







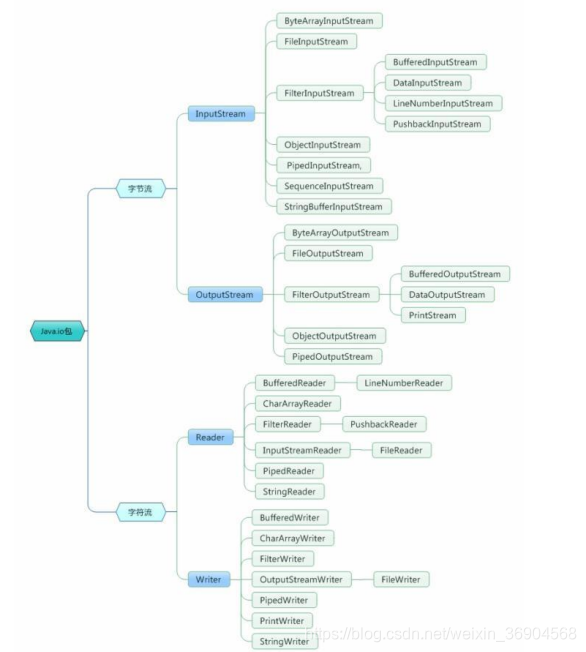
一:Java的IO
1. IO模型
(1)阻塞 IO 模型
最传统的一种 IO 模型,即在读写数据过程中会发生阻塞现象。当用户线程发出 IO 请求之后,内核会去查看数据是否就绪:
- 如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用户线程交出 CPU。
- 当数据就绪之后,内核会将数据拷贝到用户线程,并返回结果给用户线程,用户线程才解除 block 状态。
特点:线程执行的效率较低
data = socket.read(); //如果数据没有就绪,就会一直阻塞在 read 方法。
(2)非阻塞 IO 模型
当用户线程发起一个 read 操作后,并不需要等待,而是马上就得到了一个结果:
- 如果结果是error 时,它就知道数据还没有准备好,于是它可以再次发送 read 操作
- 一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。
特点:在非阻塞 IO 模型中,用户线程需要不断地询问内核数据是否就绪,也就说非阻塞 IO不会交出 CPU,而会一直占用 CPU,导致 CPU 占用率非常高
while(true){
data = socket.read();
if(data!= error){
//处理数据
break;
}
}
(3)多路复用 IO 模型
多路复用 IO 模型是目前使用得比较多的模型,Java NIO 实际上就是多路复用 IO。
在多路复用 IO模型中,会有一个线程不断去轮询多个 socket 的状态,只有当 socket 真正有读写事件时,才真正调用实际的 IO 读写操作。
特点:
- 只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有在真正有socket 读写事件进行时,才会使用 IO 资源,所以它大大减少了资源占用,适合连接数比较多的情况
- 在非阻塞 IO 中,不断地询问 socket 状态时通过用户线程去进行的,而在多路复用 IO 中,轮询每个 socket 状态是内核在进行的,这个效率要比用户线程要高的多
- 由于是通过轮询的方式来检测是否有事件到达,并且对到达的事件逐一进行响应,一旦事件响应体很大,那么就会导致后续的事件迟迟得不到处理,并且会影响新的事件轮询。
selector.select() //查询每个通道是否有到达事件,如果没有事件,则用户线程一直阻塞在那里
(4)信号驱动 IO 模型
- 用户线程发起一个IO请求后,会给对应的socket注册一个信号函数,然后继续执行
- 内核数据就绪时,发送一个信号给用户线程
- 用户线程接收到信号之后,在信号函数中调用IO读写操作来进行实际的IO请求操作
(5)异步 IO 模型
异步 IO 模型才是最理想的 IO 模型,用户线程完全不需要实际的整个 IO 操作是如何进行的,只需要先发起一个请求,当接收内核返回的成功信号时表示 IO 操作已经完成,可以直接去使用数据了。(需要操作系统的底层支持,在 Java 7 中,提供了 Asynchronous IO)
- 用户线程发起 read 操作之后,立刻就可以开始去做其它的事
- 从内核的角度
- 内核接收到一个 asynchronous read 之后,它会立刻返回,说明 read 请求已经成功发起了,不会对用户线程产生任何 block
- 内核等待数据准备完成
- 将数据拷贝到用户线程
- 内核会给用户线程发送一个信号,告诉它 read 操作完成了
特点:IO 操作的两个阶段都不会阻塞用户线程,这两个阶段都是由内核自动完成,然后发送一个信号告知用户线程操作已完成,用户线程中不需要再次调用 IO 函数进行具体的读写。
- 在信号驱动模型中,当用户线程接收到信号表示数据已经就绪,然后需要用户线程调用 IO 函数进行实际的读写操作
- 在异步 IO 模型中,收到信号表示 IO 操作已经完成,不需要再在用户线程中调用 IO 函数进行实际的读写操作。
2. NIO
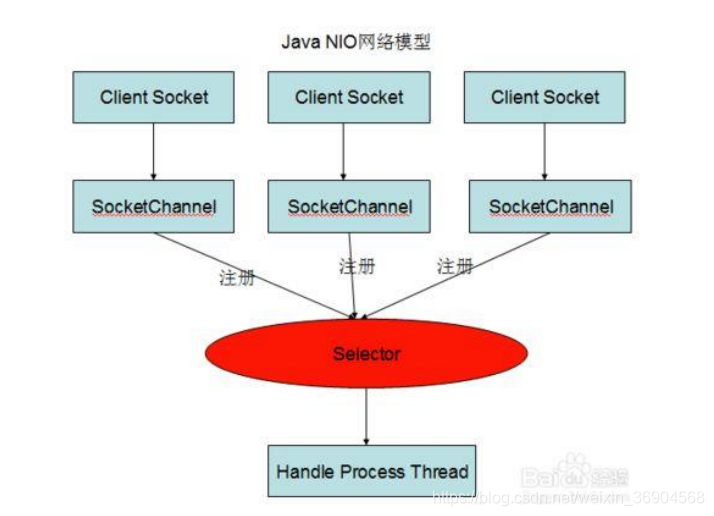
NIO 主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector(选择器)
传统 IO 基于字节流和字符流进行操作,而 NIO 基于 Channel 和 Buffer进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道。
NIO 和传统 IO 之间第一个最大的区别是,IO 是面向流的,NIO 是面向缓冲区的。
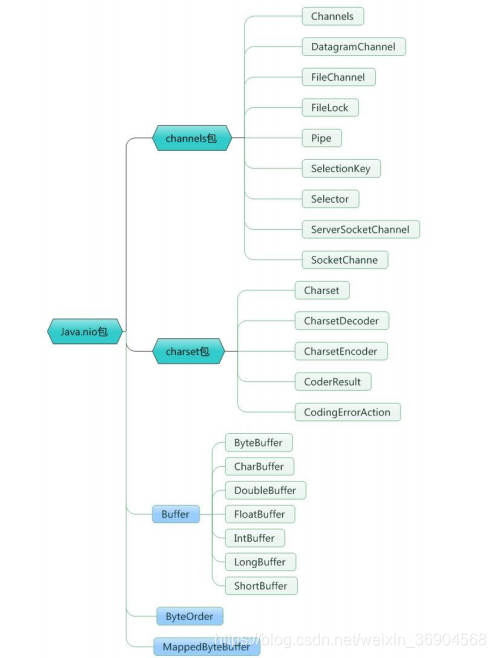
(1)NIO与传统IO
缓冲区
Java IO 面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。它不能前后移动流中的数据,如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。
NIO 的缓冲导向方法不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所
有需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
非阻塞
传统IO 的各种流是阻塞的。当一个线程调用 read() 或 write()时,该线程被阻塞,直到有一些数据被读取或数据完全写入,该线程在此期间不能再干任何事情了。
NIO 的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,该线程可以继续做其他的事情,而不是保持线程阻塞。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞 IO 的空闲时间用于在其它通道上执行 IO 操作,所以一个单独的线程现在可以管理多个输入和输出通道
