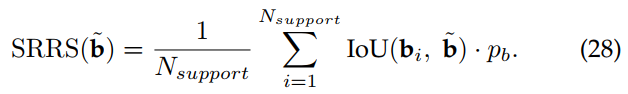
在SRRS评分的基础上,对伪标签进行另一个阈值![]() 进行过滤,以减少误报。 此外,他们还采用了一种额外的正则化,在论文中称为对抗性背景分数正则化(ABSR)。 这种正则化利用了第3.1.1节中讨论的梯度反转层; 但是,它仅适用于目标域图像。 如果不进行这种正则化,检测器模型就有可能出现高可信度的错误预测。 ABSR的加入通过避免对齐到不可转移的背景区域,限制了SSD分类器子网络产生这种过度自信的预测。 结合硬、弱挖掘阶段挖掘出的伪标签和正则化损失,采用端到端的方式对检测器模型进行训练。 自我训练是通过最小化第2.1.2节中讨论的
进行过滤,以减少误报。 此外,他们还采用了一种额外的正则化,在论文中称为对抗性背景分数正则化(ABSR)。 这种正则化利用了第3.1.1节中讨论的梯度反转层; 但是,它仅适用于目标域图像。 如果不进行这种正则化,检测器模型就有可能出现高可信度的错误预测。 ABSR的加入通过避免对齐到不可转移的背景区域,限制了SSD分类器子网络产生这种过度自信的预测。 结合硬、弱挖掘阶段挖掘出的伪标签和正则化损失,采用端到端的方式对检测器模型进行训练。 自我训练是通过最小化第2.1.2节中讨论的![]() 来执行的,其中损失是使用挖掘出的伪标签计算的。
来执行的,其中损失是使用挖掘出的伪标签计算的。
3.3、图像到图像的翻译
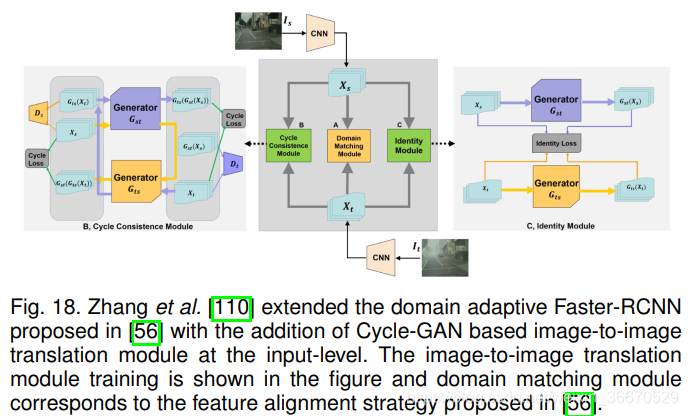
正如在介绍中所讨论的,无监督视觉域适应的主要问题是目标域图像在视觉上与源域非常不同。 这导致源训练的检测器网络在特征空间上存在较大差距,导致在目标域上性能较差。 属于对抗性特征学习(在第3.1节讨论)和基于伪标签的自我训练(在第3.2节讨论)的方法试图学习一种更适合于对目标域图像进行检测的特征表示。 与特征对齐方法相比,基于图像到图像平移的方法在输入水平上减少了域间隙。 基于图像到图像平移的适应策略中最流行的策略之一是使用非配对图像到图像平移算法,如Cycle-GAN,不配对图像到图像翻译,多模态单元。 利用基于图像到图像平移方法的方法通常利用额外的策略,如自我训练或对抗特征学习,以进一步提高目标检测性能。 图像到图像的转换有助于弥合输入级的差距,而特征级的对抗对齐确保了目标和源域的共享特征空间。 Zhang等人[110]专门利用Cycle-GAN学习源域和目标域图像之间的映射函数,其方法称为Cycle-consistent Adaptive Faster-RCNN (CA-FRCNN),如图18所示。 他们的方法扩展了[56]中提出的DA-Faster方法(在3.1.2节中讨论),通过在输入级别添加图像到图像的转换,同时在实例和完整的图像级别添加其他损失,如梯度反转。 如他们的实验[110]所示,添加图像转换模块进一步提高了性能。


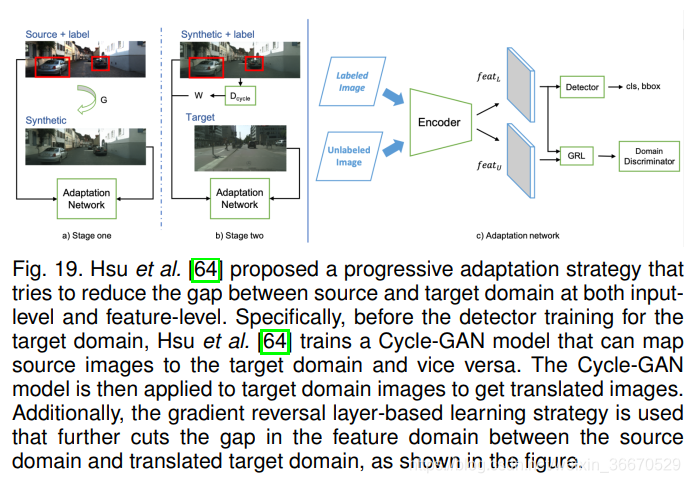
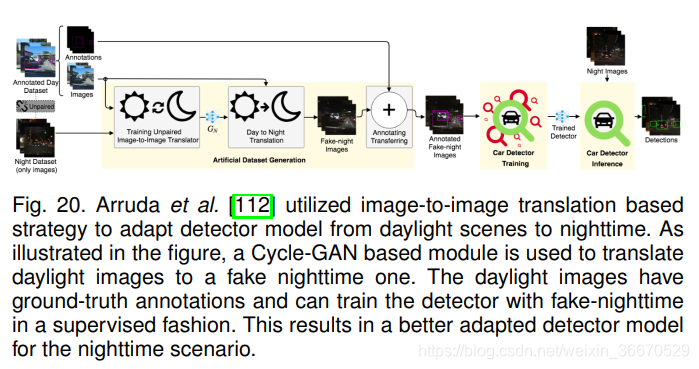
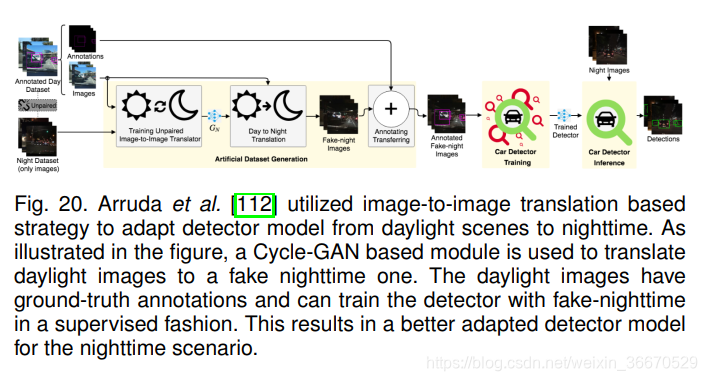
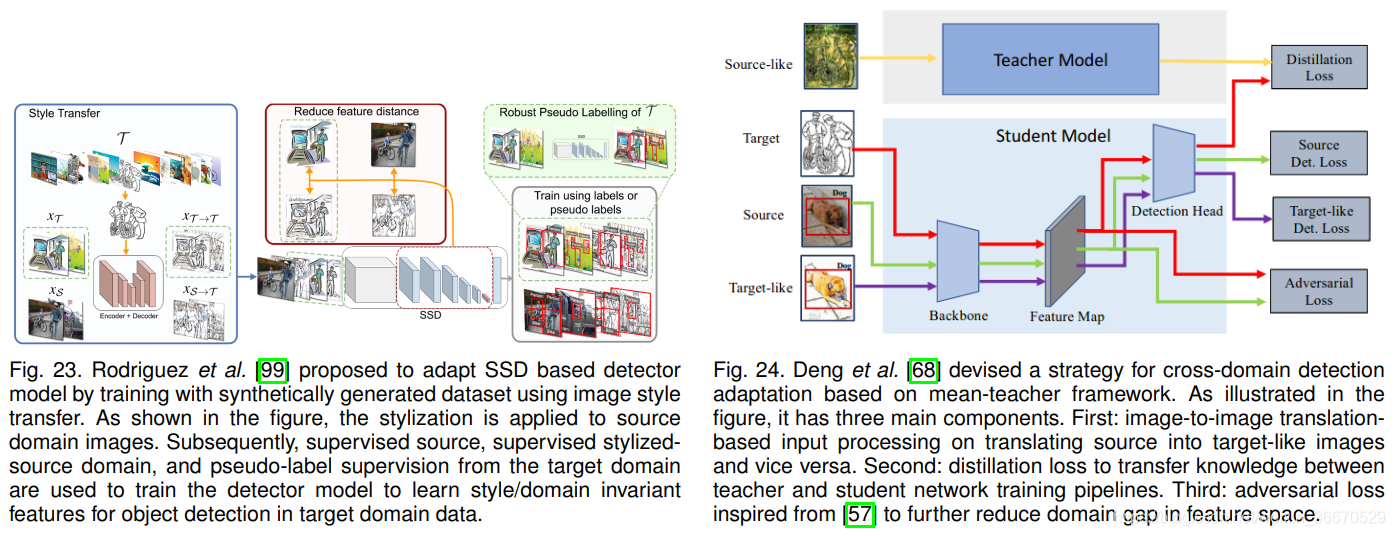
Hsu等人提出了一种渐进适应策略,他们采用了类似的图像级翻译策略。 如图19所示,利用基于Cycle-GAN的image -image平移模块将目标图像转换为类源图像。 然后借助梯度反转层,进一步减小特征空间中的残差域间隙。 此外,通过渐进式适应[64],他们表明仅在图像水平上应用梯度反转就足以适应,而不是同时应用图像水平和实例水平的损失。 Arruda等利用图像转换模块专门解决了白天(源域)和夜晚(目标域)数据之间的域间隙,如图20所示。 一旦图像转换模块就绪,它将用于转换所有白天的数据,以创建一个虚假的夜间数据集。 由于ground-truth注解可以用于白昼图像,它们可以用来监督以虚假夜间图像作为输入的探测器模型。 这样的训练将有助于学习一个更适合夜间场景的检测器模型,而不是由完全监督的日光图像训练的模型。
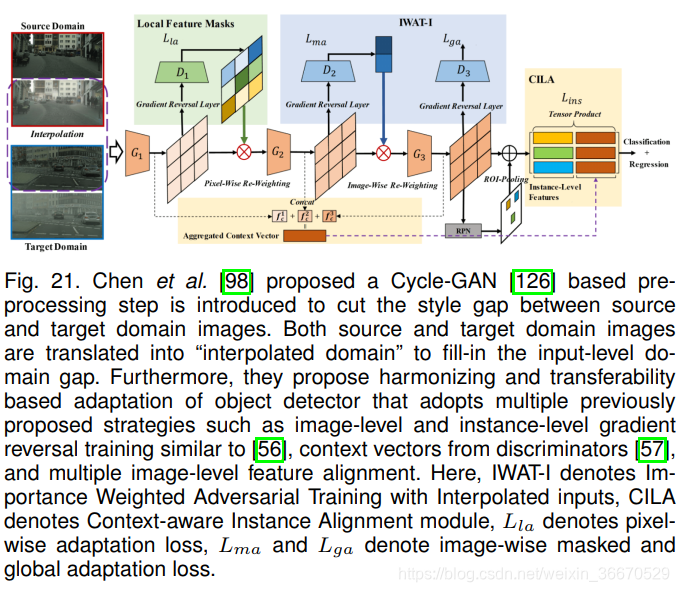
Chen等人将先前提出的几种策略与图像到图像的转换思想结合在一起,称之为协调可转移性校准网络(Harmonizing Transferability Calibration Network, HTCN)。 所提出的方法如图21所示。 首先,基于Cycle-GAN的模型学习源域和目标域之间的映射。 HCTN利用这个图像转换模块来创建类源目标图像和类源图像,也称为“插值图像”。 “插值图像”有助于HTCN填补域间的分布间隙,从而减少决策边界的源偏差。 此外,HTCN采用了与[57]中用于强局部对齐类似的局部对齐损失(见3.1节讨论)。 与其他基于图像到图像转换思想的方法直接利用网络的特征图输出不同,HCTN使用局部判别网络的输出来权衡转发到后续层的“插值图像”的特征图。 这种策略被称为插值图像加权重要对抗训练(IWAT-I),通过适当地加权特征图来避免负迁移,促进正迁移。 IWAT-I背后的关键动机是,并不是所有的“插值图像”都具有相同的可转移性,因此需要根据个别图像适当的权重来突出可转移区域,同时抑制feature map中的噪声。 该策略与第3.1.3节中讨论的加权对抗训练密切相关。 此外,HCTN还使用两个附加的鉴别器在检测骨干网络输出处对掩蔽特征和全局特征进行基于梯度反向的对齐。 这两种情况下所使用的对抗性损失遵循[57]中用于全局对齐的公式; 然而,与[57]相比,HCTN使用了二元交叉熵损失。 最后,他们利用[56]中提出的实例级自适应公式,将前三个鉴别器学习到的特征与检测网络的roi池特征连接起来,执行上下文感知实例级特征对齐。 这种策略被称为上下文感知的实例级对齐(CILA)。 