







M-P模型:它是首个通过模仿神经元而成的模型,其中只有两层:输入层x1…xn和输出层y;权值w1…wn。
但是由于M-P的权值只能事先给定,不能自动确定权值,感知器应运而生。
↓
感知器:可以根据有监督学习,自动确定权值。设定训练样本和期望输出,以误差修正方法来调整实际权值。
但感知器只能解决线性可分问题,不能解决线性不可分问题
↓
初期多层感知器被提出来解决线性不可分问题
↓
但是由于误差修正只能针对单层修正,不能跨层修正,初期多层感知器的只能对中间层和输入层之间的参数进行修正,不能对其它层进行误差修正学习,所以后来有了BP(误差反向传播)的多层感知器来改进这点。
↓
BP下的多层感知器。
目录
1. M-P模型
1.1 最基础的m-p模型:

由上图所示,M-P模型由多个输入节点 {x
i
_i
i|i= 1,2,3…n} 且 x
i
_i
i= {0,1} 和连接权值 {w
i
_i
i|i= 1,2,3…n} 组成,对应一个输出节点y。
整个图可以写做一个公式:
![]()
其中 MP模型里的 激活函数f (我称他为激活函数)是 :

以h为阈值,令u i _i i=∑w i _i ix i _i i,y=f(u i _i i), 当u i _i i) ≥ h,y=1; 否则,y=0。
1.2 NOT/ AND/ OR 的m-p模型:
1.2.1 NOT :
只需要把激活函数的规则改变:
以h为阈值,令u
i
_i
i=∑w
i
_i
ix
i
_i
i,y=f(u
i
_i
i), 当u
i
_i
i) ≥ h,y=0; 否则,y=1。
1.2.2 AND :
拿两个输入的AND模型来举例说明:( x
i
_i
i= {0,1} )

可以令w1=0.5, w2=0.5,而h=1 实现AND模型,( 当然w1,w2,h取别的值也可以。
1.2.3 OR :
拿两个输入的OR模型来举例说明:( x
i
_i
i= {0,1} )
可以令w1=0.5, w2=0.5,而h=0.5 实现OR模型,( 当然w1,w2,h取别的值也可以。
2. 感知器
通过1中的M-P模型,我们大概有了一个,输入x
i
_i
i, 输出y,连接权值w
i
_i
i,和激活函数 f 的概念。
但是1中的连接权值w
i
_i
i都是人工设置的,这样在实际应用来说,很不实用。我们更需要的是机器去自动寻找最合适的连接权值w
i
_i
i。由此,罗森布拉特提出了感知器的概念,感知器通过1. 有监督学习下训练训练样本; 2. 误差修正 得到合适的连接权值参数w
i
_i
i。从而实现了不需要人为干预自动寻找到权值。
误差修正学习 公式:

· a是确定连接权重调整值的参数,可以称为学习率;a增加则误差修正速度增加,但是太大会影响训练的稳定性;a减少则误差修正速度降低,但是太低会导致收敛速度太慢;
· r是期望输出(有监督学习/ 有教师学习); y是实际输出
感知器的基本思路是:
利用随机数来初始化各项参数;
逐个加入训练样本,实际输出 y 与期望输出 r 相等时,w
i
_i
i, h不变;实际输出 y 与期望输出 r 不相等时,调整 w
i
_i
i, h;
直到 误差为0 或者小于某个特定数值。
( 由于 w i _i i 的调整乘以 x i _i i , 而 x i _i i= {0,1} ,则只能针对 x i _i i= 1 的权值 w i _i i 进行调整:
- 实际输出 y=0, 期望输出 r=1 时 ---- 未激活 :
h减少; 增加 x i _i i= 1 的权值 w i _i i ; x i _i i= 0 的权值 w i _i i 不变。 - 实际输出 y=1, 期望输出 r=0 时 ---- 激活过度 :
h增大; 减少 x i _i i= 1 的权值 w i _i i ; x i _i i= 0 的权值 w i _i i 不变。
3. 多层感知器
利用误差修正学习 , 我们实现了自动获取参数 w i _i i ,h,但是 感知器训练只能解决线性可分问题,不能解决线性不可分问题。 (线性不可分问题: 无法用一条直线将两个类别分开的问题)针对这点,多层感知器 和 BP 被提出来,用以解决线性不可分问题。
3.1 初期多层感知器:
初期多层感知器就是由多层结构的感知器递阶组成的输入值向前传播的网络,也被称为前馈网络/ 正向传播网络。
多层感知器常由三层结构组成: 1. 输入层; 2. 中间层; 3. 输出层。