(2)NIO的基本组成
Channel
Stream 是单向的,如:InputStream, OutputStream,而 Channel 是双向的,既可以用来进行读操作,又可以用来进行写操作。
NIO 中的 Channel 的主要实现有:
- FileChannel(文件 IO)
- DatagramChannel(UDP IO)
- SocketChannel(TCP的Client IO)
- ServerSocketChannel(TCP的Server IO)
Buffer
Buffer缓冲区,实际上是一个容器,是一个连续数组。Channel 提供从文件、网络读取数据的渠道,但是读取或写入的数据都必须经由 Buffer。
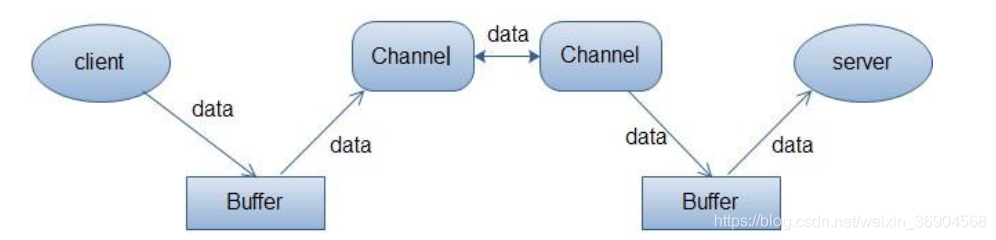
常用的 Buffer 的子类有:
- ByteBuffer
- IntBuffer
- CharBuffer
- LongBuffer
- DoubleBuffer
- FloatBuffer
- ShortBuffer
Selector
Selector 类是 NIO 的核心类,Selector 能够检测多个注册的通道上是否有事件发生,如果有事件发生,便获取事件然后针对每个事件进行相应的响应处理。
这样一来,只用一个线程就可以管理多个通道,也就是管理多个连接。这样使得只有在连接真正有读写事件发生时,才会调用函数来进行读写,大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程,并且避免了多线程之间的上下文切换导致的开销。
二:Java的集合
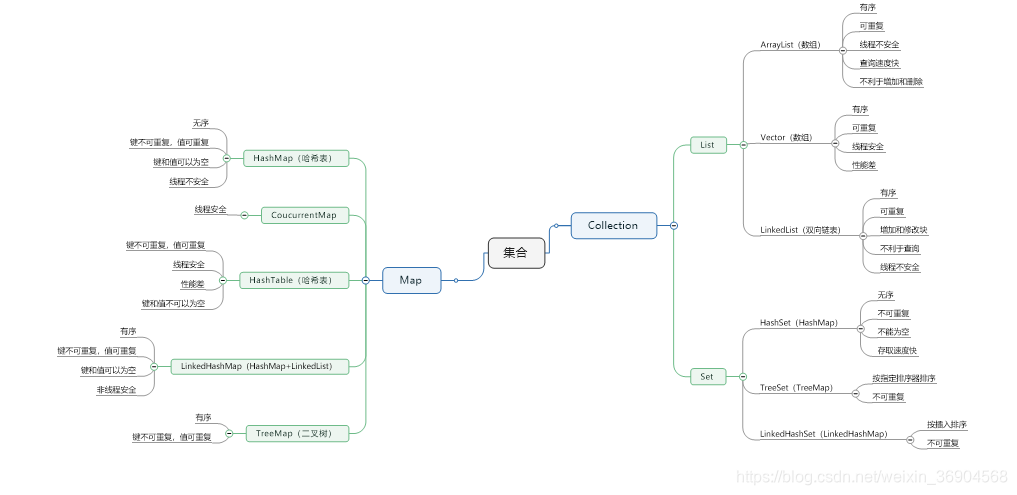
集合类存放于 Java.util 包中,主要有 3 种集合:set(集)、list(Queue)和 map(映射)
- Collection:Collection 是集合 List、Set、Queue 的最基本的接口。
- Iterator:迭代器,可以通过迭代器遍历集合中的数据
- Map:是映射表的基础接口
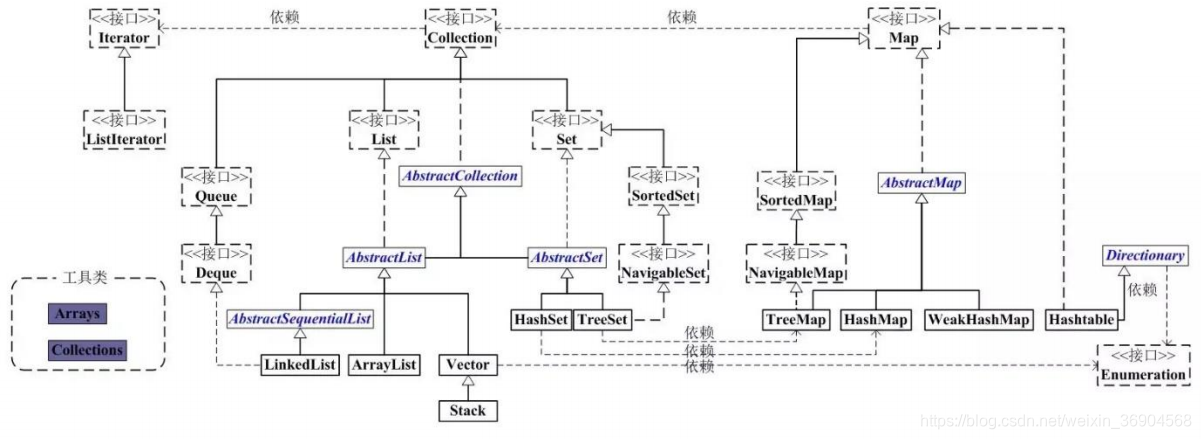
1. list
List 是有序的 Collection。Java List 一共三个实现类:分别是 ArrayList、Vector 和 LinkedList。
(1)ArrayList(数组)
ArrayList 是最常用的 List 实现类,内部是通过数组实现的
- 允许对元素进行快速随机访问。
- 当数组大小不满足时需要增加存储能力,就要将已经有数组的数据复制到新的存储空间中。当从 ArrayList 的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高
- 它适合随机查找和遍历,不适合插入和删除。
扩容:ArayList 本质上是一个数组。初始容量为 10。
- 插入元素的时候可能扩容,删除元素时不会缩小容量。
- 扩容时 Araylist 增长原来的 0.5 倍
- Araylist 没有设置增长空间的方法。
ArrayList和Array
- Array 可以包含基本类型和对象类型,ArrayList 只能包含对象类
- 容量上:Array 大小固定,ArrayList 的大小是动态变化的
- 操作上:ArrayList 提供更多的方法和特性,如:adAl(),removeAl(),iterator()等。
- 使用基本数据类型或者知道数据元素数量的时候可以考虑 Array 。ArrayList 处理固定数量的基本类型数据类型时会自动装箱来减少编码工作量,但是相对较慢。
(2)Vector(数组实现、线程同步)
Vector 与 ArrayList 一样,也是通过数组实现的。
- 支持线程的同步,即某一时刻只有一个线程能够写 Vector,避免多线程同时写而引起的不一致性
- 实现同步需要很高的花费,比访问 ArrayList 慢。
扩容:Vector 是一个动态数组,初始容量为 10。
- 扩容时 Vector 增长原来的 1 倍
- Vector 可以设置增长的空间大小
Vector和ArrayList
相同点:
- 两者都是基于索引的,都是基于数组的。
- 两者都维护插入顺序,我们可以根据插入顺序来获取元素。
- ArayList 和 Vector 的迭代器实现都是 fail-fast 的。
- ArayList 和 Vector 两者允许 nul 值,也可以使用索引值对元素进行随机访问。
不同点:
- Vector 是同步,线程安全,而 ArayList 非同步,线程不安全。对于 ArayList,如果
迭代时改变列表,应该使用 CopyOnWriteArayList。 - 但是,ArayList 比 Vector 要快,它因为有同步,不会过载。
- 在使用上ArrayList 更加通用,因为 Colections 工具类容易获取同步列表和只读列表
- ArrayList和Vector的扩容方式不同
(3)LinkedList(链表)
LinkedList 是用链表结构存储数据的
- 很适合数据的动态插入和删除
- 随机访问和遍历速度比较慢
- 提供了 List 接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
ArrayList和LinkedList
- ArayList 是基于索引的数据接口,它的底层是数组。它可以 O(1)时间复杂度对元素进行随机访问。
- LinkedList 是以元素列表的形式存储它的数据,每一个元素都和它的前一个和后一个元素链接在一起,在这种情况下,查找某个元素的时间复杂度是 O(n)。
