







编程实现文件合并和去重操作
对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。下面是输入文件和输出文件的一个样例供参考。
目标:原始数据中出现次数超过一次的数据在输出文件中只出现一次。
算法思想:根据reduce的过程特性,会自动根据key来计算输入的value集合,把数据作为key输出给reduce,无论这个数据出现多少次,reduce最终结果中key只能输出一次。
1.实例中每个数据代表输入文件中的一行内容,map阶段采用Hadoop默认的作业输入方式。将value设置为key,并直接输出。 map输出数据的key为数据,将value设置成空值
2.在MapReduce流程中,map的输出<key,value>经过shuffle过程聚集成<key,value-list>后会交给reduce
3.reduce阶段不管每个key有多少个value,它直接将输入的key复制为输出的key,并输出(输出中的value被设置成空)。
用一行作为key,value是空,那么在reduce时进行“汇总”,还是只有一个key,即一行,value还是空。所以即去重了。
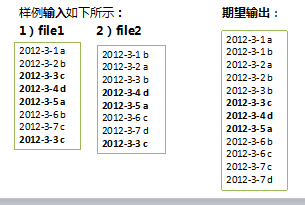
输入文件A的样例如下:
| 20150101 x 20150102 y 20150103 x 20150104 y 20150105 z 20150106 x |
输入文件B的样例如下:
| 20150101 y 20150102 y 20150103 x 20150104 z 20150105 y |
根据输入文件A和B合并得到的输出文件C的样例如下:
| 20150101 x 20150101 y 20150102 y 20150103 x 20150104 y 20150104 z 20150105 y 2015010 z 20150106 x |
代码:
package org.apache.hadoop.examples;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class FileMerge {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();//获得程序参数 放到otherArgs中
// String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
String[] otherArgs=new String[]{"input","output"}; /* 直接设置输入参数 设置程序运行参数 */
if(otherArgs.length < 2) {//没有指定参数
System.err.println("Usage: FileMerge <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "FileMerge");//设置环境参数
job.setJarByClass(FileMerge.class);//设置整个程序的类名
job.setMapperClass(FileMerge.Map.class);//添加Mapper类
job.setCombinerClass(FileMerge.Reduce.class);//添加combiner类
job.setReducerClass(FileMerge.Reduce.class);//添加reducer类
job.setOutputKeyClass(Text.class);//设置输出类型
job.setOutputValueClass(Text.class);//设置输出类型
//System.exit(job.waitForCompletion(true) ? 0 : 1);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));//设置输入文件
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));//设置输出文件
Path path = new Path(otherArgs[1]);// 取第1个表示输出目录参数(第0个参数是输入目录)
FileSystem fileSystem = path.getFileSystem(conf);// 根据path找到这个文件
if (fileSystem.exists(path)) {//如果存在output文件夹则删除
fileSystem.delete(path, true);// true的意思是,就算output有东西,也一带删除
System.exit(job.waitForCompletion(true)?0:1);
}
}
//实现map函数
public static class Map extends Mapper<Object, Text, Text, Text> {//继承mapper父类 //接收一个文件名作为key,该文件的每行内容作为value
private Text line = new Text();//每一行作为一个数据
public Map() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, Text>.Context context) throws IOException, InterruptedException {
context.write(value, new Text(""));//把每一行都放到text中 唯一的key实现了去重
}
}
// reduce将输入中的key复制到输出数据的key上,并直接输出,这是数据去重思想
public static class Reduce extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
context.write(key, new Text("")); //map传给reduce的数据已经做完数据去重,输出即可
}
}
}















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









