







人工神经网络
神经元的数学模型
MP模型
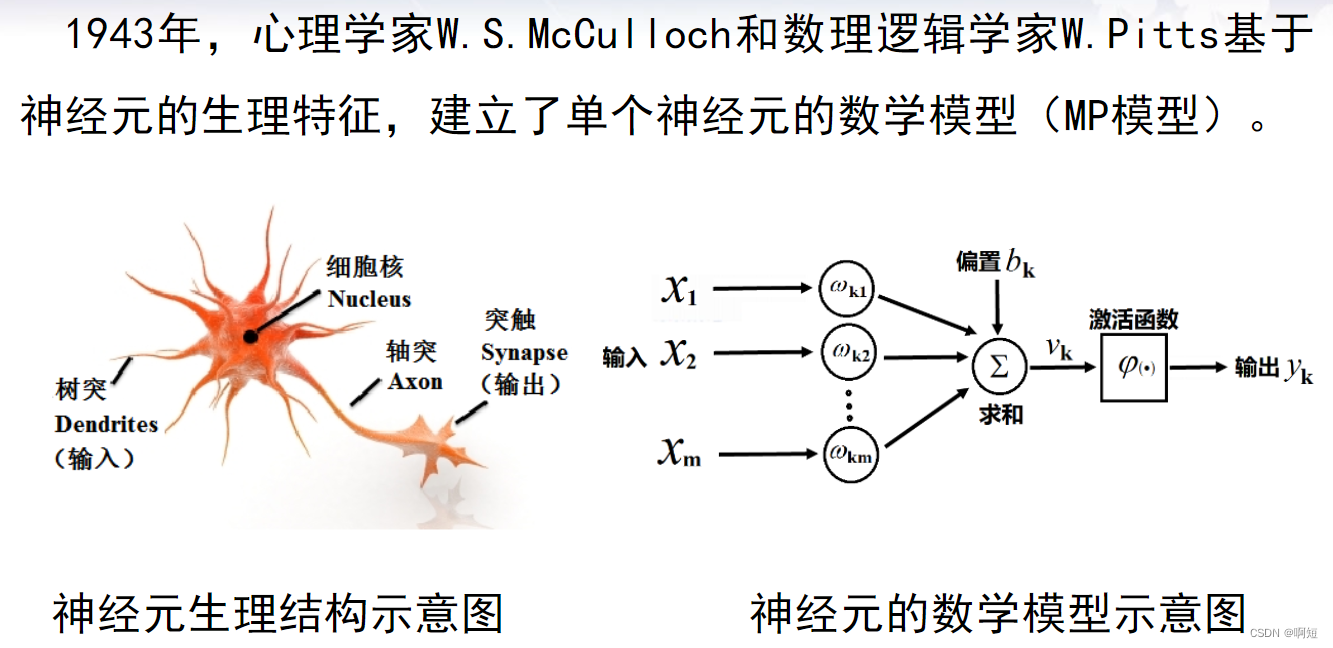
- 将外部刺激模拟为一串数字x1、x2…xm的输入;
- 将每个树突对输入刺激加工过程模拟为:以某个权重对输入进行加权;(图中的w1、w2…w3)
- 将细胞核对输入的处理模拟为:一个带有偏置的求和过程;
- 最后的输出是用激活函数对求和的结果进行非线性变换而得出;
所以输入对输出的表示关系为:
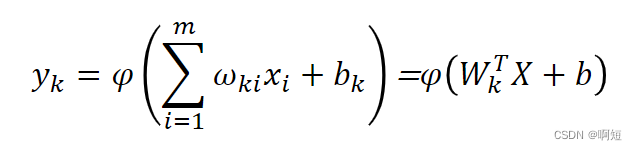
我们也可以以向量的形式表示:
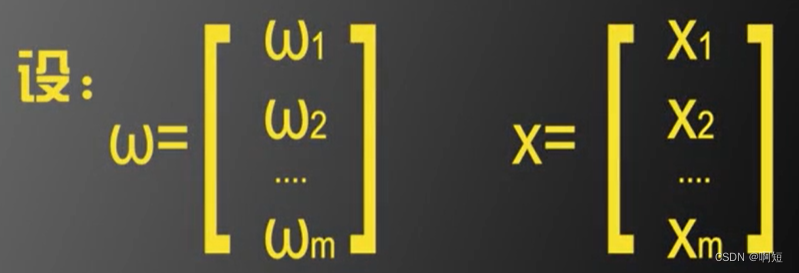
公式转化为:
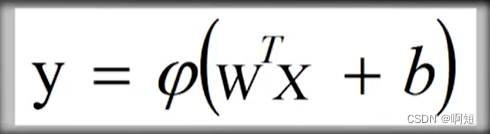
最开始这套模型不成功的原因就在于太过简单,而且我们不能确定人类神经元是否可以用这种,加权相乘之后求偏置的形式表示。
数学解释