- 相对于 ArayList,LinkedList 的插入,添加,删除操作速度更快,因为当元素被添加到集合任意位置的时候,不需要像数组那样重新计算大小或者是更新索引。
- LinkedList 比 ArayList 更占内存,因为 LinkedList 为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。
(4)CopyOnWriteArayList
参考博客:线程安全的CopyOnWriteArrayList介绍
CopyOnWriteArrayList使用了一种叫写时复制的方法,当有新元素添加到CopyOnWriteArrayList时,先从原有的数组中拷贝一份出来,然后在新的数组做写操作,写完之后,再将原来的数组引用指向到新数组。
CopyOnWriteArrayList的整个add操作都是在锁的保护下进行的,避免在多线程并发add的时候,复制出多个副本出来,导致最终的数组数据不是我们期望的。而读操作是可以不用加锁的
public boolean add(E e) {
//1、先加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
//2、拷贝数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
//3、将元素加入到新数组中
newElements[len] = e;
//4、将array引用指向到新数组
setArray(newElements);
return true;
} finally {
//5、解锁
lock.unlock();
}
}
如果有线程并发的写,则通过锁来控制,如果有线程并发的读,则分几种情况:
- 如果写操作未完成,那么直接读取原数组的数据;
- 如果写操作完成,但是引用还未指向新数组,那么也是读取原数组数据;
- 如果写操作完成,并且引用已经指向了新的数组,那么直接从新数组中读取数据。
特点
- 由于写操作需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致young gc或者full gc
- 不能用于实时读的场景,像拷贝数组、新增元素都需要时间,所以调用一个set操作后,读取到数据可能还是旧的,虽然CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求
- CopyOnWriteArrayList 适合读多写少的场景
- 读写分离,读和写分开
- 使用另外开辟空间的思路,来解决并发冲突
2. Set
Set 注重独一无二的性质,用于存储无序(存入和取出的顺序不一定相同)元素,值不能重
复。
对象的相等性本质是对象 hashCode 值(依据对象的内存地址计算出的序号)判断的,如果想要让两个不同的对象视为相等的,就必须覆盖 Object 的 hashCode 方法和 equals 方法。
(1)HashSet(Hash 表)
哈希表(实际上是一个 HashMap 实例)存放的是哈希值,HashSet 存储元素的顺序并不是按照存入时的顺序, 而是按照哈希值来存的,所以取数据也是按照哈希值取得。
元素的哈希值是通过元素的hashcode 方法来获取的
- HashSet 首先判断两个元素的哈希值
- 哈希值不同:元素存储在不同的哈希值位置
- 哈希值相同
- equals 为 false:在同样的哈希值下顺延,也就是哈希一样的元素存一列。(可以认为哈希值相同的元素放在一个哈希桶中)
- equls 为 true :同一个元素(当 key 值相同时,只是进行更新 value,并不会增加,所以 set 中的元素不会进行改变)
(2)TreeSet(二叉树)
使用二叉树的原理,每增加一个对象都会按照指定的顺序排序,将对象插入的二叉树指定的位置。
Integer 和 String 对象都可以进行默认的 TreeSet 排序,而自定义类的对象是不可以的,自己定义的类必须实现 Comparable 接口,并且覆写相应的 compareTo()函数,才可以正常使用。
(3)LinkHashSet(HashSet+LinkedHashMap)
对于 LinkedHashSet 而言,它继承于 HashSet、又基于 LinkedHashMap 来实现的。
LinkedHashSet 底层使用 LinkedHashMap 来保存所有元素,其所有的方法操作上又与 HashSet 相同
因此 LinkedHashSet 的实现上非常简单,只提供了四个构造方法,并通过传递一个标识参数,调用父类的构造器,底层构造一个 LinkedHashMap 来实现,在相关操作上与父类 HashSet 的操作相同,直接调用父类 HashSet 的方法即可。
(4)CopyOnWriteArraySet
底层实现是利用数组,它的上层实现是CopyOnWriteArrayList。CopyOnWriteArraySet是利用CopyOnWriteArrayList来实现的,因为CopyOnWriteArrayList是线程安全的,所以CopyOnWriteArraySet操作也是线程安全的。
public boolean add(E e) {
//这个al就是CopyOnWriteArrayList也就是说CopyOnWriteArraySet内部是用CopyOnWriteArrayList来实现的
return al.addIfAbsent(e);
}
//首先检查原来的数组里面有没有要添加的元素,如果有的话就不要再添加了
//如果没有的话,创建一个新的数组,复制之前数组元素并且添加新的元素
public boolean addIfAbsent(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// Copy while checking if already present.
