







【翻译】DFPE: Explaining Predictive Models for Disk Failure Prediction DFPE: 解释磁盘故障预测模型
·论文链接: https://ieeexplore.ieee.org/document/8890231
Abstract 摘要
磁盘故障预测的最新研究工作以复杂的模型实现了较高的检测率和较低的虚警率,但代价是难以解释。缺乏可解释性可能会掩盖模型中的偏差和过拟合问题,从而导致在实际应用中表现不佳。为了解决这一问题,我们提出了一种新的解释方法DFPE,该方法设计用于磁盘故障预测,以解释模型做出的故障预测并推断模型学习的预测规则。DFPE通过执行一系列替换测试以找出故障原因来解释故障预测,然后通过汇总故障预测的解释来解释模型。 在真实数据集上给出的用例表明,与当前的解释方法相比,DFPE可以更准确地解释故障预测和模型。因此,它有助于瞄准和处理隐藏的偏差和过拟合,从新的角度衡量功能的重要性,并实现智能的故障处理。
1.Introduction 介绍
数以万计的服务器聚集在数据中心中,以存储大量数据,并提供Internet、云计算、数据分析等服务。由于磁盘技术的成熟和高成本效益,大量的不同年龄的磁盘正在数据中心中使用。这就导致故障的频繁发生,尤其是磁盘故障。 对于未部署数据冗余方案(例如磁盘RAID,复制或擦除代码)的存储系统来说,磁盘故障会导致数据的丢失。而对于具有任何冗余方案的系统,磁盘故障会导致很大的开销来恢复丢失的数据,包括存储I/O、网络I/O和CPU突发(CPU burst)。
为了减少磁盘故障的影响,许多工作将重点放在磁盘故障预测上。磁盘故障预测解决方案会在即将发生磁盘故障时发出警报,因此存储系统有足够多的时间主动将数据和服务从高风险的磁盘中迁移出来。因此,它有助于维护数据和服务始终可用,并且减少了由于被动故障处理引起的I/O和CPU突发事件。
通常来说,预测模型在以下的情况下是可信赖的:1)对测试中大多数的现有案例做出正确预测。2)对做出预测的原因给出合理解释。关于磁盘故障预测的最新工作倾向于只关注前者而忽略后者。 他们建议在磁盘故障预测中采用复杂的模型,以改进检测率和虚警率。但是,他们是以可解释性为代价实现了改进,很难去理解为什么这些模型能够预测磁盘不久会发生故障。由于测试无法涵盖所有可能的情况,因此预测模型可能在测试中表现良好,但在测试中并未暴露出隐藏的偏差或过拟合问题,所以导致在实际应用中表现不佳。
偏差,也称为机器学习偏差,表示模型会产生系统性的偏见结果。例如,流行的Google News Word2Vec模型具有性别偏见,因为Google News数据集具有固有偏见。过拟合意味着模型会学习训练数据的噪声,并且过于精确地和训练数据对应。偏差和过拟合在预测模型的应用中会导致较低的预测精度。它们可能是由于对数据收集和处理的无意识监督造成的,很难去检测和处理。然而,如果对模型做出的预测给出解释,模型的高可解释性可以帮助检测偏差和过拟合。因此,提高磁盘故障预测中复杂模型的可解释性是十分重要的。
在本文中,我们提出了DFPE,一种磁盘故障预测解释方法,以提高复杂模型在磁盘故障预测上的可解释性。 DFPE通过提取相关特征来解释模型做出的故障预测,并通过汇总故障预测的解释和度量特征的重要性来推断模型学习的预测规则。此外,DFPE提供了更多的故障相关信息,以实现智能故障处理,从而可以针对不同故障情况采取不同的措施,而不是直接丢弃高风险磁盘。
总结起来,我们在本文中做出了以下贡献:
• 我们提出了一种新的解释方法,以提高当前复杂模型对磁盘故障预测的可解释性。据我们所知,它是第一个针对磁盘故障预测的可解释性问题的。
• 我们在一个实际数据集上提供了一个案例,以表明在磁盘故障预测的复杂模型中可能存在偏差,而我们的新方法有助于检测和处理隐藏的偏差。
• 我们证明了DFPE可以用于度量特征的重要性,并讨论了DFPE如何实现智能故障处理。
