






GT信号与蒸馏目标之间的优化目标不一致是预测模拟失效的关键原因?为缓解该问题,本文提出一种简单且有效的蒸馏机制CrossKD,基于MSCOCO数据集,仅需预测模拟损失,CrossKD可以将GFL-ResNet50-1x的指标从40.2提升至43.7,超越了现有所有知识蒸馏方案。
arXiv:https://arxiv.org/abs/2306.11369
code:https://github.com/jbwang1997/CrossKD
作为一种有效的模型压缩技术,知识蒸馏在多个CV领域取得了突出的成绩。目前,在检测领域,特征模仿(Feature Imitation)方案往往具有比预测模拟(Prediction Mimicking)方案具有更高的性能。
在本文中,作者发现:GT信号与蒸馏目标之间的优化目标不一致是预测模拟失效的关键原因。为缓解该问题,本文提出一种简单且有效的蒸馏机制CrossKD,它直接将学生检测头的中间特征送入到老师检测头,所得跨头(Cross-Head)预测将被用于最小化与老师模型预测之间差异。这样的蒸馏机制缓解了学生检测头从GT与老师预测处接收截然相反的监督信息,进而极大的改善了学生模型的检测性能。基于MSCOCO数据集,仅需预测模拟损失,CrossKD可以将GFL-ResNet50-1x的指标从40.2提升至43.7,超越了现有所有知识蒸馏方案。
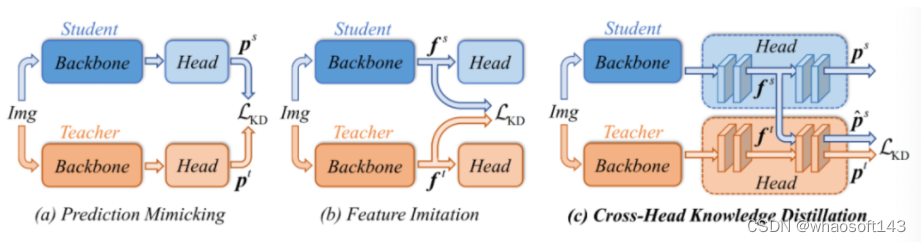