// This wins in the most common case where it is not present
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = new Object[len + 1];
for (int i = 0; i < len; ++i) {
if (eq(e, elements[i]))
return false; // exit, throwing away copy
else
newElements[i] = elements[i];
}
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
(5)ConcurrentSkipListSet
ConcurrentSkipListSet是一个有序的、支持并发的集合,是通过ConcurrentSkipListMap实现的
3. Map
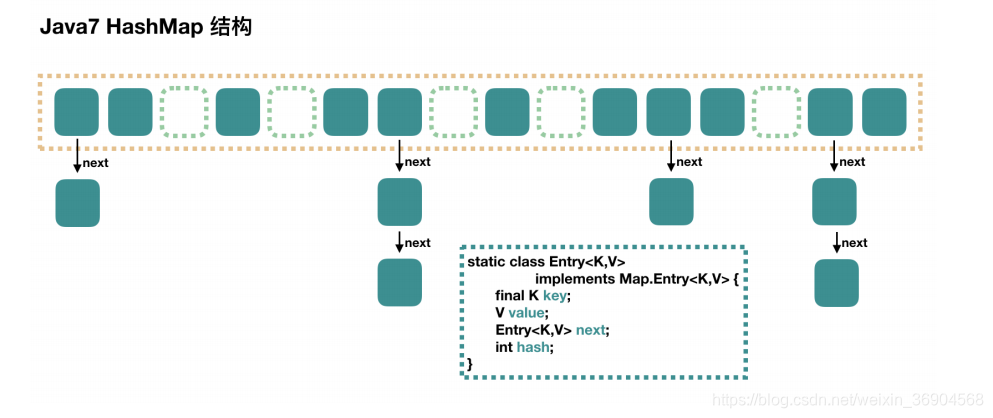
(1)HashMap(数组+链表+红黑树)
1:基本概念
Hashmap实际上是一个数组和链表的结合体,数组的每个元素存储链表的头结点。Java使用链地址法解决哈希碰撞
HashMap 根据键的 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。如果需要存储自定义类,则需要自己实现hashcode方法和equals方法。
HashMap 最多只允许一条记录的键为 null,允许多条记录的值为 null。如果键为可变对象,对象中的属性改变时必须保证哈希值不会变
在Java7中,如果发生哈希碰撞,需要顺着链表一个个比较下去才能找到我们需要的数据,时间复杂度取决于链表的长度,为 O(n):
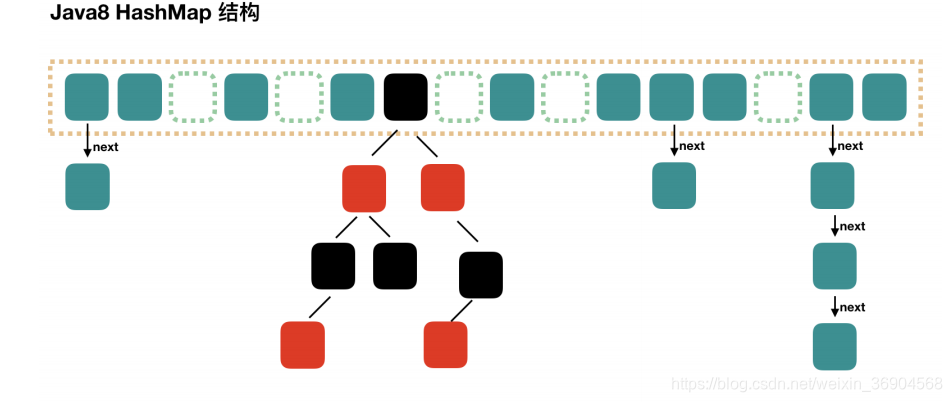
在 Java8 中,当链表中的元素超过了 8 个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN):
2:基本操作
哈希
参考知乎:JDK 源码中 HashMap 的 hash 方法原理是什么?
//Java 7
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
//对key的hashCode进行扰动计算,防止不同hashCode的高位不同但低位相同导致的hash冲突
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
//Java 8中的散列值优化函数
static final int hash(Object key) {
int h;
//自己的高半区和低半区做异或,混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
static int indexFor(int h, int length) {
//首先算得key得hashcode值h,然后跟数组的长度-1做一次“与”运算(&)
//数组长度为2的整数次幂时可以减少碰撞次数,作为低位掩码,使其均匀分布
//与”操作的结果就是散列值的高位全部归零,只保留低位值
//相当于对数组的长度做一次“模”操作,但是与操作比模操作更有效率
return h & (length-1);
}
扩容
参考博客:深入理解HashMap(及hash函数的真正巧妙之处)
当hashmap中的元素个数超过数组大小* loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16 * 0.75=12的时候,就把数组的大小扩展为2 * 16=32,即扩大一倍,然后重新计算每个元素在数组中的位置。因此,预设元素的个数能够有效的提高hashmap的性能。
在1.8中,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”
获取

添加
数组中存储的是最后插入的元素

3:问题
hash 碰撞和扩容导致线程不安全,要想实现线程安全,那么需要调用 colections 类的静态方法synchronizeMap()

HashMap 扩容的时候可能会形成环形链表,造成死循环
3:HashSet和HashMap

(2)HashTable(线程安全)
1:基本概念
Hashtable 是遗留类,很多映射的常用功能与 HashMap 类似,不同的是它承自Dictionary 类,并且是线程安全的,任一时间只有一个线程能写 Hashtable。
Hashtable 是一个 Entry[]数组类型,而 Entry 实际上就是一个单向链表。哈希表的
"key-value 键值对"都是存储在 Entry 数组中的。
Hashtable 中的 key 和 value 是不允许为空的
它的同步使用锁来保证的,并且所有同步操作使用的是同一个锁对象。这样若有n个线程同时在get时,这n个线程要串行的等待来获取锁。
2:基本操作
参考博客:【Java集合源码剖析】Hashtable源码剖析
添加
- 首先计算 key 的 hash 值
- 然后通过 hash 值确定在 table 数组中的索引位置,最后将 value 值替换或者插入新的元素
- 如果容器的数量达到阈值,就会进行扩充。
// 将“key-value”添加到Hashtable中
public synchronized V put(K key, V value) {
// Hashtable中不能插入value为null的元素!!!