以上是泰勒展开
地位
现在人工神经网络和深度学习的基本单元依然是MP模型。
MP模型是应用最广泛的。我们离神经很遥远,所以用简单的模拟未尝不是一件好事。
感知器算法
MP模型:
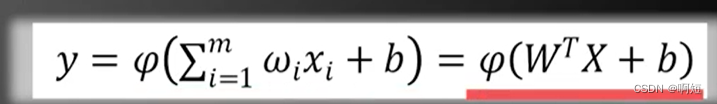 通过输入输出对,用机器学习算法,自动的获得权重w和偏置b。由此提出感知器算法。
通过输入输出对,用机器学习算法,自动的获得权重w和偏置b。由此提出感知器算法。
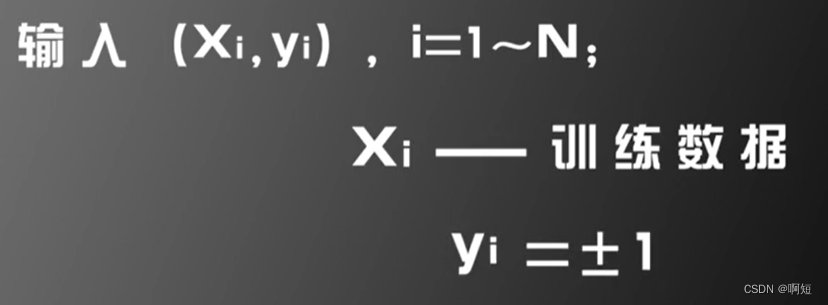


当且仅当在训练数据集线性可分的情况下,才能找到w和b满足使所有的n个训练样本都达到平衡。
感知器算法给出了不同于支持向量机的,找到w和b的算法

2中都是不平衡的条件所以需要重新计算w和b,直到找到合适的w和b。

||x||^2 >= 0 这样使得x朝着平衡状态更近了一点。
y = 1同理

只要训练数据线性可分,感知器算法就一定可以停下来



感知器算法的收敛定理:

收敛几何展示
如图分类线性可分
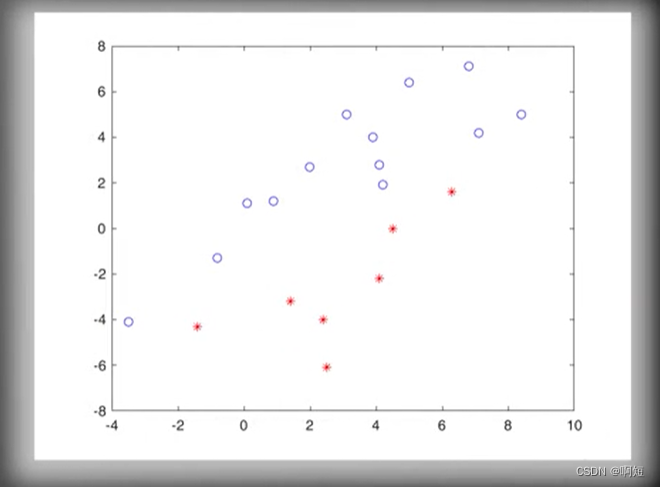
最初的w(分法)随机刷新
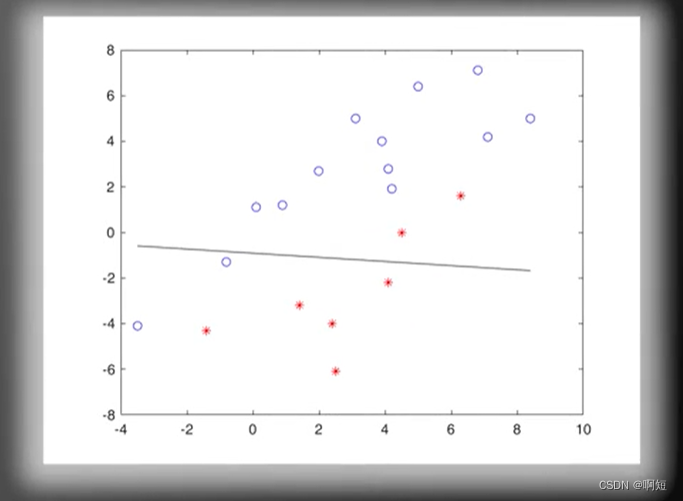
调用感知器算法不断的更新直线的方程
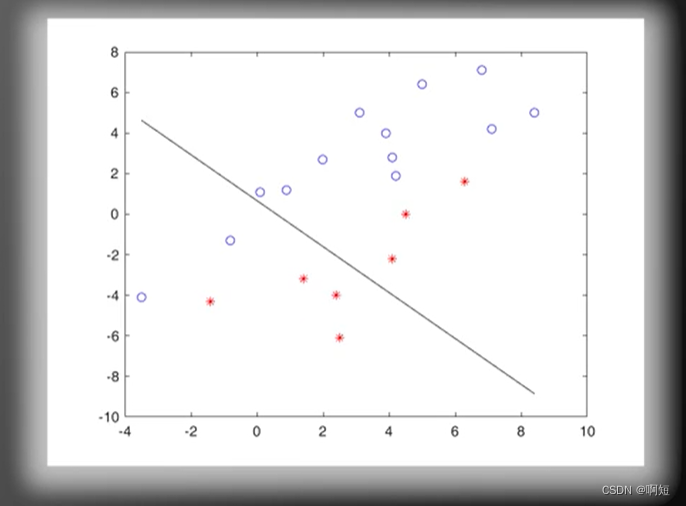
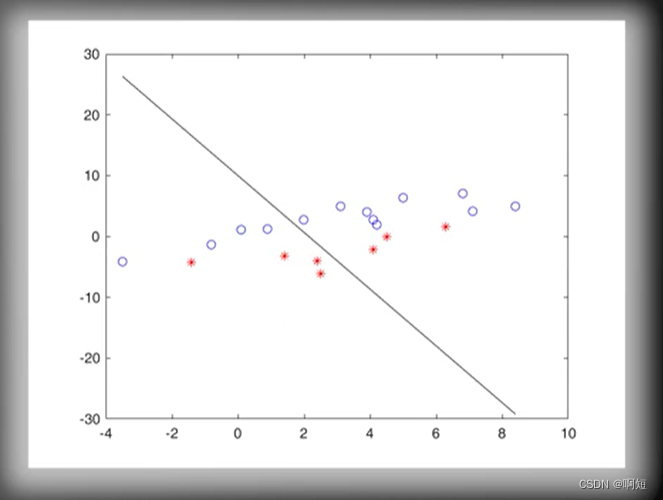
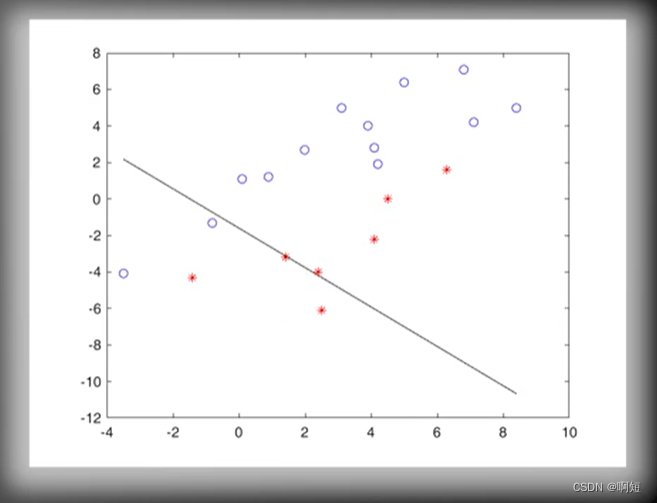