通过综合这些损失,HCTN捕获源域、目标域和“插值图像”域的可转移区域,充分利用有用的信息,以适应由Cycle-GAN翻译的图像。 Shen等人[103]利用基于MUNIT[129]的图像到图像翻译来扩展[58]中提出的方法(在第3.1.2节中讨论)。 具体来说,基于MUNIT的翻译模块通过学习在源域和目标域之间映射整个图像(图像级翻译)和目标区域(实例级翻译)来学习。 此外,Shen等[103]还学习了一个风格代码库,以获得包含丰富空间信息的对象、背景和全局风格向量来辅助翻译网络。 除基于MUNIT的图像平移模块外,鉴别器网络应用于多层进行基于梯度反向的对抗训练。 此外,还训练了另一组没有梯度反转层的域分类网络。 将这些领域分类器学习到的特征与roi池特征连接起来,以改进分类。 Shen等[103]也指出,将这些域分类网络从主检测管道中分离出来,限制梯度流,进一步提高了检测性能。
3.4、域随机化
在基于图像到图像转换的方法中,主要的焦点是学习源域和目标域之间的映射,并在输入级上减小域间隙。如果有一个完美的映射函数可以将目标域图像转换为源域图像或源域图像转换为目标域图像,则检测器模型可以完全适应目标域而不需要任何注释。但是在实际应用中,这种映射函数并不一定准确,因此即使在图像平移后,原始图像与平移后的图像之间也可能存在一个域间隙,例如源图像与平移后的目标图像之间或者源图像与平移后的目标图像之间。因此,大多数基于图像到图像平移的方法利用了额外的基于梯度反转的特征对齐或基于伪标签的自我训练。为了克服不能学习源域和目标域之间的精确映射函数的缺点,域随机化对输入图像应用若干转换来派生多个新的域。检测模型的目标是在训练过程中考虑这些新领域,并学习对包括源和目标在内的所有领域不变的特征表示。该策略对检测模型的特征表示施加了很强的约束,因为网络必须在图像中找到在各种各样的图像变换中保持不变的特征。然而,为了实现这一点,需要额外的策略,如对抗特征学习或自训练。
综上所述,基于图像到图像转换的方法旨在学习减少输入级域间隙以提高模型性能的中间阶段,而,域随机化综合生成包含多种不同风格(包括源域和目标域风格)的域,以确保检测模型学习对检测有用的特征,而不管输入图像的风格如何。让我们考虑一个源域数据集![]() 和目标域数据集
和目标域数据集![]() 。域随机化从给定的源域数据集创建多个新的数据集,这些数据集包含多个不同的样式。让我们将这些源派生的程式化数据集表示为:
。域随机化从给定的源域数据集创建多个新的数据集,这些数据集包含多个不同的样式。让我们将这些源派生的程式化数据集表示为:![]() ,其中
,其中![]() 表示
表示![]() 种风格,M表示独特风格的总数。风格化过程确保图像的内容不会改变,因此通过风格化过程保存目标类别和位置信息。所有的程式化数据集都来自源域,因此,第i个程式化图像
种风格,M表示独特风格的总数。风格化过程确保图像的内容不会改变,因此通过风格化过程保存目标类别和位置信息。所有的程式化数据集都来自源域,因此,第i个程式化图像![]() 可以共享原始源数据集
可以共享原始源数据集![]() 对应图像的ground-truth注释,对于任意
对应图像的ground-truth注释,对于任意![]() 和
和![]() 。
。
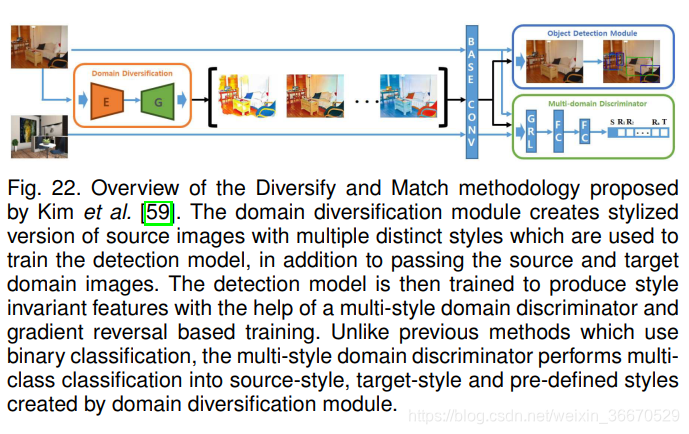
Kim等人利用域随机化来适应一种基于Faster-RCNN的检测模型。如图22所示,该方法由三部分组成:域多样化模块、检测模型和多域鉴别器。域多样化模块基于生成对抗网络,其任务是获取源域图像并移动域以派生一组视觉上不同的域。此外,它们对域多样化网络的输出施加了一定的约束,如重构、颜色保持和周期一致性。这确保了综合生成的域不会破坏可能对模型性能产生负面影响的映像内容。随后,检测模型将从这些合成域的不同集合中采样的图像连同源域和目标域图像一起输入。在源域和合成域上应用![]() (Supervised detection loss)对检测器模型进行训练。为保证检测模型的基网络学习域不变特征表示,在基网络的末端采用了带有梯度反转层的多域鉴别器网络。通常,域鉴别器的任务是执行二值分类,以识别任何图像来自源或目标。然而,本研究中使用的多域鉴别器的任务是进行多类分类,以确定特征表示是属于源域、目标域还是综合生成的某个域。因此,与[56]中使用的二进制交叉熵损失不同,鉴别器网络使用的是多类交叉熵损失。这里,任何第i个输入图像的域标签被给定为
(Supervised detection loss)对检测器模型进行训练。为保证检测模型的基网络学习域不变特征表示,在基网络的末端采用了带有梯度反转层的多域鉴别器网络。通常,域鉴别器的任务是执行二值分类,以识别任何图像来自源或目标。然而,本研究中使用的多域鉴别器的任务是进行多类分类,以确定特征表示是属于源域、目标域还是综合生成的某个域。因此,与[56]中使用的二进制交叉熵损失不同,鉴别器网络使用的是多类交叉熵损失。这里,任何第i个输入图像的域标签被给定为![]() ,其中,0和M + 1分别表示源域和目标域,其余标签分别表示域多样化模块生成的各个合成域。
,其中,0和M + 1分别表示源域和目标域,其余标签分别表示域多样化模块生成的各个合成域。
Rodriguez等人提出了一种域随机化方法来适应基于SSD的单阶段目标检测器。图23所示的关键思想是利用[130]提出的风格传递网络创建具有多个不同预定义风格的源派生数据集。使用从源域数据集借用的注释创建源派生数据集的多个程式化版本。此外,在目标域图像上评估源训练的检测器模型,提取伪标签,然后用于自训练。为了提取鲁棒伪标签进行有效的自训练,采用正、负阈值提取高质量的正、负样本。检测器模型的基网络称为![]() ,通过特征一致性损失来学习域不变特征,使从源数据提取的特征表示与程式化源数据之间的l2 -范数最小。这种损失称为特征一致性损失,定义为:
,通过特征一致性损失来学习域不变特征,使从源数据提取的特征表示与程式化源数据之间的l2 -范数最小。这种损失称为特征一致性损失,定义为:

表示源域为![]() , source-derived mth-style dataset as
, source-derived mth-style dataset as ![]()
![]() ,目标域数据集为
,目标域数据集为![]() 。这里,
。这里,是用于创建不同的源派生数据集的预定义样式数,
![]() 和
和![]() 分别表示对任意
分别表示对任意![]() 和目标图像的ground-truth source annotations和伪标签。目标检测器的最终训练损失可描述为:
和目标图像的ground-truth source annotations和伪标签。目标检测器的最终训练损失可描述为:
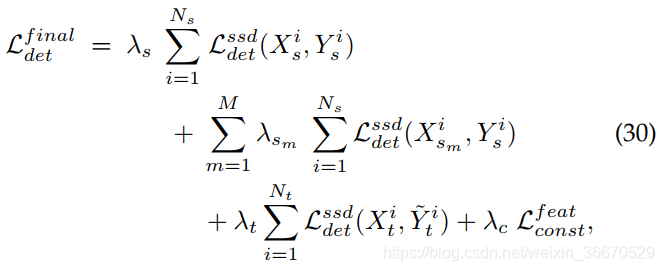
其中,![]() 、
、![]() 、
、![]() 分别为源监督损失、程控源监督损失、目标域伪标记训练损失和特征一致性损耗的权衡参数。
分别为源监督损失、程控源监督损失、目标域伪标记训练损失和特征一致性损耗的权衡参数。
3.5、Mean teacher training
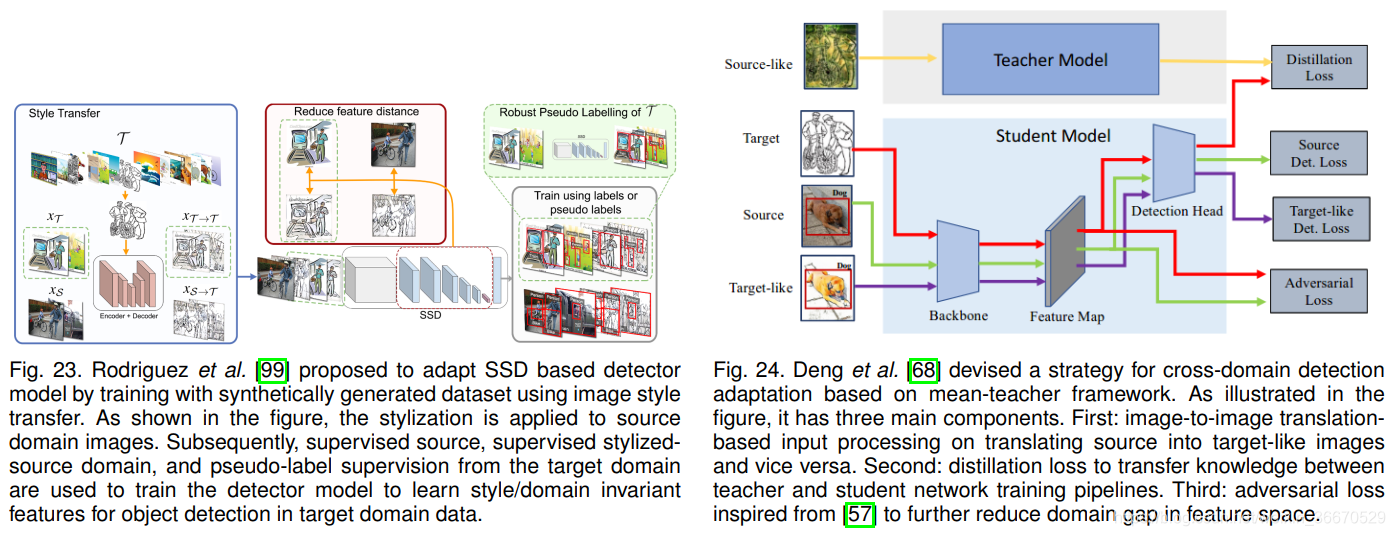
在迁移学习、半监督学习、和领域自适应和中,知识蒸馏已被证明是有效的利用未标记数据。大多数利用师生训练策略的领域适应工作只考虑了图像分类的任务。他们的成功启发了许多采用师生训练框架对目标检测器模型进行无监督域适应的作品。基于该策略的最近一项值得注意的工作是由Deng等人提出的无偏均值-教师策略[68],该策略专门利用均值-教师框架[133]训练来将目标检测器适应于目标领域。从图24中可以看出,Deng等人[68]将图像到图像翻译(见第3.3节)和对抗特征学习(见第3.1节)等多种策略与mean-teacher框架相结合。首先,该方法训练Cycle-GAN模块学习源域图像和目标域图像之间的图像映射,然后使用该模块创建类源目标和类目标源图像。学生模型流程使用原始源域、目标域和类目标源图像进行训练。由于源图像和类目标源图像都得到了充分的标记,因此可以使用监督检测损失作为源进行训练,如图24所示
![]()
其中![]() 和
和![]() 分别为教师模型和学生模型的网络参数,α表示可用于控制教师更新的平滑系数超参数,上标i和i−1分别表示当前和以前的训练迭代的索引。为了进一步减小学生模型特征空间的域间隙,采用基于梯度反向的对抗性训练,包括强局部特征对齐和弱全局特征对齐。结合精馏、参数更新、监督检测损失和对抗性特征训练;整个训练以端到端方式执行。
分别为教师模型和学生模型的网络参数,α表示可用于控制教师更新的平滑系数超参数,上标i和i−1分别表示当前和以前的训练迭代的索引。为了进一步减小学生模型特征空间的域间隙,采用基于梯度反向的对抗性训练,包括强局部特征对齐和弱全局特征对齐。结合精馏、参数更新、监督检测损失和对抗性特征训练;整个训练以端到端方式执行。
其他利用学生-教师框架的工作包括Liu等人,他们扩展了均值教师框架,通过利用大量未标记数据来提高整体表现,以半监督的方式训练目标检测器。虽然Liu等人侧重于半监督检测,从相似的分布中提取有标记和无标记数据,它可以很容易地被用来进行无监督领域的目标检测器自适应训练。Cai等人提出了跨域检测,利用一个通过图结构依赖学习目标关系的mean-teacher框架。
3.6、图推理
图推理是计算机视觉领域中一种广泛流行的技术,用于视觉识别、视频理解等。它也被广泛用于分类网络的无监督自适应。在适应目标检测器的情况下,图形对潜在目标类别的图像间和图像内关系建模的能力是非常有用的。此外,建模图结构是互斥的,因此可以与其他现有的适应策略相结合。基于这些好处,Cai等人提出了一种领域自适应对象检测方法,称为Mean-Teacher对象关系(MTOR),该方法利用基于图推理的策略,并结合了学生-教师培训。如图25所示,MTOR由四个主要部分组成:1)region - lelev Consistency (RLC), 2) Inter-Graph Consistency (InterGC), 3) Intra-Graph Consistency (IntraGC), 4) Mean-Teacher Training (MTT)。在这里,前三个组件专门用于图形结构,它对图像中对象之间的关系进行建模。给定一个源域数据集,![]() ,目标域数据集,
,目标域数据集,![]() ,检测模型,
,检测模型,,基础网络,
![]() ,教师网络,
,教师网络,和学生网络,F,一个图,
![]() 构造。其中VXt是表示检测网络区域提议预测集合的顶点,
构造。其中VXt是表示检测网络区域提议预测集合的顶点,![]() 是对应图的亲和矩阵。注意,
是对应图的亲和矩阵。注意,![]() 和
和![]() 分别对应于使用教师模型和学生模型在目标域图像上构建的图。图中的每个顶点对应于一个区域提议,并被分配一个概率向量,表示该区域属于其中一个
分别对应于使用教师模型和学生模型在目标域图像上构建的图。图中的每个顶点对应于一个区域提议,并被分配一个概率向量,表示该区域属于其中一个![]() 类别的概率。在选择区域建议之前,通过消除最大概率值低于阈值的所有建议来过滤它们。对于任意目标图像Xt,考虑存在
类别的概率。在选择区域建议之前,通过消除最大概率值低于阈值的所有建议来过滤它们。对于任意目标图像Xt,考虑存在![]() 个区域建议,对于第i个区域建议,对应的概率向量为
个区域建议,对于第i个区域建议,对应的概率向量为![]() ,则区域级一致性损失定义为:
,则区域级一致性损失定义为:
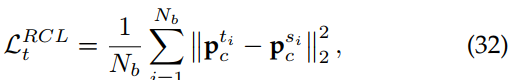
其中![]() 和
和![]() 分别表示从教师和学生模型中提取的概率向量,分别对应于教师图