if (value == null) {
throw new NullPointerException();
}
// 若“Hashtable中已存在键为key的键值对”,
// 则用“新的value”替换“旧的value”
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
// 若“Hashtable中不存在键为key的键值对”,
// 将“修改统计数”+1
modCount++;
// 若“Hashtable实际容量” > “阈值”(阈值=总的容量 * 加载因子)
// 则调整Hashtable的大小
if (count >= threshold) {
rehash();
tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}
//将新的key-value对插入到tab[index]处(即链表的头结点)
Entry<K,V> e = tab[index];
tab[index] = new Entry<K,V>(hash, key, value, e);
count++;
return null;
}
获取
// 返回key对应的value,没有的话返回null
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
// 计算索引值,
int index = (hash & 0x7FFFFFFF) % tab.length;
// 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
移除
// 删除Hashtable中键为key的元素
public synchronized V remove(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
//从table[index]链表中找出要删除的节点,并删除该节点。
//因为是单链表,因此要保留带删节点的前一个节点,才能有效地删除节点
for (Entry<K,V> e = tab[index], prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
扩容
默认初始容量为 12,加载因子为 0.75:即当元素个数超过容量长度的 0.75 倍时,进行扩容
3:HashTable和HashMap

(3)ConcurrentHashMap
1:基本概念
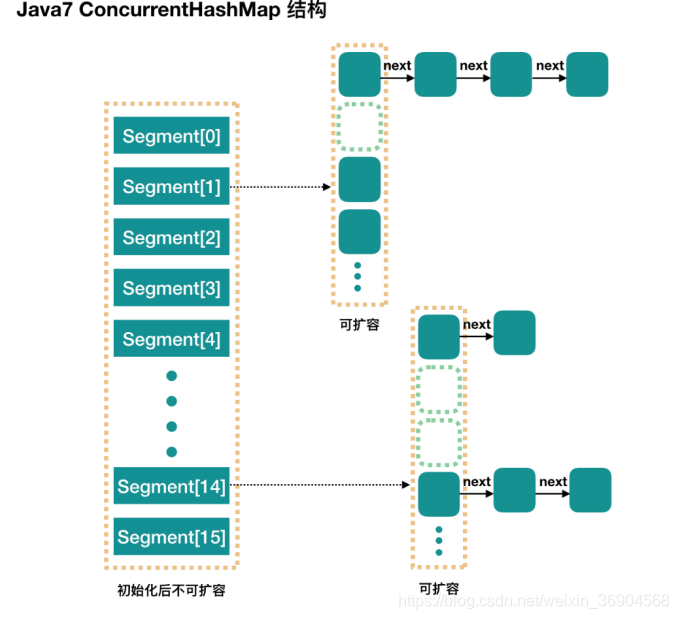
ConcurrentHashMap 是一个 Segment 数组,用concurrencyLevel指定并发数N即数组长度,默认是 16。一旦初始化以后,它是不可以扩容的。最多可以同时支持N个线程并发写,只要它们的操作分别分布在不同的 Segment 上
static final class Segment<K,V> extends ReentrantLock implements Serializable
Segment 代表”部分“或”一段“的意思,所以很多地方都会将其描述为分段锁,Segment 通过继承ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
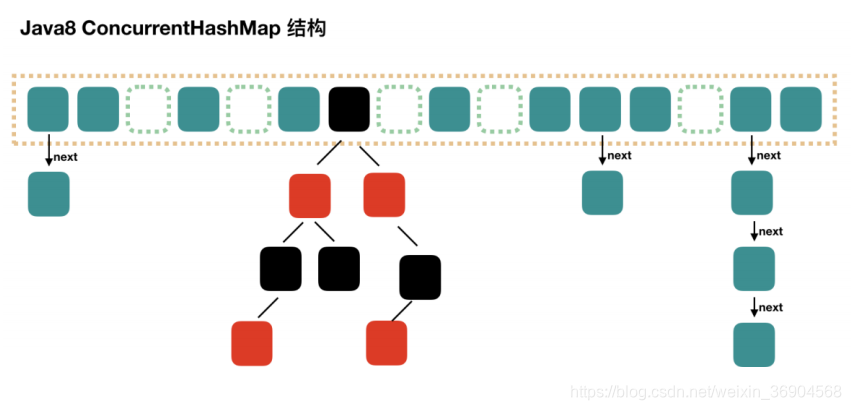
1.8 抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发
安全性。
当 table[i]下面的链表长度大于 8时就转化为红黑树结构。
2:基本操作
参考博客:ConcurrentHashMap源码剖析
参考博客:ConcurrentHashMap实现原理
获取
public V get(Object key) {
int hash = hash(key); // throws NullPointerException if key null
return segmentFor(hash).get(key, hash);
}
//没有使用锁来同步,只是判断获取的entry的value是否为null,为null时才使用加锁的方式再次去获
V get(Object key, int hash) {
if (count != 0) { // count变量表示segment中存在entry的个数
HashEntry<K,V> e = getFirst(hash); //获取到要该key所在segment中的索引地址,
while (e != null) {
//如果该地址有相同的hash对象,顺着链表一直比较下去找到该entry
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
//另一个线程修改了一个entry:value是用volitale修饰的,可以保证读取时获取到的是修改后的值
//另一个线程新增了一个entry:需要判断对象是否完整,否则使用锁的方式再次get一次。
//另一个线程删除了一个entry: 即使我们返回的时候,对象被其他线程删除了,也不会对我们新的链表造成影响
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
在1.8中:
- 根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
- 如果是红黑树那就按照树的方式获取值。
- 不满足那就按照链表的方式遍历获取值。
添加
public V put(K key, V value) {
if (value == null) //ConcurrentHashMap 中不允许用 null 作为映射值
throw new NullPointerException();
int hash = hash(key.hashCode()); //计算键对应的散列码
//根据散列码找到对应的 Segment
return segmentFor(hash).put(key, hash, value, false);
}
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock(); //当前的segment加锁
try {
int c = count;
if (c++ > threshold) //如果超过再散列的阈值
rehash(); //执行再散列,table 数组的长度将扩充一倍
HashEntry<K,V>[] tab = table;
//把散列码值与 table 数组的长度减 1 的值相“与”
//得到该散列码对应的 table 数组的下标值
int index = hash & (tab.length - 1);
//找到散列码对应的具体的那个桶
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) { //如果键/值对以经存在
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value; // 设置 value 值
}
else { //键/值对不存在
oldValue = null;
++modCount; //添加新节点到链表中,modCont 要加 1
// 创建新节点,并添加到链表的头部
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; //写 count 变量
}
return oldValue;
} finally {
unlock(); //解锁
}
}
在1.8中:
- 首先根据 key 计算出 hashcode ,判断是否需要进行初始化。
- f 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
- 如果当前位置的 hashcode = MOVED = -1,则需要进行扩容。
- 如果都不满足,则利用 synchronized 锁写入数据(分为链表写入和红黑树写入)
- 如果数量大于 TREIFY_THRESHOLD 则要转换为红黑树。
移除
V remove(Object key, int hash, Object value) {
lock(); //加锁
try{
int c = count - 1;
HashEntry<K,V>[] tab = table;
//根据散列码找到 table 的下标值
int index = hash & (tab.length - 1);
