







1 序
1943年,心理学家McCulloch和数学家Pitts建立起了著名的阈值加权和模型,简称为M-P模型,其拓扑结构便是现代神经网络中的一个神经元,发表于数学生物物理学会刊《Bulletin of Methematical Biophysics》。1957年,以Marvin Minsky,Frank Rosenblatt,Bernard Widrow等为代表人物发表了感知机模型,并提出学习的概念,被称为最早的神经网络。
本文主要介绍M-P模型与感知机的区别与联系,以及感知机与现代神经网络的区别与联系,从而对几十年来人工神经网络的发展脉络有一个感性的认识以便更好地理解神经网络。
2 M-P模型
前面说了M-P模型便是现代神经网络的一个神经元,其结构十分简单,如图1所示
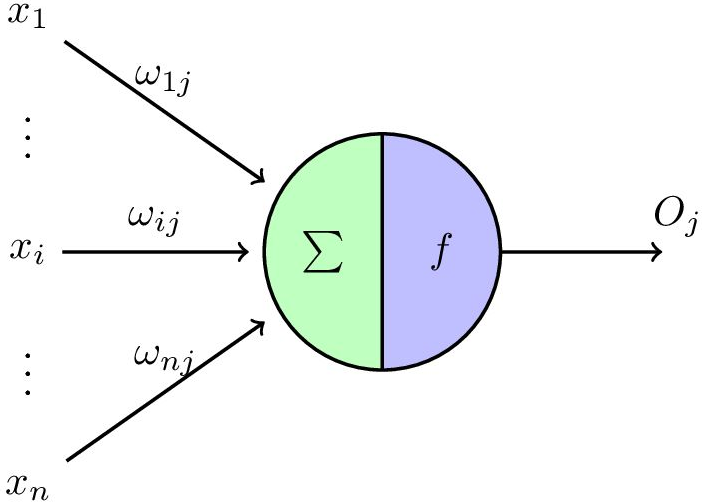
其数学表达式为:
O
j
=
f
(
∑
i
=
1
n
w
i
x
i
+
b
)
O_j=f(\sum_{i=1}^nw_ix_i+b)
Oj=f(i=1∑nwixi+b)
f
f
f为激活函数,这儿使用阶跃函数,大于0时取1,小于等于0时取0。可以看出M-P模型就是一个加权求和再激活的过程,能够完成线性可分的分类问题。
需要注意的一点时,M-P模型的权值
W
W
W 和偏置
b
b
b 都是人为给定的,所以对此模型不存在"学习"的说法。这也是M-P模型与单层感知机最大的区别,感知机中引入了学习的概念,权值
W
W
W 和偏置
b
b
b 是通过学习得来。
3 感知机
3.1 单层感知机
从结构上说,单层感知机就是多个M-P模型的累叠,模型结构如图2。前面也说到了,最主要的差别还是在于感知机引入了学习概念,这也是为什么把感知机称为最初的神经网络模型而非M-P模型。
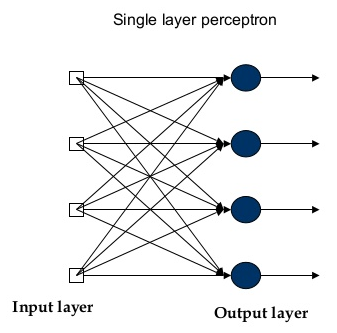
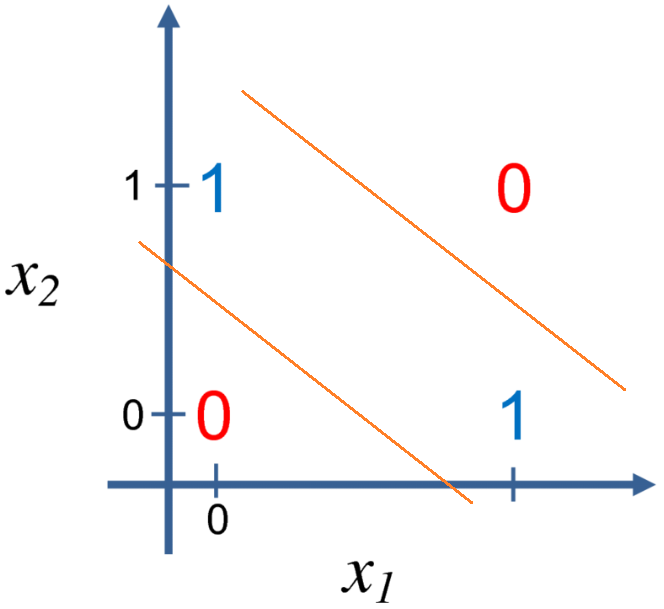
单层感知机的学习通过导入基于误分类的损失函数,利用梯度下降法对损失函数进行极小化(注意,1957年BP反向传播算法还未提出,所以只能训练一层网络)。在结构上单层感知机和M-P模型没有太大区别,所以也只能划分线性可分问题,并不能解决异或之类的线性不可分问题,如图3
3.2 多层感知机
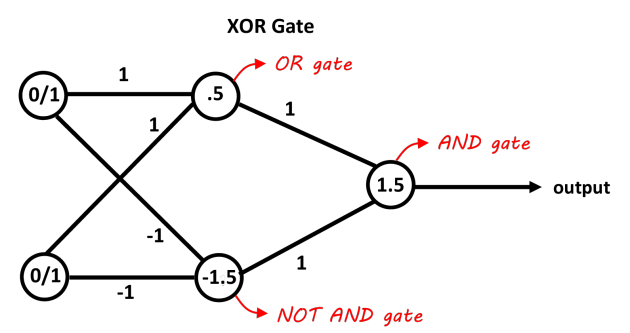
为了解决线性不可分问题,提出了多层感知机(基本都是两层,因为BP算法提出之前只能训练一层网络)。因为只能训练一层网络,所以多层感知机其中一层是固定权值的,能够解决非线性问题,如图4.
4 总结
M-P模型就是现在的一个神经元结构,但是没有参数学习的过程,单层感知机引入损失函数,并提出了学习的概念,多层感知机通过增加层数解决非线性问题,但是需要人为固定一层参数,只能训练其中一层。直到1986年Hinton提出了反向传播算法,使得训练多层网络成为可能。在GPU并行运算能力的大力发展下,网络的层数得以不断增加,新的网络模型也越来越多,感知机也逐渐退出了历史舞台,但了解一个领域的发展历史对理解这个领域还是很有用的。

















 1079
1079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