分别表示从教师和学生模型中提取的概率向量,分别对应于教师图![]() 和学生图
和学生图![]() 。
。
为了计算图间的一致性,利用余弦相似度计算学生图和教师图的亲和矩阵InterGC。 对任意具有区域建议的目标图像
![]() ,如果我们将教师图表示为
,如果我们将教师图表示为![]() ,其中任意第
,其中任意第个区域建议由从教师模型中提取的相应ROI合并特征拟合组成。亲和力矩阵是利用给定图像中任意两个提案特征之间的特征相似度计算的,定义为:
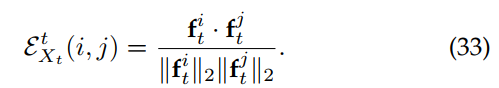
同样,Eq. 33可用于计算学生模型![]() 的亲和矩阵。如果既有学生模型和教师模型的亲和矩阵,则计算图间一致性损失如下:
的亲和矩阵。如果既有学生模型和教师模型的亲和矩阵,则计算图间一致性损失如下:
![]()
这种图间一致性强制对目标图像的学生和教师流程之间的图结构进行对齐。然而,在每个图像中,可能有多个语义相关的类别。在教师模式的监督下,图内一致性加强了同一类别的学生图建议之间的相似性。具体来说,教师模型用于预测两个区域提案中是否包含同一类别的目标。如果第个和第
个建议包含相同的目标类别,则标签
图被赋值为1或0,否则赋值为0。给定任意目标图像的student模型的亲和矩阵
![]() ,图内一致性损失定义为:
,图内一致性损失定义为:
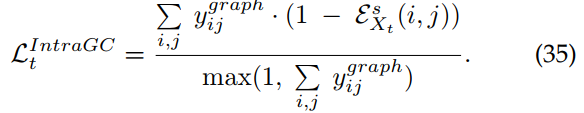
除了这些基于图的一致性损失外,学生网络还使用监督检测损失进行训练。教师网络参数的更新遵循第3.5节中讨论的均值教师公式。
最近,Xu等人提出了一种基于图的自适应方法,他们在目标提议之间构建一个关系图,以计算有助于源域和目标域对齐的类别原型。训练策略包括图的构建和对齐,如图26所示。该方法基于Faster-RCNN检测框架,利用其两阶段检测器训练计算关系图。关系图用于计算类别原型,然后匹配这些原型,以在检测器模型的每个阶段强制源域和目标域之间对齐。总体对齐策略在文献[97]中称为图诱导原型对齐(Graph-induced Prototype alignment, GPA)。让我们考虑,对于任意一幅图像,检测模型产生数目的区域建议,以不同的概率在数据集中包含任何给定类别的目标。根据这些建议,得到图
![]() 用V作为节点,E表示赋给图的邻接矩阵/边值。每个节点代表一个由检测模型预测的区域建议,并通过计算区域建议对之间的交集过并(IoU)来计算邻接矩阵值。具体来说,让我们考虑用边界框bi和bj表示任意输入图像的两个区域建议。它们之间的边值按下式计算:
用V作为节点,E表示赋给图的邻接矩阵/边值。每个节点代表一个由检测模型预测的区域建议,并通过计算区域建议对之间的交集过并(IoU)来计算邻接矩阵值。具体来说,让我们考虑用边界框bi和bj表示任意输入图像的两个区域建议。它们之间的边值按下式计算:
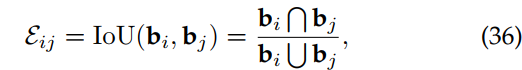
其中![]() 为交集运算,
为交集运算,![]() 为并集运算。这就创建了一个大小为
为并集运算。这就创建了一个大小为![]() 的邻接矩阵。一旦关系图被构造,邻接矩阵被用来聚集ROI集合特征和他们各自的类别概率为每个区域建议。我们将每个具有d维的ROI集合特征表示为
的邻接矩阵。一旦关系图被构造,邻接矩阵被用来聚集ROI集合特征和他们各自的类别概率为每个区域建议。我们将每个具有d维的ROI集合特征表示为![]() ,并将各自的概率向量表示为
,并将各自的概率向量表示为![]() 。我们可以将这些特征和概率值进行叠加,得到特征矩阵
。我们可以将这些特征和概率值进行叠加,得到特征矩阵![]() 和概率矩阵
和概率矩阵![]() 。聚集特征
。聚集特征![]() 和概率
和概率![]() 可以表示为:
可以表示为:
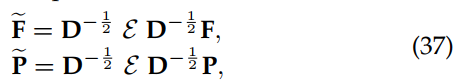
其中矩阵D是一个对角矩阵,对角元素为![]() 。这种聚合策略更新特征向量和概率向量,以准确地表示实例级信息。此外,更新的特征和概率用于计算类别原型。第k类的原型特征可以计算为:
。这种聚合策略更新特征向量和概率向量,以准确地表示实例级信息。此外,更新的特征和概率用于计算类别原型。第k类的原型特征可以计算为:
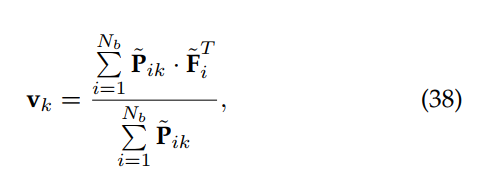
式中,![]() 为第k类对应的原型。这些原型分别针对源域和目标域图像进行计算。通过最小化同一类别原型之间的距离,最大化不同类别原型之间的距离,实现源原型与目标原型的匹配。此外,通过最小化各自的类别原型,在源域和目标域之间匹配相同的类别原型。
为第k类对应的原型。这些原型分别针对源域和目标域图像进行计算。通过最小化同一类别原型之间的距离,最大化不同类别原型之间的距离,实现源原型与目标原型的匹配。此外,通过最小化各自的类别原型,在源域和目标域之间匹配相同的类别原型。
4、评估协议
在本节中,我们将讨论用于评估前面讨论的各种域自适应检测方法的性能的评估协议的细节。 首先,我们提供用于评估目的的各种基准数据集的细节,然后讨论各种适应设置,如合成到真实、干净到不利的天气等。 接下来,我们定义用于评估和比较的指标。 最后,我们对各种方法的结果进行了详细的讨论。
4.1、数据集
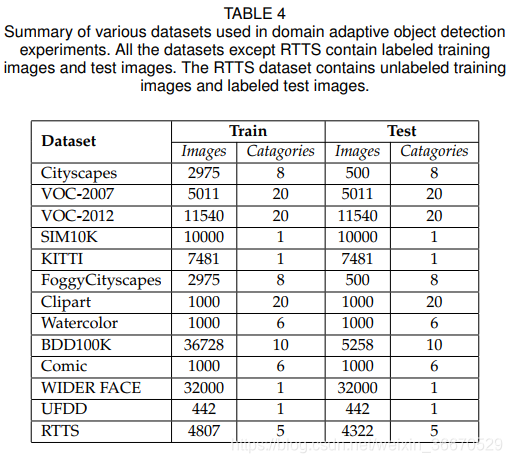
各种数据集已经被用于评估领域自适应目标检测方法。 大多数这些数据集已经被广泛用于评估目标检测方法,因此,通过简单地定义不同的数据集作为源和目标域,自然可以用于评估域适配方法的目的。 这些数据集可以分为以下几类:(1)、通用目标,(2)、自动驾驶,(3)、人脸检测,(4)、天气退化,(5)、合成数据集。 图27显示了不同类别的数据集的概述。 在接下来的内容中,我们将详细讨论各种数据集。
Cityscapes.