//找到散列码对应的那个桶
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while(e != null&& (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if(e != null) {
V v = e.value;
if(value == null|| value.equals(v)) { //找到要删除的节点
oldValue = v;
++modCount;
//所有处于待删除节点之后的节点原样保留在链表中
//所有处于待删除节点之前的节点被克隆到新链表中
HashEntry<K,V> newFirst = e.next;// 待删节点的后继结点
for(HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash,newFirst, p.value);
//把桶链接到新的头结点
//新的头结点是原链表中,删除节点之前的那个节点
tab[index] = newFirst;
count = c; //写 count 变量
}
}
return oldValue;
} finally{
unlock(); //解锁
}
}
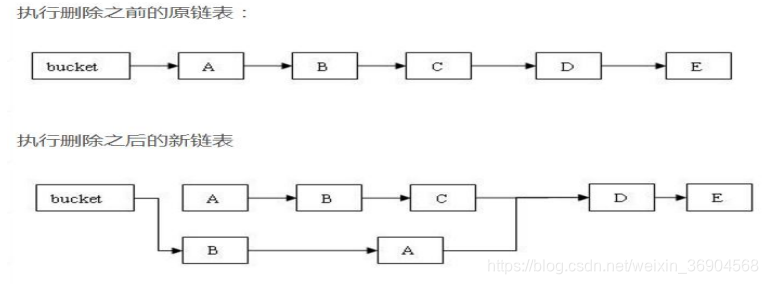
3:HashMap和CurrentHashMap

4:HashTable和CurrentHashMap

(4)LinkHashMap(记录插入顺序)
LinkedHashMap 是 HashMap 的一个子类,保存了记录的插入顺序,在用 Iterator 遍历
LinkedHashMap 时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
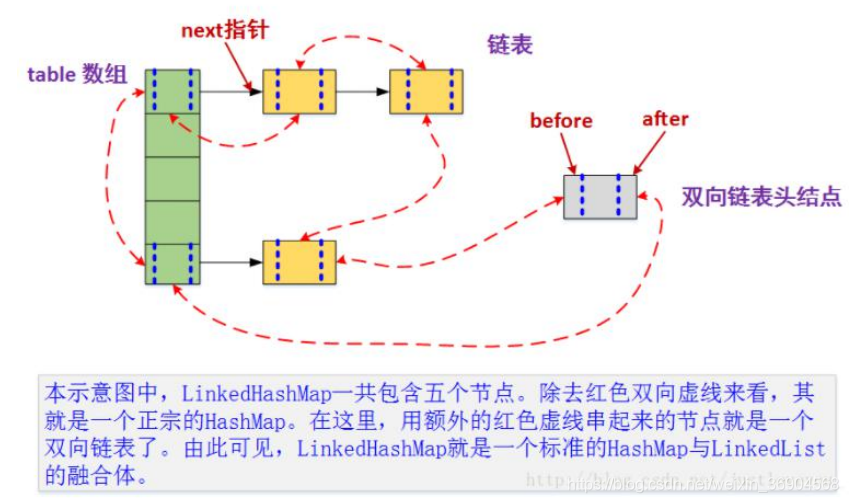
LinkedHashMap和HashMap

(5)TreeMap(可排序)
1:基本概念
TreeMap多继承了一个接口NavigableMap,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用 Iterator 遍历 TreeMap 时,得到的记录是排过序的。TreeMap是基于红黑树实现的
在使用 TreeMap 时,key 必须实现 Comparable 接口或者在构造 TreeMap 传入自定义的Comparator,否则会在运行时抛出 java.lang.ClassCastException 类型的异常。
出于性能原因,TreeMap是非同步的。如果在多线程环境则需要手动同步,或者通过Collections.synchronizedSortedMap()包装
2:基本操作
参考博客:给jdk写注释系列之jdk1.6容器(7)-TreeMap源码解析
查找
public V get(Object key) {
Entry<K,V> p = getEntry(key);
return (p==null ? null : p. value);
}
final Entry<K,V> getEntry(Object key) {
if (comparator != null)
// 如果比较器为空,只是用key作为比较器查询
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
// 取得root节点
Entry<K,V> p = root;
// 从root节点开始查找,根据比较器判断是在左子树还是右子树
while (p != null) {
int cmp = k.compareTo(p.key );
if (cmp < 0)
p = p. left;
else if (cmp > 0)
p = p. right;
else
return p;
}
return null;
}
final Entry<K,V> getEntryUsingComparator(Object key) {
K k = (K) key;
Comparator<? super K> cpr = comparator ;
if (cpr != null) {
Entry<K,V> p = root;
while (p != null) {
int cmp = cpr.compare(k, p.key );
if (cmp < 0)
p = p. left;
else if (cmp > 0)
p = p. right;
else
return p;
}
}
return null;
}
添加
public V put(K key, V value) {
// 根节点
Entry<K,V> t = root;
// 如果根节点为空,则直接创建一个根节点,返回
if (t == null) {
root = new Entry<K,V>(key, value, null);
size = 1;
modCount++;
return null;
}
// 记录比较结果
int cmp;
Entry<K,V> parent;
// 当前使用的比较器
Comparator<? super K> cpr = comparator ;
// 如果比较器不为空,就是用指定的比较器来维护TreeMap的元素顺序
if (cpr != null) {
// do while循环,查找key要插入的位置(也就是新节点的父节点是谁)
do {
// 记录上次循环的节点t
parent = t;
// 比较当前节点的key和新插入的key的大小
cmp = cpr.compare(key, t. key);
// 新插入的key小的话,则以当前节点的左孩子节点为新的比较节点
if (cmp < 0)
t = t. left;
// 新插入的key大的话,则以当前节点的右孩子节点为新的比较节点
else if (cmp > 0)
t = t. right;
else
// 如果当前节点的key和新插入的key想的的话,则覆盖map的value,返回
return t.setValue(value);
// 只有当t为null,也就是没有要比较节点的时候,代表已经找到新节点要插入的位置
} while (t != null);
}
else {
// 如果比较器为空,则使用key作为比较器进行比较
// 这里要求key不能为空,并且必须实现Comparable接口
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
// 和上面一样,查找新节点要插入的位置
do {
parent = t;
cmp = k.compareTo(t. key);
if (cmp < 0)
t = t. left;
else if (cmp > 0)
t = t. right;
else
return t.setValue(value);
} while (t != null);
}
// 找到新节点的父节点后,创建节点对象
Entry<K,V> e = new Entry<K,V>(key, value, parent);
// 如果新节点key的值小于父节点key的值,则插在父节点的左侧
if (cmp < 0)
parent. left = e;
// 如果新节点key的值大于父节点key的值,则插在父节点的右侧
else
parent. right = e;
// 插入新的节点后,为了保持红黑树平衡,对红黑树进行调整
fixAfterInsertion(e);
// map元素个数+1
size++;
modCount++;
return null;
}
删除
public V remove(Object key) {
// 根据key查找到对应的节点对象
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
// 记录key对应的value,供返回使用
V oldValue = p. value;
// 删除节点
deleteEntry(p);
return oldValue;
}
private void deleteEntry(Entry<K,V> p) {
modCount++;
// map容器的元素个数减一
size--;
// If strictly internal, copy successor's element to p and then make p
// point to successor.