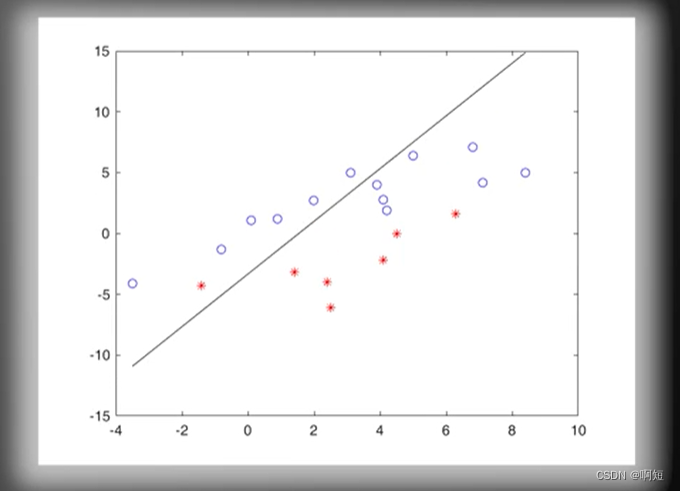
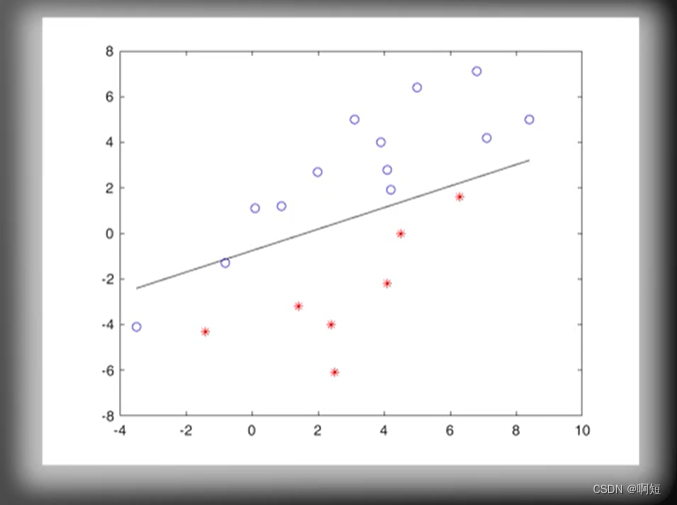
虽然我们看到他是随机的没有规律的不断的在更新,但是感知器算法保证了线性的是一定可分的,一定会收敛得出结构的。
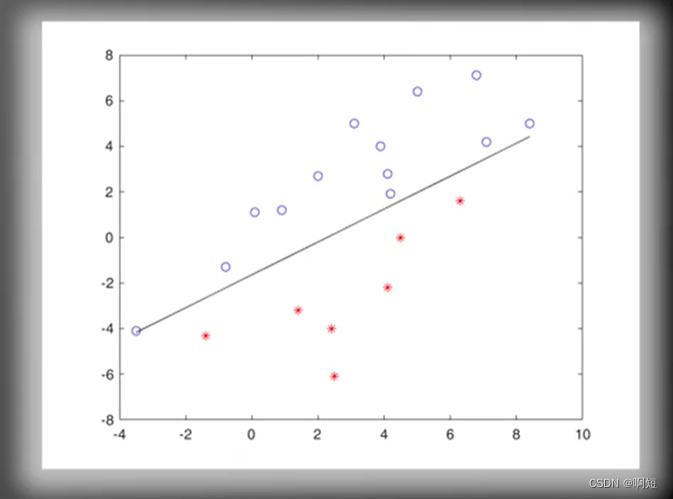
最后多轮迭代后收敛成了这个样子(成功分开):
感知器算法意义
感知器算法,在训练数据线性可分的条件下,寻找分类的超平面,类似于支持向量机。
但是支持向量机是寻找最大化间隔的超平面,感知器算法是相对随意的找一个可以分类的超平面,所以往往支持向量机画出的超平面要比感知器算法画出的好一点。
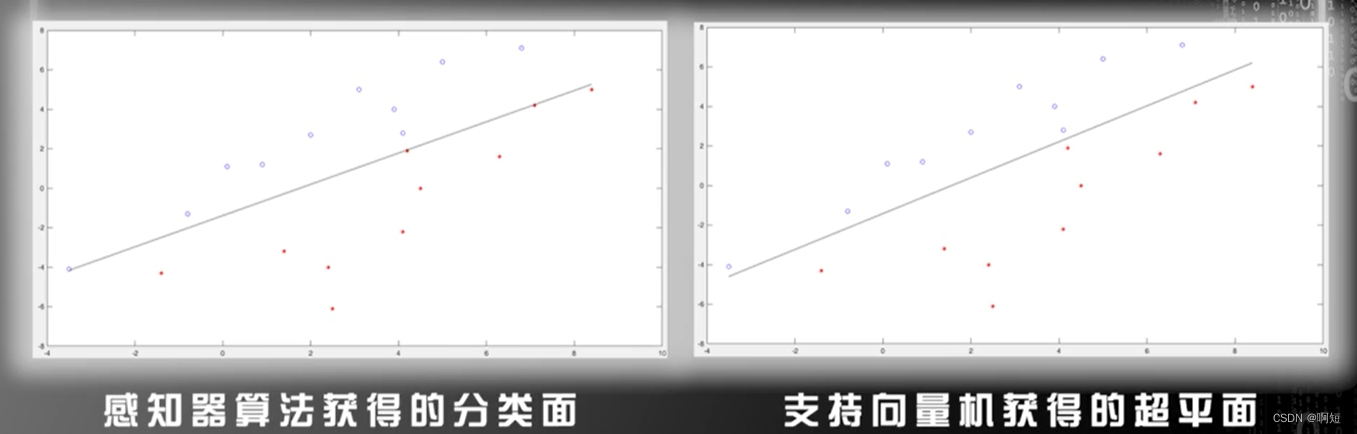
目前已经不再使用感知器算法了,但是感知器算法模型是所有模型的先驱。
感知器算法消耗的计算机资源较少。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









