







Generative Adversarial Network
GAN的概述
GAN的思想就是:这是一个两人的零和博弈游戏,博弈双方的利益之和是一个常数,比如两个人掰手腕,假设总的空间是一定的,你的力气大一点,那你就得到的空间多一点,相应的我的空间就少一点,相反我力气大我就得到的多一点,但有一点是确定的就是,我两的总空间是一定的,这就是二人博弈,但是呢总利益是一定的。
用一个形象的例子解释就是:GAN就好比是一个大的网络,在这个网络中有两个小的网络,一个是生成网络,可以当做是制作假钞的人, 而另一个是鉴别网络,也就是鉴别假钞的人。对于生成网络的目标就是去欺骗鉴别器,而鉴别器是为了不被生成器所欺骗。模型经过交替的优化训练,都能得到提升,理论证明,最后生成模型最好的效果是能够让鉴别器真假难分,也就是真假概率五五开。
上图是生成对抗网络的结构示意图,鉴别器接受真实样本和生成器生成的虚假样本,然后判断出真假结果。生成器接受噪声,生成出虚假样本。
GAN的原理
下式是GAN的目标函数公式:
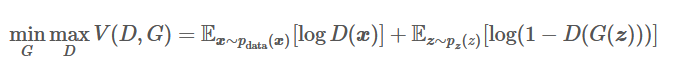
从目标函数可以看出,整个代价函数是最小化生成器,最大化鉴别器,那么在处理这个最优化问题的时候,我们可以先固定住G,然后先最大化D,然后再最小化G得到最优解。其中,在给定G的时候,最大化 V(D,G) 评估了P_G和P_data之间的差异或距离。
首先,在固定G之后,最优化D的情况就可以表述为:
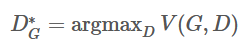
最优化G的问题就可以表述为:
![]()
理论推导
在论文原文推导过程中采用的是JS散度来描述两个分布的相似程度,而JS散度其实使用KL散度构建出来的,因此,在进行完整推导之前,先介绍一些理论基础,在进行推导最优鉴别器和最优生成器所需要的条件,最后利用推导的结果重述训练过程。
KL散度
对与同一个随机变量 x
有两个单独的概率分布 P(x) 和 Q(x),用KL散度可以衡量这两个分布的差异(附录会有证明为何KL散度能说明两个分布的差异):

KL散度的性质:
- 非负性(这个性质后面推导会用到),同时当且仅当P和Q相同分布时候,KL散度才会为0。因为这个非负性,所以它可以经常用来衡量两个分布之间的差异。(附录会证明其非负性)
- 非对称性, 虽然可以衡量分布的差异,但是这个差异的距离不是对称的,所以KL散度在P对于Q下的和Q对于P下两种情况是不同的。
论文推导过程中的问题
在原论文中,有一个思想和许多方法都不同,就是生成器G不需要满足可逆条件,在实践中,G确实就是不可逆的。但是在证明的过程中,大家都错误的使用了积分换元公式,而这个积分换元是只有当G满足可逆条件时候才能使用。所以证明应该是基于下面这个等式的成立性:

该等式来源于测度论重的Radon-Nikodym定理,它在原论文中的命题1中被展示,并表述为下列等式:

这个公式中使用了积分换元公式,但是使用换元就必须计算G的逆,而G的逆没有被假定存在。而且在神经网络中的实践中,它也不存在。不过这方法在ML中太常见了,因此就忽略了。
最优判别器
在极小极大博弈中,首先固定生成器G,最大化价值函数,从而得出最优判别起D。其中,最大化的价值函数评估了生成器生成的数据分布和数据集分布的差异(后面会证明)。
在原论文中的价值函数可以将其数学期望展开成为积分的形式:

通过求积分的最大值可以转化为求被积函数的最大值。通过求被积函数的最大值可以求的最优判别器D,因此可以把不涉及到鉴别器的项都看作是常数项,令鉴别器D(x)为y,则被积函数可以表示为:
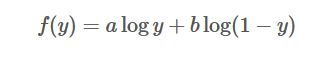
为了寻找最优的极值点,如果a+b≠0,可以用来进行下一阶导求解:
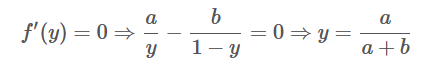
通过在其驻点进行二阶导求解可得:

其中a,b∈(0,1)。因为一阶导等于0,二阶导小于0,因此aa+b
时就是极大值。
最后就可以将价值函数写为:
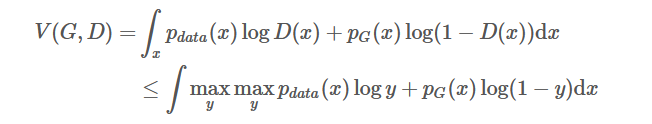
令D(x)=P_data/(P_data+p_G),就可以取得极大值,因为在丁一宇内f(y)拥有唯一的极大值,也就是说最优D是唯一的,并且没有其他的D能实现极大值。
事实上,最优D在实践中是无法被计算,但是在数学上很重要。此外,我们不知道先验的Pdata,所以我们不能直接在训练中使用它。另一方面来说,最优D的存在证明了最优G,而且我们只要趋向于最优的D就可以了。
最优生成器
GAN的训练过程就是为了让P_G=P_data,那么最优D就可以表示为:
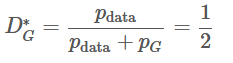
也就是最优的生成器会使得鉴别器无法辨别P_data和P_G。基于这个观点,论文作者证明了G就是极大极小博弈的解。
定理:当且仅当P_G=P_data的时候,C(G)=maxV(G,D)的全局最小点可以达到。
定理中说该结论是当且仅当是成立,因此从两个方向证明。首先反向逼近,证明C(G)的取值,然后从正向证明。
假设P_G=P_data(反向预先知道结果进行推到),可以反向推出:
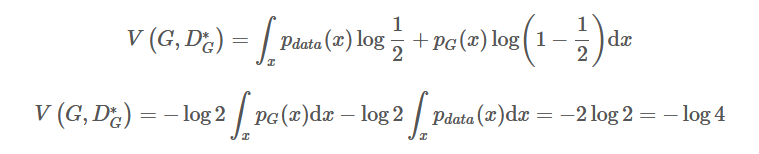
那么-log4就是最小值的候选,因为只有在P_G=P_data的时候才出现。现在就要从正向证明这个值常常是最小值,也就是同时满足当且仅当的条件。
现在放弃P_G=P_data的条件,选取任何的G,改写公式为:
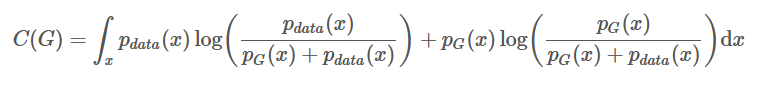
下面会应用一个trick,给方程增加一个0,不改变方程的值,但是可以构建出一个log2,因为我们知道-log4是全局最小值的候选。

最后化简可以得到:
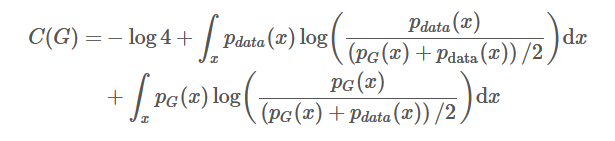
如果阅读了前面kl散度的部分,就可以发现他可以化简为kl散度的形式:

由于KL散度是非负的,所以-log4就是全局最小值。
接下来只需要证明只有这一个G能达到这个值,这样P_G=P_data就成为了唯一解,整个证明就完成了。
从前文可以KL散度是非对称,只能衡量分布a对于分布b的相似度,但是加上了后面那项以后,他们的和就是对称得了,这个时候,这两项的和就能用JS散度来表示:
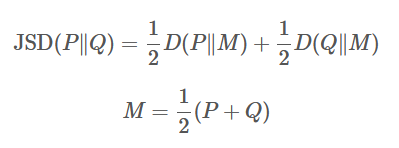
假设存在两个分布P和Q,且这两个分布的平均分布M=(P+Q)/2,那么这两个分布之间的JS散度就是P和M之间的KL散度加上Q和M之间的KL散度除以2。
因此JS的散度取值范围是0到log2。当两个分布完全不存在交集则为log2, 当完全一样的时候则是最小值0.
因此C(G)可以改写为:
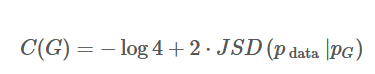
也就证明了,当P_G=P_data时,JSD为0。综上,当生成的分布当且仅当等于真实数据分布的时候,我们取得了最优的生成器。
收敛性
关于训练过程中能否收敛到最优的生成器,原论文有额外的证明表示,当具有足够的训练数据,d和g有足够的性能时候,是可以收敛到最优G,因为这块内容不是特别重要,证明我会放在附录(主要我也看的一知半解)
训练过程
1.参数优化过程
若我们要寻找最优的生成器,在确定一个鉴别器D以后,我们可以把原本的价值函数看作是训练生成器的损失函数L(G)。有了损失函数,就可以通过SGD,Adam等优化算法更新我们的生成器,梯度下降的优化过程如下:
![]()
现在给定一个初始的G_0,需要找到令V(G_0,D)最大的D_0*,因此鉴别器的更新过程就是损失函数:-V(G,D)的过程。并且有前面的推导可知,V(G,D)实际上与分布P_data(x)和P_G(x)之间的JS散度只相差了一个常数项,因此这样的循环对抗过程能表述为:
- 给定G_0,最大化V(G_0,D)以求得D_0*,即max[JSD(P_data(x)||P_G0(x))];
- 固定D_0*,计算θ−G1←θ−G0−η(∂V(G,D−0∗)/∂θ−G)
- ,求得更新后的G_1;
- 固定G_1,最大化V(G_1,D_0)以求得D_1,即max[JSD(P_data(x)||P_G1(x)];
- 固定D_1*,计算θ−G2←θ−G1−η(∂V(G,D−0∗)/∂θ−G)
- 以求得更新后的G_2;
如此循环
2.实际训练过程
根据前面价值函数V(G,D)的定义,我们需要求两个数学期望,即E[log(D(x))]和E[log(1-D(G(z)))],其中x服从真实数据分布,z服从初始化分布。但在实践中,我们是没用办法利用积分求这两个数学期望,所以一般只能通过从无穷的真实数据和无穷的生成器中采样来逼近数学期望。
假设现在给定生成器G,并希望计算maxV(G,D)来求鉴别器D,那么首先我们需要从P_data(x)中采样m个样本,从生成器P_G(x)采样m哥样本。因此最大化价值函数可以用下面表达式代替:
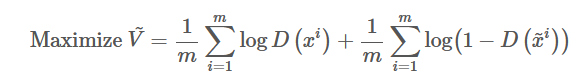
现在我们将从P_data(x)中抽取的样本作为证样本,从P_G(x)抽取的样本作为负样本,同时逼近负V(G,D)的函数作为损失函数,因此就可以将其表述为一个标准的二分类器的训练过程:
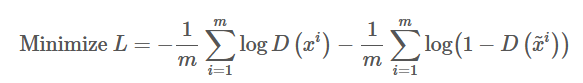
在实践中,我们必须使用迭代和数值计算的方法来实现极大极小化的博弈过程。在训练的内部循环中完整优化D在计算上是不允许的,而且有限的数据集会导致过拟合。因此我们可以在k个优化D步骤和一个优化G的步骤交替进行。只要慢慢更新G,D就会一直处于最优解的附近。
综上,在整个训练过程中,对于每一次迭代:
- 从真实数据分布P_data中抽取m个样本
- 从先验分布P_prior(z)抽取m个噪声样本
- 将噪声样本输入到生成器G中生成数据{x~1,x~2,…,x~m},x~i=G(zi)
,通过最大化V的近似而更新鉴别器参数θ−d,鉴别器参数的更新迭代公式为θd←θd+η∇V~(θd)
以上是学习鉴别器D的过程。因为学习的过程是计算JS散度的过程,并且会重复k次,因为我们希望能够最大化价值函数。
- 从先验分布P_prior(z)中抽取另外m个噪声样本
- 通过极小化V,也就是V~=1m∑mi=1log(1−D(G(zi))),且生成器参数的更新迭代式为θg←θg−η∇V~(θg)
以上是生成器参数的学习过程,这个过程只会在一次迭代中出现一次,因此能避免更新太多使得js散度上升。
以上便是GAN的完整推导过程和论证。
GAN训练的几个问题
训练不稳定
原始的GAN训练非常困难。主要体现在训练过程中可能并不收训练出得生成器根本不能产生有意义的内容等方面。另一方面,虽然说我们的优化目标函数是js散度,他应该能体现处两个分布的距离。并且这个距离一开始最好比较大,最后随着训练G过程的深入,这个距离应该慢慢变小才比较好。
在实际过程中,鉴别器的损失函数非常容易变成0,而且在后面的过程中也一直保持0。js散度是用来衡量两个分布之间的距离,但实际上有两种情况会导致js散度判定两个分布距离是无穷大,从而使得lossfunction永远是0。
情况1: 鉴别器D过强,导致了过拟合。
解决方法:尝试使用正则化,或者减少模型参数
情况2: 数据本身的特性。生成器产生的低维流型确实不容易产生重叠。
解决方法:一种是给数据添加噪声,让生成器和真实数据分布更容易重叠 还有一种方法是下次要将的GAN
模式崩溃 mode collapse
所有的输出都一样!这个现象被称为Mode Collapse。这个现象产生的原因可能是由于真实数据在空间中很多地方都有一个较大的概率值,但是我们的生成模型没有直接学习到真实分布的特性。为了保证最小化损失,它会宁可永远输出一样但是肯定正确的输出,也不愿意尝试其他不同但可能错误的输出。也就是说,我们的生成器有时可能无法兼顾数据分布的所有内部模式,只会保守地挑选出一个肯定正确的模式。
总结
- GAN结合了生成模型和鉴别模型,消除了生成模型的损失函数难以定义的问题
- 基于概率分布来计算,不受生成维度的限制
- 可以用来进行半监督学习















 740
740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