// 如果被删除的节点p的左孩子和右孩子都不为空,则查找其替代节点-----------这里表示要删除的节点有两个孩子(3)
if (p.left != null && p. right != null) {
// 查找p的替代节点
Entry<K,V> s = successor (p);
p. key = s.key ;
p. value = s.value ;
// 将p指向替代节点,※※※※※※从此之后的p不再是原先要删除的节点p,而是替代者p(就是图解里面讲到的M) ※※※※※※
p = s;
} // p has 2 children
// Start fixup at replacement node, if it exists.
// replacement为替代节点p的继承者(就是图解里面讲到的N),p的左孩子存在则用p的左孩子替代,否则用p的右孩子
Entry<K,V> replacement = (p. left != null ? p.left : p. right);
if (replacement != null) { // 如果上面的if有两个孩子不通过--------------这里表示要删除的节点只有一个孩子(2)
// Link replacement to parent
// 将p的父节点拷贝给替代节点
replacement. parent = p.parent ;
// 如果替代节点p的父节点为空,也就是p为跟节点,则将replacement设置为根节点
if (p.parent == null)
root = replacement;
// 如果替代节点p是其父节点的左孩子,则将replacement设置为其父节点的左孩子
else if (p == p.parent. left)
p. parent.left = replacement;
// 如果替代节点p是其父节点的左孩子,则将replacement设置为其父节点的右孩子
else
p. parent.right = replacement;
// Null out links so they are OK to use by fixAfterDeletion.
// 将替代节点p的left、right、parent的指针都指向空,即解除前后引用关系(相当于将p从树种摘除),使得gc可以回收
p. left = p.right = p.parent = null;
// Fix replacement
// 如果替代节点p的颜色是黑色,则需要调整红黑树以保持其平衡
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) { // return if we are the only node.
// 如果要替代节点p没有父节点,代表p为根节点,直接删除即可
root = null;
} else { // No children. Use self as phantom replacement and unlink.
// 判断进入这里说明替代节点p没有孩子--------------这里表示没有孩子则直接删除(1)
// 如果p的颜色是黑色,则调整红黑树
if (p.color == BLACK)
fixAfterDeletion(p);
// 下面删除替代节点p
if (p.parent != null) {
// 解除p的父节点对p的引用
if (p == p.parent .left)
p. parent.left = null;
else if (p == p.parent. right)
p. parent.right = null;
// 解除p对p父节点的引用
p. parent = null;
}
}
}
3:TreeMap和TreeSet
- 最主要的区别就是TreeSet和TreeMap分别实现Set和Map接口
- TreeSet只存储一个对象,而TreeMap存储两个对象Key和Value,仅仅key对象有序
- TreeSet中不能有重复对象,而TreeMap中可以存在
(6)ConcurentSkipListMap
参考博客:跳表(SkipList)及ConcurrentSkipListMap源码解析
ConcurrentSkipListMap提供了一种线程安全的并发访问的排序映射表。内部是SkipList(跳表)结构实现,在理论上能够O(log(n))时间内完成查找、插入、删除操作。
SkipList
传统意义的单链表是一个线性结构,向有序的链表中插入一个节点需要O(n)的时间,查找操作需要O(n)的时间。
如果使用跳表,每一个结点不单单只包含指向下一个结点的指针,可能包含很多个指向后续结点的指针,这样就可以跳过一些不必要的结点,从而加快查找、删除等操作。对于一个链表内每一个结点包含多少个指向后续元素的指针,后续节点个数是通过一个随机函数生成器得到,这样子就构成了一个跳跃表。
这是一种通过“空间来换取时间”的一个算法,通过在每个节点中增加了向前的指针,从而提升查找的效率。
跳跃表使用概率均衡技术而不是使用强制性均衡技术,因此,对于插入和删除结点比传统上的平衡树算法更为简洁高效
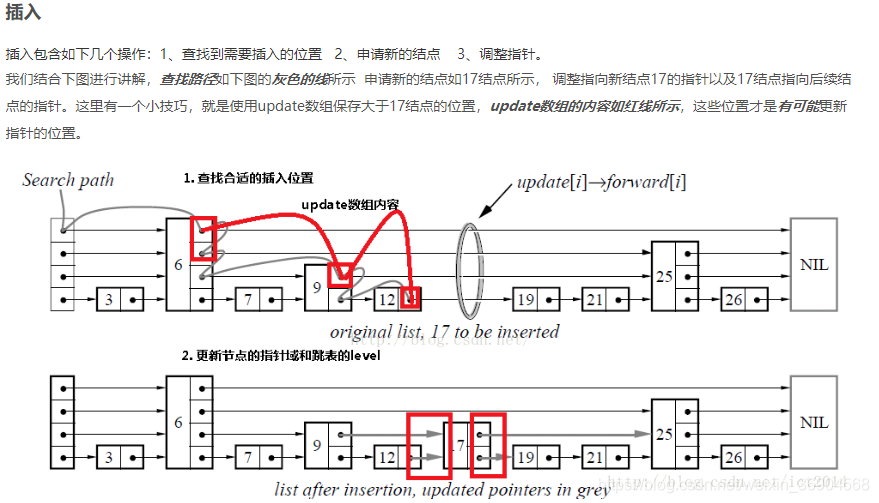
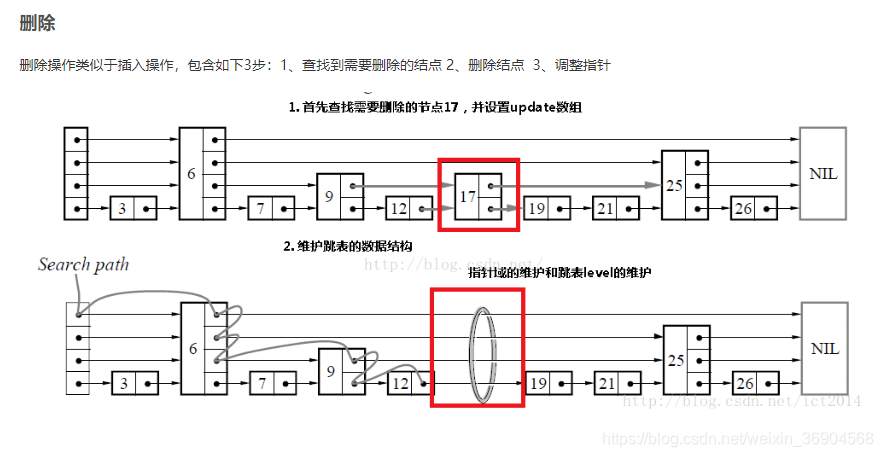
存储结构
- 最底层的数据节点按照关键字升序排列。
- 包含多级索引,每个级别的索引节点按照其关联数据节点的关键字升序排列。
- 高级别索引是其低级别索引的子集。
- 如果关键字key在级别level=i的索引中出现,则级别level<=i的所有索引中都包含key。
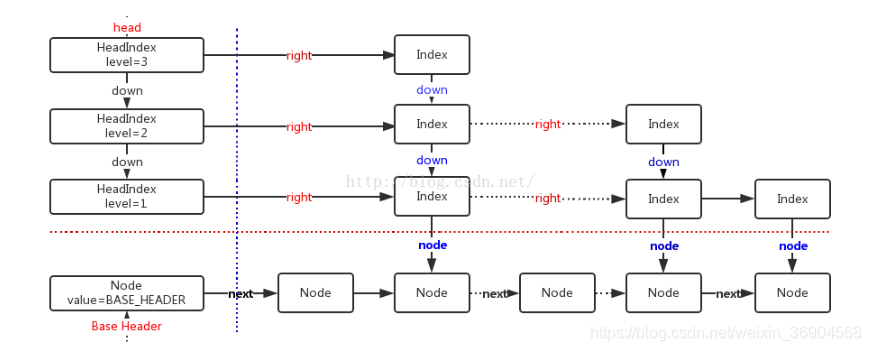
操作
查找
public V get(Object key) {
return doGet(key);
}
private V doGet(Object okey) {
Comparable<? super K> key = comparable(okey);
// 这里采用循环的方式来查找数据节点,防止返回刚好被删除的数据节点
for (;;) {
Node<K,V> n = findNode(key);//根据key查找数据节点
if (n == null)
return null;
Object v = n.value;
if (v != null)
return (V)v;
}
}
private Node<K,V> findNode(Comparable<? super K> key) {
for (;;) {
Node<K,V> b = findPredecessor(key);//根据key查找前驱数据节点
Node<K,V> n = b.next;
for (;;) {
if (n == null)
return null;
Node<K,V> f = n.next;
//b的后继节点两次读取不一致,重试
if (n != b.next)
break;
Object v = n.value;
//数据节点的值为null,表示该数据节点标记为已删除,移除该数据节点并重试。
if (v == null) {
n.helpDelete(b, f);
break;
}
//b节点被标记为删除,重试
if (v == n || b.value == null)
