




目录
在之前的文章《一条SQL使用order by,引发IO问题》中,针对Using Filesort我们探讨了MySQL的排序策略与优化方向,今天,我们将介绍另一种会导致慢SQL的常见情况,即“Using temporary”,本文我们将带领大家详细探讨此类问题的原因及如何优化。
一、场景案例
在介绍具体内容之前,我们先来看个模拟的案例:
device表(id,device_name,device_type,time)有10万条数据,device_type有50种,device_name有5万种,这两个字段均没有索引。
分别按照device_name与device_type进行group by,两类SQL施加相同的并发压力进行观察。
select device_name,count(*) as c from device group by device_name limit 0,5;select device_type,count(*) as c from device group by device_type limit 0,5;
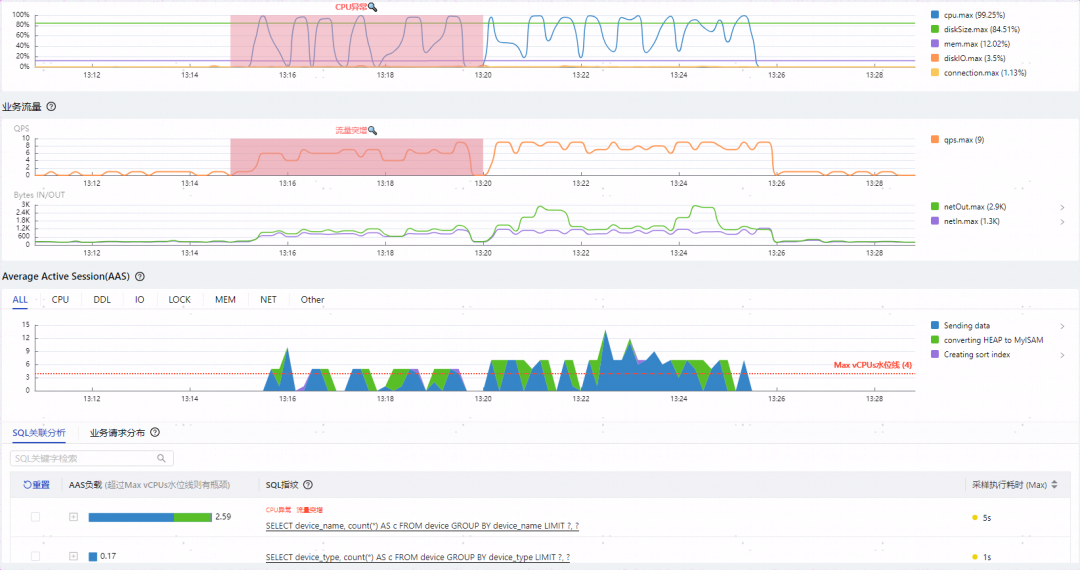

如上图所示可以观察到几个特点:
-
两类SQL总QPS虽然只有10,但是却将CPU打满,影响到整个实例的性能
-
group by device_name执行时间达到了5秒,性能堪忧
-
CPU打满的根因归到了group by device_name
-
group by device_name比group by device_type多出了绿色代表的converting HEAP to MySIAM事件(5.7开始是converting HEAP to ondisk),而且所占比重不小
-
两者执行计划相同,都是全表扫描,扫描行数相同,EXTRA字段都是Using temporary; Using filesort
看到这里有些新手同学可能会有些疑问:
-
扫描行数一样,执行计划一样,为什么group by device_name要慢很多?
-
多出的converting HEAP to MySIAM是什么意思?
-
Using temporary代表什么含义?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 276
276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