复杂城市街道的场景理解是一个具有广泛应用前景的重要问题。 为了解决这个问题,戴姆勒公司和德累斯顿工业大学的一组研究人员于2016年发布了城市景观数据集。 城市景观分为8类:汽车、卡车、摩托车/自行车、火车、公共汽车、骑手和人。 数据集收集于50个城市,覆盖了春、夏、秋等不同季节。 Cityscapes数据集包含2975张用于训练的图像和500张用于测试的图像。
Foggy Cityscapes.
分析恶劣天气下的城市街道场景是一个具有挑战性的问题。 为了考虑这样的场景,Foggy Cityscapes是由引入的,通过在Cityscapes数据集上应用雾过滤器。 Foggy Cityscapes拥有相同的8类Cityscapes数据集。 Foggy Cityscapes数据集包含2975张用于训练的图像和500张用于测试的图像。
Sim10K.
考虑到现实世界数据的收集是耗时且乏味的,计算机图形学的进步已经被用来生成照片般的真实数据,这些数据可以很容易地渲染和注释。 这种替代真实世界数据收集的方法既便宜又高效。 2017年,由游戏引擎《侠盗猎车手》渲染的合成数据集Sim10K发布了。 它有10K张图片,只有一个汽车类别有58701个汽车实例。 数据集提供了Pascal VOC格式的注释,便于使用。
KITTI.
KITTI[147]是自动驾驶和移动机器人领域最流行的数据集之一。 该数据集包含数小时的交通场景视频,由RGB、灰度和深度传感器等各种高质量传感器记录。 KITTI目标检测数据集由7481幅训练图像和7518幅测试图像组成,由80256幅标记目标组成,这些目标跨越8个类别:Car, Van, Truck, Pedestrian, Person sitting, Cyclist, Tram, Misc。
Pascal VOC2007/2012.
PASCAL VOC是一个包含通用目标的真实数据集。 它被用于各种任务,如大规模分类、目标检测和分割。 从2005年到2012年,PASCAL VOC图像集已经更新了多次。 在这些多个版本中,最受欢迎的是2007年和2012年的图像集,其中训练和验证分割总共包含15k张图像。 数据集中的图像包含20多个一般目标类别:飞机、自行车、鸟、船、瓶子、公共汽车、汽车、猫、椅子、牛、桌子、狗、马、自行车、人、植物、羊、沙发、火车、电视。
Clipart, Watercolor, Comic.
Clipart、Watercolor和Comic数据集分别包含抽象图像、艺术图像和滑稽图像。 理解这些抽象类型图像将允许直接研究模型如何推断高级语义信息。 因此,这些数据集被广泛用于不同域适配问题。 该剪纸艺术包含总共1K图像与Pascal VOC相同的20个类别。 水彩画和漫画集包含6类:自行车,鸟,汽车,猫,狗,人。 两个数据集分别包含1K张训练图像和1K张测试图像。
BDD100K.
BDD100K数据集是一个自动驾驶数据集,在场景、地理区域等方面具有很大的多样性。 它是最大的(到目前为止)驾驶视频数据集,包含来自纽约,伯克利,旧金山和海湾地区的100K视频。 该数据集包含70k张训练图像和10k张验证图像。 作者确保这些图像包含不同类型的天气、6个不同的场景、一天中的3个单独的时间,以及10个目标类别和边框注释。 对于域适配检测任务,使用BDD100k数据集的一个子集,其中包含标记为白天的图像。 这个子集包含36728张训练图像和5258张验证图像。
WIDER FACE.
人脸检测是现代计算机视觉中的一个重要应用。 然而,由于人脸检测数据集的方差不足,2015年,Shuo发布了由32000张图像和199K张标记人脸组成的最大的基准数据集WIDER face。 作者确保在规模,表情,照明,姿势,化妆和遮挡的高度可变性。
UFDD.
不利条件下的人脸检测是一个重要的问题,特别是对于视频监控任务。 为此,发布了由各种天气条件下采集的图像组成的UFDD数据集。 作者试图专门捕捉以下情况:雨,雪,雾,镜头障碍,模糊,照明。 该数据集总共包含6424张图像。
RTTS.