break;
int c = key.compareTo(n.key);
if (c == 0) //找到返回
return n;
if (c < 0) //给定key小于当前的值,不存在
return null;
b = n; //否则继续查找
n = f;
}
}
}
插入
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
return doPut(key, value, false);
}
private V doPut(K kkey, V value, boolean onlyIfAbsent) {
Comparable<? super K> key = comparable(kkey);
for (;;) {
Node<K,V> b = findPredecessor(key);//查找前驱数据节点
Node<K,V> n = b.next;
for (;;) {
if (n != null) {
Node<K,V> f = n.next;
//b的后继两次读取不一致,重试
if (n != b.next)
break;
Object v = n.value;
//数据节点的值为null,表示该数据节点标记为已删除,移除该数据节点并重试。
if (v == null) {
n.helpDelete(b, f);
break;
}
//b节点被标记为已删除,重试
if (v == n || b.value == null) // b is deleted
break;
int c = key.compareTo(n.key);
if (c > 0) {//给定key大于当前可以,继续寻找合适的插入点
b = n;
n = f;
continue;
}
if (c == 0) {//找到
if (onlyIfAbsent || n.casValue(v, value))
return (V)v;
else
break; // restart if lost race to replace value
}
// else c < 0; fall through
}
//没有找到,新建数据节点
Node<K,V> z = new Node<K,V>(kkey, value, n);
if (!b.casNext(n, z))
break; // restart if lost race to append to b
int level = randomLevel();//随机的索引级别
if (level > 0)
insertIndex(z, level);
return null;
}
}
}
4. Colections.sort
通过泛型实现对所有类型的排序,对于基本类型,按照字符表或数字大小排序;对于自定义类,通过实现Comparable接口并重写compareTo方法或者Comparator比较器排序
Colections.sort(aray, new Compartor<xd>() {
@Overide
public int compare(xd o1, xd o2) {
if(o1.a > o2.a)
return 1;
else if(o1.a < o2.a)
return -1;
return 0;
}
});
内部调用的是Arrays.sort()方法
- Arrays.sort(Object obj):使用归并排序
- Arrays.sort(int i):使用快速排序法
- 源码的优化:对于短数组,使用插入排序
5. hash算法

6. 迭代器 Iterator Enumeration
(1)Iterator 和 ListIerator 的区别是什么?
- Iterator 可用来遍历 Set 和 List 集合,但是 ListIerator 只能用来遍历 List。
- Iterator 对集合只能是前向遍历,ListIerator 既可以前向也可以后向。
- ListIerator 实现了 Iterator 接口,并包含其他的功能,比如:增加元素,替
换元素,获取前一个和后一个元素的索引等。
(2)Enumeration 接口和 Iterator 接口的区别有哪些?
- Enumeration 速度是 Iterator 的 2 倍,同时占用更少的内存。
- Iterator 远比 Enumeration 安全,因为其他线程不能够修改正在被iterator 遍历的集合里面的对象。同时,Iterator 允许调用者删除底层集合里面的元素,这对 Enumeration 来说是不可能的。
(3)快速失败(fail-fast)和安全失败(fail-safe)
快速失败(fail-fast)
在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增
加、删除、修改),则会抛出 Concurent Modifcation Exception。
原理:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变 modCount 的值。每当迭代器使
用 hashNext()/next()遍历下一个元素之前,都会检测 modCount 变量是否为expectdmod
Count 值,是的话就返回遍历;否则抛出异常,终止遍历。
注意:这里异常的抛出条件是检测到 modCount!=expectdmodCount 这个条件。如
果集合发生变化时修改 modCount 值刚好又设置为了 expectdmodCount 值,则异常不会
抛出。因此,不能依赖于这个异常是否抛出而进行并发操作的编程,这个异常只建议用于检测并发修改的 bug。
场景:jav.util 包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过
程中被修改)。
安全失败(fail—safe)
采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原
有集合内容,在拷贝的集合上进行遍历。
原理:由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改
并不能被迭代器检测到,所以不会触发 Concurent Modifcation Exception。
缺点:基于拷贝内容的优点是避免了 Concurent Modifcation Exception,但同样地,
迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。
场景:java.util.concurent 包下的容器都是安全失败,可以在多线程下并发使用,并发修改。
区别
- Iterator 的安全失败是基于对底层集合做拷贝,因此,它不受源集合上修改的影响 。
- java.util 包下面的所有的集合类都是快速失败的,而java.util.concurent 包下面的所有的类都是安全失败的。
- 快速失败的迭代器会抛出 ConcurentModifcationException 异常,而安全失败的迭代器永远不会抛出这样的异常。














 333
333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