在证实介绍CrossKD之前,我们先简要介绍两种主要的KD范式,即特征模仿与预测模拟。

出发点

作者发现:预测模拟需要直面真值与蒸馏目标之间存在的冲突(参考上图),而这被已有蒸馏方法忽视了。当通过预测模拟方式进行训练时,学生模型的预测被迫同时最小化与两者之间的差异,进而影响了学生模型的性能。以上图为例,当老师模型输出不准确的类别概率时,这无疑会影响学生模型达成更高的性能。为缓解该问题,作者提出了直接将学生模型的中间特征融入到老师检测头中以构建跨头预测蒸馏。
本文方案
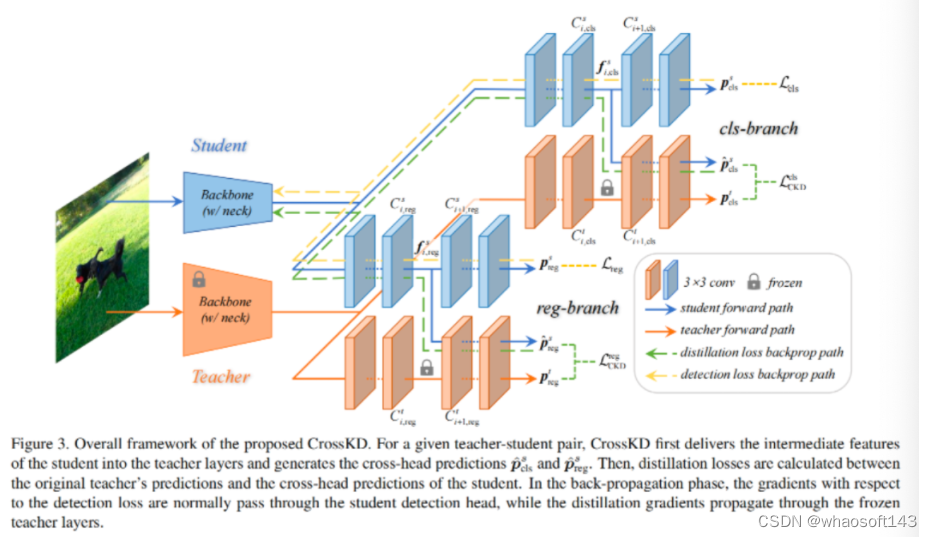
为缓解前述问题,本文构建了CrossKD方案,见上图。类似于已有预测模型,CrossKD直接对预测输出进行蒸馏;不同之处在于:CrossKD直接将学生模型的中间特征送入到老师模型的检测头以达成跨头预测蒸馏。

通过CrossKD,检测损失与蒸馏损失将独立作用到不同的分支。从上面图示可以看到:检测损失的梯度流经了完整的学生检测头,而蒸馏损失的梯度则经由冻结老师模型检测层后流入学生模型的隐层特征,这可以一定程度提升学生模型与老师模型的一致性。相比直接减少输出预测的差异,CrossKD使得学生模型检测头部分仅与检测损失相关,进而更好的朝着真值目标优化。
优化目标
整体优化损失函数定义为检测损失与蒸馏损失的加权组合,描述如下:
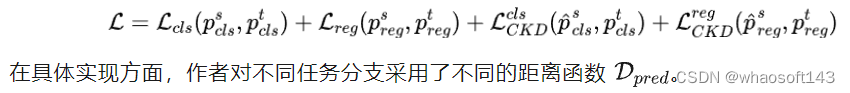
- 分类分支,将老师模型预测分类得分视作软标签,直接采用QFL约束学生模型与老师模型预测结果之间距离;
- 回归分支,对于类似RetinaNet、ATSS、FCOS这样直接回归头,直接采用GIoU;对于GFL这样的回归头,为有效蒸馏位置信息,作者采用了KL散度进行知识迁移。
关键实验结果
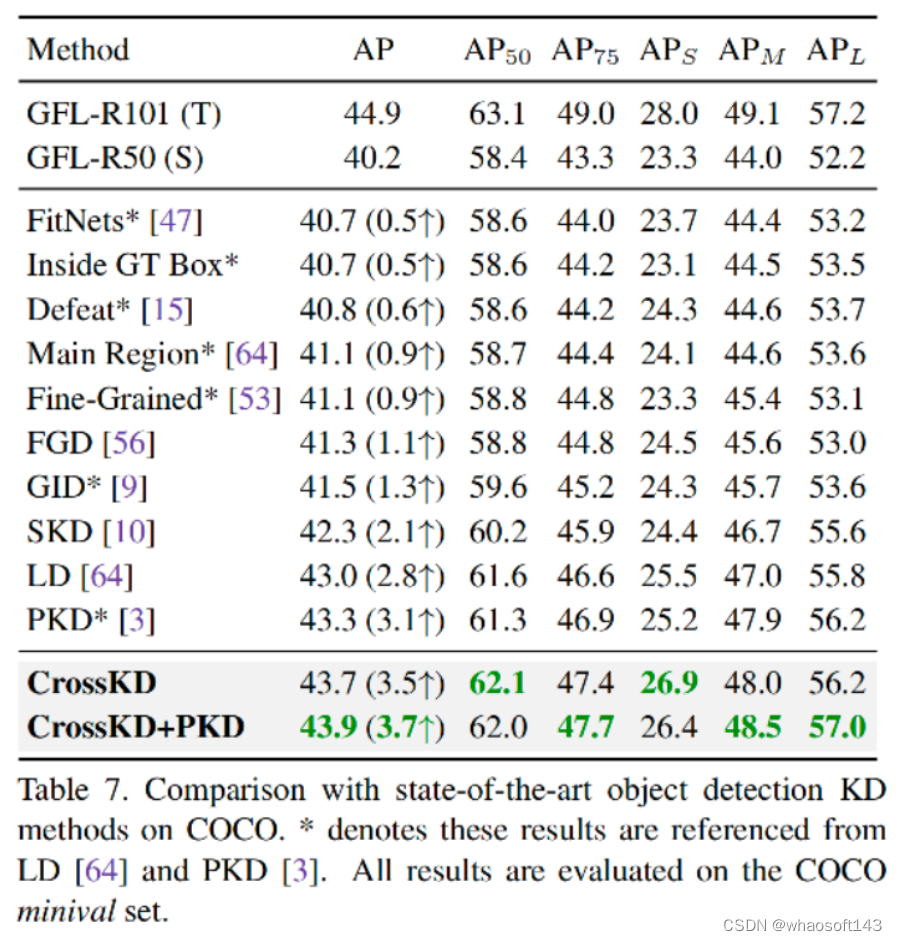
上表对比了不同蒸馏方案的性能,ResNet101为老师模型骨干,ResNet50为学生模型骨干,从中可以看到:
- 无需任何技巧,CrossKD去的了43.7mAP指标,指标提升高达3.5mAP;
- 相比特征模仿蒸馏方案PKD,CrossKD指标提升0.4mAP;
- 相比预测模拟蒸馏方案LD,CrossKD指标提升0.7mAP;
- 当与PDK组合时,CrossKD+PKD甚至取的了43.9mAP指标。
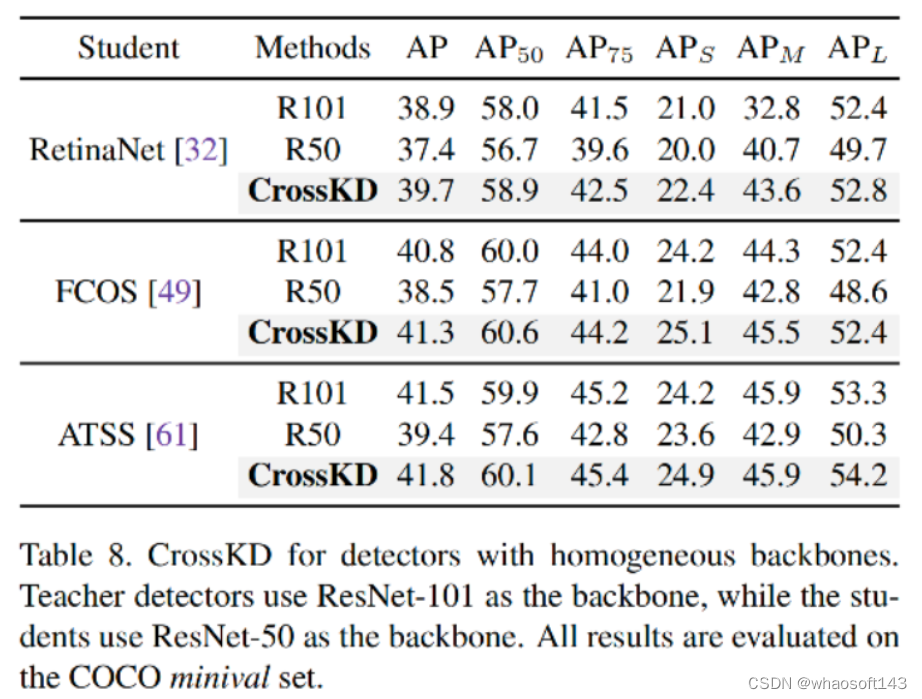
除了GFL外,上表继续在RetinaNet、FCOS、ATSS等检测架构下进行了对比验证,从中可以看到:
- CrossKD可以大幅提升三种类型检测器(RetinaNet, FCOS, ATSS)的性能,质保分别提升2.3mAP、2.8mAP以及2.4mAP;
- 值得一提的是,经CrossKD训练后的学生模型指标竟然超过了老师模型!!!