中间层的输出z1…zm也是由x1…xn和wi11…winm组成输出得到u1…um, 然后通过激活函数y=f(u)得到的。
但是由于误差修正只能针对单层修正,不能跨层修正,所以初期多层感知器的只能对中间层和输入层的参数进行修正,不能对其它层进行误差修正学习
↓
针对此点,BP( Back propagation 误差反向传播算法 ) 被提出,用以改进初期的多层感知器不能对其它层进行误差修正学习的缺点。
3.2 BP下的多层感知器:
-
最小二乘误差函数 :
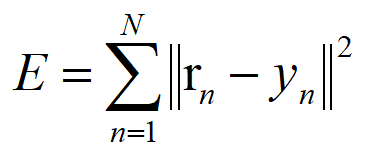
以下讲解中,我的误差函数使用最小二乘误差函数*1/2 用以简化后续运算:
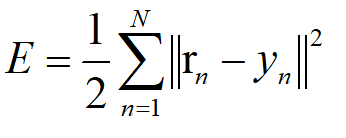
-
而激活函数使用 可导的sigmoid函数 :(详细介绍见: Sigmoid函数总结
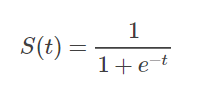
sigmoid函数将整个一维空间映射到[0,1]或[-1,1]。他的导数就是:
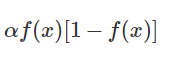
-
权重的调整使用 梯度下降法(gradient descent method) :
我们的目标是通过梯度确定调整值,不断调整权重连接值,使得误差E达到最小,或者接近于0!!!
梯度是微积分中一个很重要的概念:
在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率。
在多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指出了函数在给定点的上升最快的方向
梯度的方向是函数在给定点上升最快的方向,那么梯度的反方向就是函数在给定点下降最快的方向!
刚才提到 “我们的目标是通过梯度确定调整值,不断调整权重连接值,使得误差E达到最小”
↓
可以看出有2个重要点: a. 因变量误差E需要达到最小 ; b. 自变量是权重连接值 w
i
_i
i。
↓
-
那怎么才来来调整呢? 显然我们用误差对权值求导将是一个很好的选择,导数的意义是提供了一个方向,沿着这个方向改变权值,将会让总的误差变大,更形象的叫它为梯度。
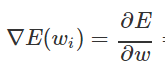
既然梯度确定了E最陡峭的上升的方向,也就是越顺着梯度的方向,误差增加的越来越快,逆着梯度的方向,误差降低的越来越快,那么梯度下降的训练法则是:

( η \eta η 是上文提到的 学习率 ;
在误差函数的导数 ▽ \bigtriangledown ▽E( w i _i i)前面加负号,是因为保证是顺着梯度下降的方向调节权重连接值的!)
-
那怎么调整才能保证调整的快,而找到最小点呢?这个就可以提到 深入浅出–梯度下降法及其实现里下山的例子了。
假设这样一个场景:一个人被困在山上,需要从山上下来(i.e. 找到山的最低点,也就是山谷)。 但此时山上的浓雾很大,导致可视度很低。因此,下山的路径就无法确定,他必须利用自己周围的信息去找到下山的路径。 这个时候,他就可以利用梯度下降算法来帮助自己下山。 具体来说就是,以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着山的高度下降的地方走, (同理,如果我们的目标是上山,也就是爬到山顶,那么此时应该是朝着最陡峭的方向往上走。) 然后每走一段距离,都反复采用同一个方法寻找这个位置最陡峭的地方,最后就能成功的抵达山谷。

看到这里 你也许会问,那要是只找到了局部最优值,但是却没有真正到山谷怎么办?因为目前的梯度下降法好像不能保证寻找到全局最优啊。即如果误差曲面上有多个局极小值,那么不能保证这个过程会找到全局最小值。
如图:

感知器与梯度下降 里提到的梯度下降的一种变体:随机梯度下降 可以很好地解决这个问题:

其实也还有其他的办法,具体可以看 Andrew Ng 关于 Machine Learning 的视频,我当时看了记完笔记,有些印象觉得讲得很好,至今也忘了。。所以暂时不讲把。。未来深入了可能会开一篇文专门细讲。。。
下面以单输出多层感知器和多输出多层感知器为例,介绍BP(误差反向传播)怎么自动调节连接权重值得:
(手写的字,不要介意字太丑哦。。。)
A. BP下 单输出 多层感知器的权重调节示例:


B. BP下 多输出 多层感知器的权重调节示例:
















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