real Single Image DEhazing是一个由真实世界和合成模糊图像组成的大规模基准数据集。 RTTS是一个目标检测数据集,是驻留数据集的子集。 它包含了4807张未标注和4322张标注的真实世界模糊图像,覆盖了大部分交通和驾驶场景。 RTTS共有5个类别,即摩托车/自行车、人、自行车、公共汽车和汽车。

4.2、适配场景
在本节中,我们将描述现有方法所遵循的各种适应场景和协议。
4.2.1、Adverse weather conditions
在不同天气条件下,稳定的目标检测性能对于自动驾驶汽车等安全关键应用至关重要。 天气条件引入的图像伪影会对检测性能产生负面影响。 可以将雾城市景观和城市景观作为目标域和源域,评价区域适应方法在恶劣天气中的有效性。 此外,在真实世界的模糊条件下,可以将Cityscapes的域适应设置扩展到RTTS数据集,其中Cityscapes为源域,RTTS为目标域。 同样,对于人脸检测,当人脸检测器使用干净的天气数据进行训练时,这样的天气条件证明是具有挑战性的。 该适配场景可采用源域为WIDER-Face,目标域为UFDD-Haze进行探索。
4.2.2、Synthetic data adaptation
合成数据为真实数据收集提供了一种廉价的替代方案,因为它更容易收集,并且通过适当的工程,可以以极低的人工成本为合成数据提供注释。 尽管计算机图形学有了很大的进步,但使用最先进的渲染引擎生成的逼真合成数据会受到微妙的图像伪影的影响,这可能导致在真实数据上的性能欠佳。 文献中使用了《Sim10K》对《Cityscapes》的改编来分析这一背景。
4.2.3、Cross-camera adaptation
不同的内在和外在的相机属性,如分辨率,失真,方向,位置,导致图像捕获的对象在质量,规模和视角方面彼此不同。 虽然收集的数据可能是真实的,但这些域差异可能会导致严重的性能下降。 为了评价跨摄像机适应设置下的领域适应方法,大多数文献考虑了KITTI对城市景观和KITTI对城市景观。
4.2.4、Adaptation between dissimilar domains
在现实世界图像向艺术图像的转换过程中,现实世界图像的内在特征、质感在艺术图像中完全不同。 因此,很多方法考虑了不同领域的适应性,有三个适应性设置:PASCAL-VOC对Clipart, PASCAL-VOC对Watercolor和PASCAL-VOC对Comic。 所有这些领域的变化都是从真实世界的图像到合成的艺术图像。
4.2.5、Adaptation to Large-scale Dataset
越来越多的廉价和高质量的相机使得收集大规模数据变得更加容易。 然而,为检测任务注释它们是需要大量劳动的。 因此,探索从较小的数据集到较大的数据集的可能性具有重要的现实意义。 为了评估这一适应环境,大多数领域适应文献的方法将城市景观考虑到BDD100k。 在BDD100K数据集中,只有daylight子集被认为是目标域,而Cityscapes数据集被认为是源域。
4.3、Evaluation Metric
通常,目标检测器使用的是在VOC2007中引入的平均精度(AP)。通过精确的回忆曲线计算该区域,计算了每个类别的平均精度。精确和召回的定义如下:

精度是对一个目标检测器的预测有多精确的衡量。 回忆识别物体检测器的正面预测有多少是正确的。 为了确定检测器的预测是否与ground truth匹配,我们使用IOU测度的交集(详见图28)。 这项措施的定义如下:

IOU量然后被用来计算一个特定的预测是真阳性还是假阳性,使用下面的方程:
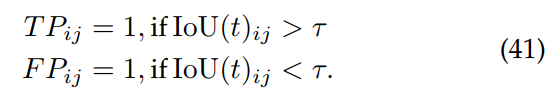
这里,是第
个图像的索引,
是第
个目标的索引,τ是阈值。 因此,通过对IOU条应用一个阈值,可以通过将所有目标建议分类为真阳性或假阳性来测量精度和召回率。 此外,为了比较所有类别之间的整体性能,使用了平均精度(mAP)度量,它涉及计算类别内的平均AP:
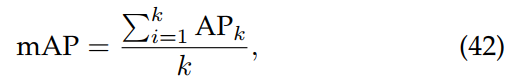
其中k为类别的总数。
4.4、讨论结果
在本节中,我们将对各种域适配目标检测方法的性能进行详细的比较和讨论。 为了进行比较,我们只考虑文献中两个或两个以上工作使用的改编场景。 大多数方法都进行域适配实验,这些实验由从上一节讨论的数据集中仔细选择源域和目标域创建的各种场景组成。 为了指示一个适应场景,我们遵循![]() 格式,其中dataset1用作标记的源域,而Dataset2用作未标记的目标域。
格式,其中dataset1用作标记的源域,而Dataset2用作未标记的目标域。
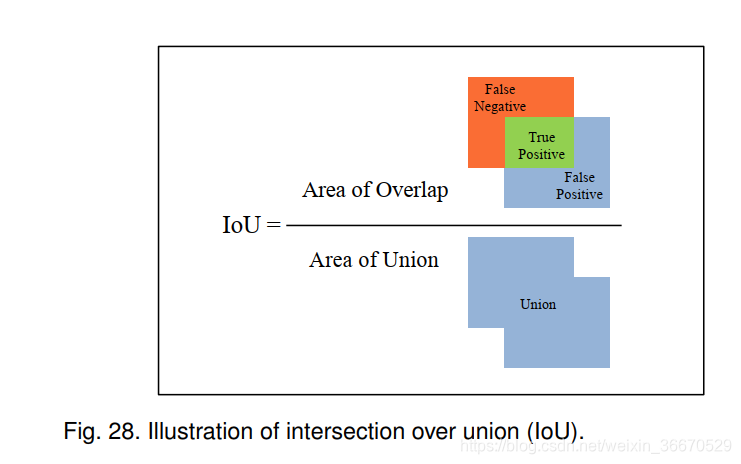
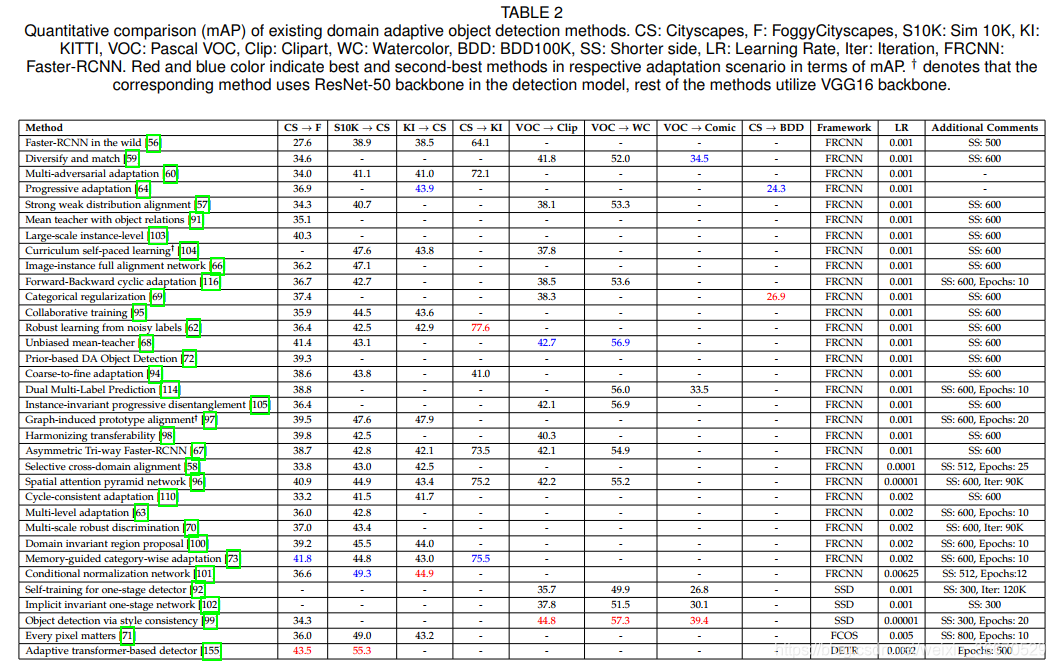
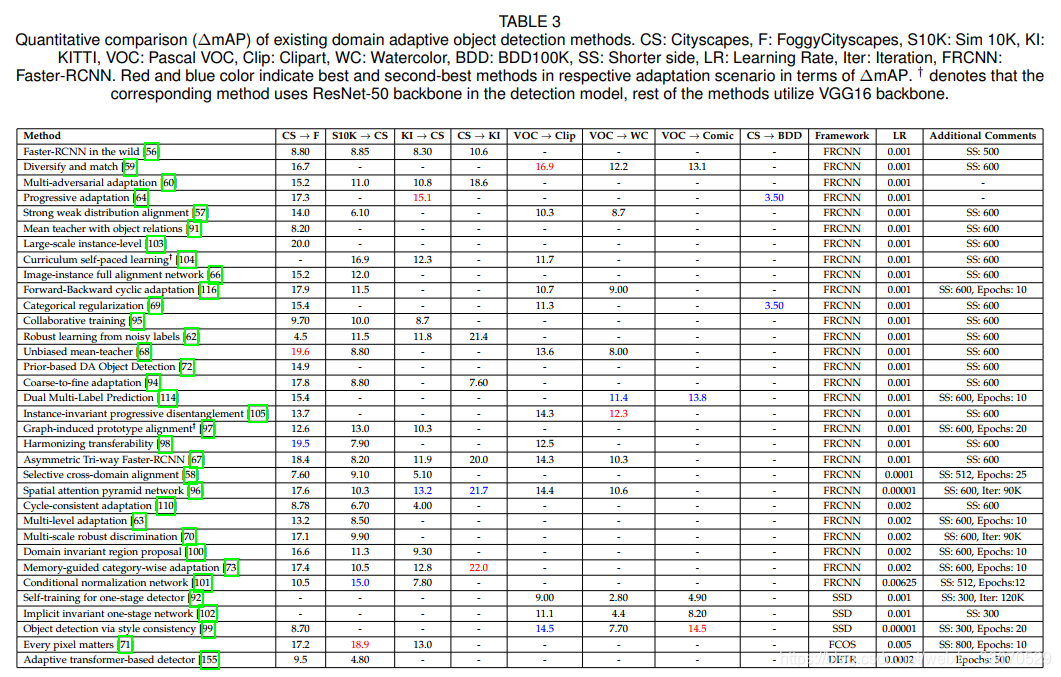
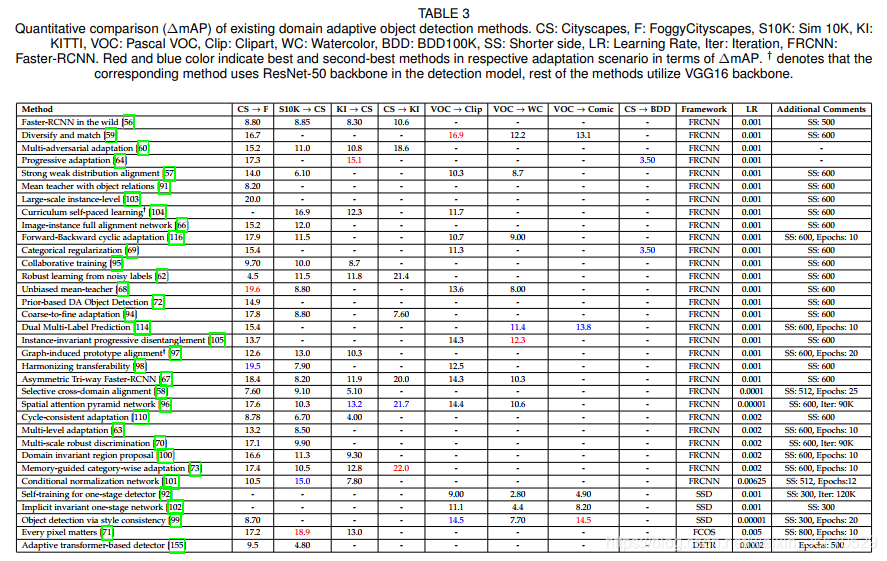
表2中报告的性能比较使用了各自论文中报告的绝对mAP性能。 需要注意的是,这种比较并不一定是公平的,原因如下:每种方法使用不同版本的基线检测器。 即使是使用Faster-RCNN作为基线检测器的方法也是如此。 这些方法使用不同的超参数来训练基线。 例如,Chen等人[56]使用具有ROI池化的FasterRCNN和边长为500像素的图像,而Cai等人[91]使用具有ROI-align的FasterRCNN和边长为600像素的图像。 此外,在不同的方法中还有其他一些差异,如epoch的数量、学习速率等。 因此,为了提供一个公平、全面的比较,我们考虑相对mAP的改进,记为∆mAP,它是特定方法的性能与相应的纯源基线在各自的论文中报告的性能之间的差异。 虽然∆mAP仍然不是一个完美的比较度量,但我们认为,它比使用不同超参数训练的方法的绝对mAP要好。 由于文献中所有方法都以相同的超参数训练纯源基线和最终方法,所以∆mAP将消除各自方法超参数对性能的大部分影响。 所有方法的∆mAP度量见表3。
通过比较这两个表,我们可以了解到任何特定的适应方案多年来的绩效趋势。 以![]() 为例,其中,从表2可以看出,前后循环适应[116]方法比渐进适应[64]策略更好。 然而,考虑到∆mAP的性能,两种方法得到的性能提升相似。 这表明城市景观BDD100K场景有待后续工作进一步探索。 对恶劣天气适配的案例(Cityscapes到FoggyCityscapes),并观察到自第一个工作以来,mAP已经有了约20个改进。 从表2的绝对mAP比较来看,基于Transformer的适配和记忆导向的自适应的性能是最好的和次优的。 然而,从∆mAP比较中可以观察到,无偏的mean-teacher和harmonizing transferability比它们各自的source-only基线得到了最大的改善。 在其他适应方案中也观察到类似的趋势,例如Sim10K的绝对mAP ! 城市景观,基于Transformer的方法[78]表现最好。 相比之下,当考虑∆mAP时,基于每像素事项的方法[71]表现最好。 注意Sim10K到Cityscape,条件归一化[101]的绝对mAP和∆mAP的性能都是第二优的。 在PascalVOC到Comic中也可以观察到类似的结果,风格一致性[99]是绝对mAP和∆mAP度量的最佳表现方法。