本文的其余部分将介绍方法的细节。第二节介绍了背景,存在的问题及相关工作。第三节介绍了我们方法的设计,第四节介绍了评估。第五节总结了论文并介绍了我们未来的工作。
2.BACKGROUND AND RELATED WORK 背景和相关工作
A.Notation list 注释列表
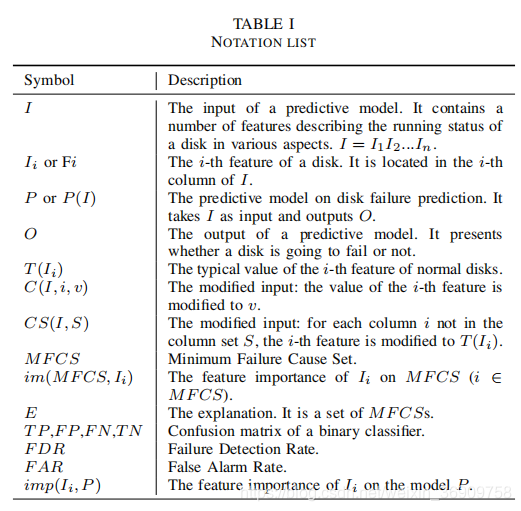
表 I 列出了本文中使用的符号。
B.Disk failure prediction 磁盘故障预测
磁盘故障预测是为了预测磁盘的未来状态:正常或故障。但是,它不仅仅是一个分类问题,还具有以下特征:
• 由于磁盘故障的情况比普通情况少得多,因此它是不平衡的分类问题。因此,预测磁盘故障的情况通常比正常预测少得多。
• 由于磁盘状态会随时间变化,因此这是一个时间序列分析问题。
• 这是一个多实例学习问题。对于发生故障的磁盘,其最终状态是已知的,但是磁盘变为故障时的确切更改点是未知的。
DFPE用于解释磁盘故障的预测和模型:1)DFPE通过专注于解释故障预测来解决上述第一个特征; 2)DFPE可以解释为时间序列构建的模型。 3)DFPE可以找出给定模型的变更点。
C.Abstraction for disk failure predictive models 磁盘故障预测模型简介
令I为预测模型的输入。I由许多特征组成:I = I1I2 … In,这些特征从各个方面描述了磁盘的运行指标。大部分有关磁盘故障预测的最新成果是基于SMART属性来建立预测模型的。SMART(自我监视,分析和报告技术的缩写)是一种监视系统,用于检测和报告各种存储驱动器可靠性的指标。它已很好地部署在硬盘驱动器(HDD)、固态驱动器(SSD)和eMMC驱动器中。例如,HDD的常见SMART属性包括SMART 5(重新分配扇区数)、SMART 7(寻错率)、SMART 189(高写入率)等等。此外,一些方法还考虑了系统级指标,例如文件系统错误、读取速率、写入速率、I/O队列大小、I/O等待时间和I/O利用率。由于特征值随时间变化,I可以是当前值,也可以是近一段时间内的值,也可以是从部署时间到现在的值。
令P为磁盘故障预测的预测模型。 P以I作为输入,并输出磁盘是否会发生故障:P:I→O。建立预测模型很复杂。为了解决建模问题,提出了许多算法、方法和工具,例如抽样、价值定标、学习、投票等。在本文中,我们将重点放在学习模型上。在磁盘故障预测中流行的学习模型包括SVM(支持向量机)、决策树、集成模型(例如随机森林、GBDT(梯度提升决策树) )、以及人工神经网络(例如MLP(多层感知器),RNN(递归神经网络)和LSTM(长期短期记忆))。
令O为预测模型的输出。它可以推断磁盘在不久的将来是否会发生故障。它可以是布尔值(故障或正常),浮点值(多接近故障)或整数值(不同紧急程度)。在本文中,O默认为布尔值,其他类型的O可以轻松转换为布尔值。
D.Explainability 可解释性
随着人工智能的快速发展,越来越多复杂的模型被提出来以提高精度。提出的模型通常具有成千上万的参数。对于人类来说是不可能理解每个参数的确切含义以及模型如何从输入中推断出结果的。换句话说,为了提高准确性而牺牲掉了可解释性。
但是,随着对安全性和可信度的要求越来越高,越来越多的研究工作致力于改善复杂模型的可解释性。可解释性要求模型不仅输出结果,而且还解释其为何推断结果以及所学的规则。 尽管了解复杂模型中所有参数的确切含义是不现实的,但是可解释性只要求模型定性地解释输入和输出之间的关系,或者量化输入的每个特征对输出的贡献。这些解释为模型提供了见解,因此可以决定输出和模型是否可信。强调可解释性的优点是:1&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 264
264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