为例,其中,从表2可以看出,前后循环适应[116]方法比渐进适应[64]策略更好。 然而,考虑到∆mAP的性能,两种方法得到的性能提升相似。 这表明城市景观BDD100K场景有待后续工作进一步探索。 对恶劣天气适配的案例(Cityscapes到FoggyCityscapes),并观察到自第一个工作以来,mAP已经有了约20个改进。 从表2的绝对mAP比较来看,基于Transformer的适配和记忆导向的自适应的性能是最好的和次优的。 然而,从∆mAP比较中可以观察到,无偏的mean-teacher和harmonizing transferability比它们各自的source-only基线得到了最大的改善。 在其他适应方案中也观察到类似的趋势,例如Sim10K的绝对mAP ! 城市景观,基于Transformer的方法[78]表现最好。 相比之下,当考虑∆mAP时,基于每像素事项的方法[71]表现最好。 注意Sim10K到Cityscape,条件归一化[101]的绝对mAP和∆mAP的性能都是第二优的。 在PascalVOC到Comic中也可以观察到类似的结果,风格一致性[99]是绝对mAP和∆mAP度量的最佳表现方法。
4.4.1 Is one category of adaptation methods better than the other category of approaches?
在讨论了所有类型的方法(即对抗性特征学习、伪标签自我训练等)并比较了它们的性能后,人们自然会想,是否有一类方法比其他方法更好。
从表2和表3可以看出,不同类型的方法中没有明显的赢家。 例如,鲁棒学习[62]是一种基于伪标签的自训练方法,在许多自适应实验中,它优于基于对抗特征学习的方法适配faster-rcnn[56]。 然而,许多基于对抗性特征学习的方法在各种适应性场景中都优于鲁棒学习[62]。 每种适应策略都有其优缺点。 例如,对抗性特征学习(在第3.1节中讨论的基于训练在实践中是不稳定的,需要仔细的参数调整和正则化来稳定特征适应过程。 然而,在适当的超参数和正确的正则化下,对抗性特征学习可以提供显著的性能改进。 最可能的原因是,文献中使用的最流行的策略是基于特征学习的对抗性方法。 相反,使用伪标签进行自训练(在3.2节中讨论),训练曲线较为稳定,因为通过源训练模型得到的伪标签可以利用监督检测损失对网络进行监督训练。 然而,基于自训练的方法需要小心伪标签中的噪声,因为这种噪声可能会被潜在地强化到模型中,从而导致次优性能。 因此,大多数基于自我训练的方法只使用置信度的预测。
基于图像到图像转换的方法(在第3.3节中讨论)通过解决输入空间中的域间隙来避免此类训练相关问题。 通常,会添加一个图像翻译模块,将源样本转换为类目标样本,反之亦然。 由于类目标样本易于获得监督,因此可以更好地训练模型,从目标域对原始样本进行检测。 然而,这种策略在很大程度上依赖于图像转换模块学习源域和目标域之间完美映射的效率。 因此,大多数图像对图像的翻译方法额外利用了对抗性特征学习和/或自训练策略,可以弥补图像翻译模块所犯的一些错误。
另一方面,基于域随机化(在第3.4节中讨论)的方法是创建源域的多个风格化版本,以确保检测模型没有来自源域的样式偏差,并专注于其他重要的鉴别特征来检测目标。 然而,为了使检测器完全从任何特定的领域去偏,在训练过程中需要包含许多随机领域,这可能是不可行的。 为了解决这个问题,领域随机化方法还在源、程式化源和目标域之间应用了对抗性特征学习。
Mean-teacher训练(在3.5中讨论)是另一种通过Mean-teacher更新使检测器适应目标域的流行策略。 Mean-teacher已经成功地用于迁移学习,最初被提出用于利用相似领域的无标记数据。 这些方法利用额外的正则化或特征匹配策略来扩展mean-teacher以实现无监督域适配。
类似地,基于图推理(在3.6中讨论)的方法旨在理解源域的任何给定样本中的目标关系,并试图利用这些信息确保目标域也遵循类似的关系。 通过对目标特性施加某些约束,这有助于源域和目标域之间的知识转移。 这些不同类别的方法大多数是相互排斥的,可以以不同的方式组合起来,以利用每个战略的好处,同时减轻其他战略的缺点。 例如,unbiased mean-teacher结合了mean-teacher training、对抗特征学习和图像到图像翻译,证明其表现优于大多数其他文献工作。
5、研究方向
正如前面所讨论的,已经提出了各种方法来解决使深度目标检测器适应不同场景的挑战性问题。 在本节中,我们将探讨突出的问题以及潜在的解决方案和未来的研究方向。 在下面的小节中,我们将讨论两大类问题和方向:(i)综合评价和(ii)利用现实世界的约束改进泛化。
5.1、Comprehensive evaluation
通过大量可用的方法,我们明确了一些与评估方案有关的问题。 我们认为,解决这些问题将导致一个更有力和更严格的评价进程。
Generalizing to other detection frameworks
大多数现有的目标检测域适配方法仅在FasterRCNN检测框架上进行评估。 此外,这些方法中的一些,如[56],是在假设两阶段检测过程的情况下设计的。 然而,考虑到单阶段检测方法如YOLO、SSD的流行,以及最近的一些方法如FCOS和DETR,评估使用其他框架的自适应方法的性能也很重要。 对这一额外类别的检测方法的评估将验证适应性方法是否适用于不同的检测器。
Complex real-world datasets
域适配目标检测的初始方法如DA-Faster、SWDA等,基于FoggyCityscapes、Sim10K、Pascal VOC等现有数据集设计了评估协议,后续的方法遵循类似的协议。 值得注意的是,其中一些数据集和协议并不是专门构建来反映现实世界的分布差距的。 例如,考虑构建自动驾驶系统的情况,构建源和目标数据集是很重要的,因为分布差距是由多种因素引起的,如天气条件、地理位置、车辆类型、背景类型、车辆密度等。 考虑到这一点,构建反映真实世界场景的复杂数据集是至关重要的,以便实现更严格和稳健的评估过程。
Considering other applications
域适配文献中现有的方法主要集中于自主导航人群监控和常见的一般目标等应用。 然而,在域适配检测的背景下,许多其他真实世界的应用很少被探索,如医学成像,场景文本,文档目标象。 例如,考虑一个病变检测模型训练光学相干断层扫描(OCT)图像从一个特定的设备。 当从另一个设备捕获相应的图像时,OCT图像分布会发生变化。 在这种情况下,对病变检测模型进行无监督适应以提高跨设备性能变得至关重要。 因此,为这些很少被探索的应用开发适应策略变得很重要,因为它们具有重大的现实意义。
Consistent training and inference strategy
尽管大多数领域自适应检测方法在Faster-RCNN检测框架上显示了它们的有效性,但我们观察到训练和推理策略并不统一。 从表2可以看出,不同方法的学习率、训练时长等超参数是不同的。 虽然有人可能会认为这是超参数调优的结果,但需要注意的是,这些超参数与骨干网的关联更大,它们的变化可能是性能变化的潜在原因。 因此,保持与骨干网相关的一致的超参数是重要的,以执行一个公平的方法比较。 同样,不同的方法使用不同的输入图像的大小比例,这直接影响检测性能。 考虑到这些观察结果,重要的是建立一致和统一的训练/推理策略,使读者能够获得评价结果的公平视角。
5.2、Improving generalization with real-world constraints
在本节中,我们将关注潜在的未来研究方向,考虑一些现实世界的设置,这些设置通常被现有的方法忽略。 大多数现有的方法都是基于在现实世界中不一定正确的假设。 例如,通常认为,(i)样本的数量在源和目标类数据集被认为是平衡,(ii)中存在的所有类源数据集存在于目标数据集,反之亦然,(3)源数据总是可用的目标领域适应期间, (iv)所有的目标域样本都是未标记的,(v)训练时存在大量未标记的目标域样本。 我们讨论各种各样的问题设置,这样的假设是宽松的,由此产生的挑战和可能的策略来克服它们。 此外,我们还讨论了其他策略,如多源领域适应、测试时间适应和现实世界实践设置所必需的连续适配。
Weak/semi-supervised domain adaptation
无监督域自适应是特别有用的,因为标注目标域样本是劳动密集型和昂贵的目标检测任务。 但是,在某些情况下,可以为目标样本的子集获得边界框注释,或者提供指示类别存在/不存在的弱图像级注释。 在这种情况下,可以利用关于目标域的这些额外知识进一步提高目标域的性能。 对于弱监督域自适应,每个图像在图像级别上标注,以指示图像中存在/不存在哪些类别,并且不提供边界框注释。 Inoue等人是文献中唯一通过弱注释引导的图像到图像翻译和伪标签训练策略来解决这一问题的研究。 目标域数据集的子集完全用边界框和各自的类别标注来进行半监督域自适应。 Liu等人提出使用带注释的子集,并使用相对较大的未标记数据子集,进行无偏见的教师和学生培训,以提高检测性能。 虽然Liu等人没有广泛评估领域自适应检测基准,但它提供了一个潜在有用的策略,可以很容易地用于领域自适应情况。 因此,利用弱监督和半监督来进一步探索完全监督和适应性训练之间的绩效差距是很重要的。
One/few-shot domain adaptation
传统的无监督域自适应假设在自适应过程中需要从目标域获取大量的未标记样本。 然而,在许多现实情况下,这可能并不适用,其中数据是一组输入图像[115],导致在适应训练期间从目标域获得一个或几个未标记样本。 为了解决目标领域特定的适应性策略中的这种样本稀缺问题,需要充分利用可用数据集。 D 'Innocente等是唯一通过增加辅助的自我监督损失来探索单样本自适应问题的方法,在自适应检测领域的文献中尚未探索少样本自适应。 一个解决目标检测器单样本/少样本自适应的简单策略是应用图像程式化来增加未标记目标域样本池,并通过使检测器域不变来应用传统的特征匹配策略。 另一种策略是对目标域中可用的一幅或几幅图像进行标记,并对注释样本丰富的源域和样本稀缺的目标域进行监督域自适应。
Imbalanced classes
现实世界中的物体频率通常遵循幂律,这种不平衡类的问题通常被现有的假设类空间对齐的域自适应检测方法所忽略。 这种假设限制了该方法在现实世界中经常遇到的不平衡任务,特别是目标检测任务中的性能。 因此,在执行域对齐时,重要的是要避免任何特定类的主导地位。 这个问题的一个明显的解决方案是基于频率重新加权类。 但是,在目标数据集没有样本标记的情况下,该策略是不可行的。 因此,开发可以估计目标数据集中的类分布的方法是很重要的,这样就可以用于重新加权类。
Partial domain adaptation
与类别不平衡问题相关的一个问题是部分域适应问题。领域自适应文献中的一个典型假设是源数据集和目标数据集之间的标签空间是完全共享的。也就是说,源数据集和目标数据集具有相同数量的类。然而,现实世界的设置可能不能完全反映这个场景。目标数据集中的类往往比源数据集中的类少得多。在这种情况下,将源域与目标域完全对齐可能会导致负迁移。因此,重要的是通过降低属于离群源类的数据样本的权重来缓解负迁移问题,从而仅在共享标签空间中促进特征对齐(正迁移)。
Open-set domain adaptation
与部分域自适应问题类似,开放集DA处理源域和目标域之间标签空间不完全共享的问题。但是,在这种特殊情况下,目标域包含源域中没有观察到的未知类。这个问题也导致了负迁移;然而,识别目标数据集中的未知类样本具有挑战性,我们需要借鉴开放集识别任务的原则,以便在域对齐过程中自动降低这些样本的权重。
Source-free domain adaptation
现有的域自适应检测方法的一个常见假设是,在域自适应训练中,源域的样本是可用的。然而,在现实场景中,由于隐私问题、法律问题和低效的数据传输,获得源数据的访问可能不现实。为此,我们必须解决无源域自适应目标检测的问题,即在自适应过程中,不能访问源数据,而只能访问源训练模型。一种明显的方法是基于伪标签的自我训练,即首先在目标上生成伪标签,然后再利用它们来监控目标数据上的网络。然而,重要的是通过过滤掉不正确的标签来生成高可靠的伪标签。
Multi-source domain adaptation
所有现有的领域自适应目标检测方法都假设标记的训练数据是从单个领域采样的。这忽略了从多个来源收集训练数据的更实际的场景。例如,考虑一个自动驾驶系统的情况,源数据来自多个城市,总体目标是适应一个新的城市。由于源数据集来自多个城市,因此这些数据点可能对应于多个子分布。将目标数据与所有这些子发行版对齐不一定会获得最佳性能。因此,在只考虑相关源样本的情况下,进行选择性适应是至关重要的。
Continuous and test time adaptation
现有的域自适应检测方法将世界划分为静止域。然而,在许多真实的应用程序中可能不是这样的,在这些应用程序中,样本来自不断发展的底层流程。例如,视频中光线/天气条件逐渐变化。因此,一个更实际的领域适应设置是考虑终身学习问题的预训练模型适应动态变化的环境条件。这个设置反映了一个真实的场景,我们遇到来自新目标环境的未标记图像,这些图像在训练中没有被观察到。因此,在我们只能访问一个或几个目标域数据实例的情况下,开发适应测试时的策略是很重要的。需要注意的是,这些策略应该考虑额外的约束,如计算成本低的适应、对源域数据的限制访问以及灾难性遗忘问题,这是持续学习产生的一个突出问题。为了适应动态变化的环境,需要这样的约束条件。
6、结论
在本文中,我们考虑了深度目标探测器的无监督域适应,并提出了一个广泛的调查现有的方法来完成这项任务。我们详细地回顾了过去几年发表的50种方法。我们提供了现有方法的全面分类,然后详细分析了各种方法及其优缺点。随后详细讨论了现有的数据集、评估协议和综合性能比较。最后,我们确定了一些突出的问题和有趣的方向,以推动未来的研究。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