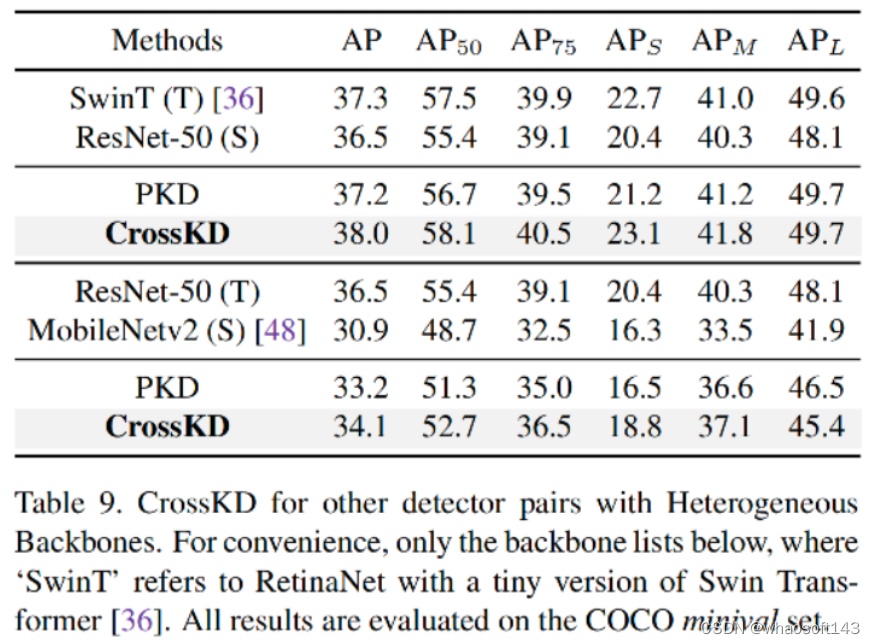
除了前述同构骨干外,作者进一步验证了异构骨干下Cross的性能,可以看到:
- 当SwinT向ResNet50进行蒸馏时,CrossKD取得了38.0mAP(+1.5mAP),比PKD高出0.8mAP;
- 当ResNet50向MobileNetV2进行蒸馏时,CrossKD去的了34.1mAP(+3.2mAP),比PKD高出0.9mAP。
消融实验结果
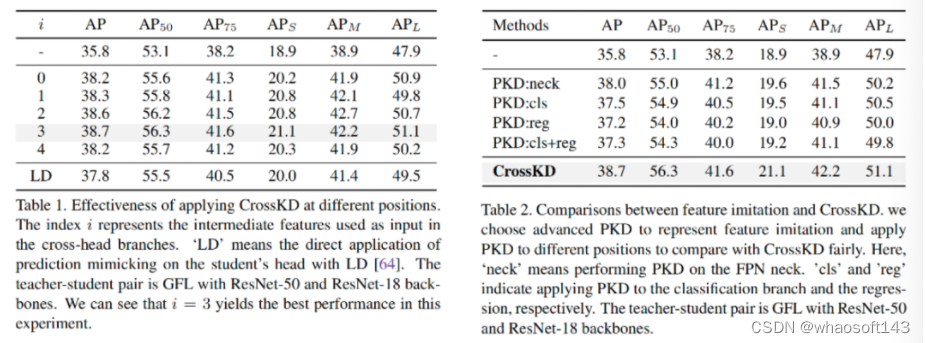
上表1对CrossKD的实施位置进行了消融分析,可以看到:
- 在所有蒸馏位置,CrossKD均可提升模型性能;
- 在第3个位置处取得了最佳性能38.7mAP,比已有预测模拟方案LD高出0.9mAP。
上表2对CrossKD与特征模仿方案PKD进行消融分析,可以看到:
- PKD作用在FPN特征时可以取得38.0mAP,当作用在检测头时模型性能明显下降;
- CrossKD取得了38.7mAP,比PKD方案高出0.7mAP。
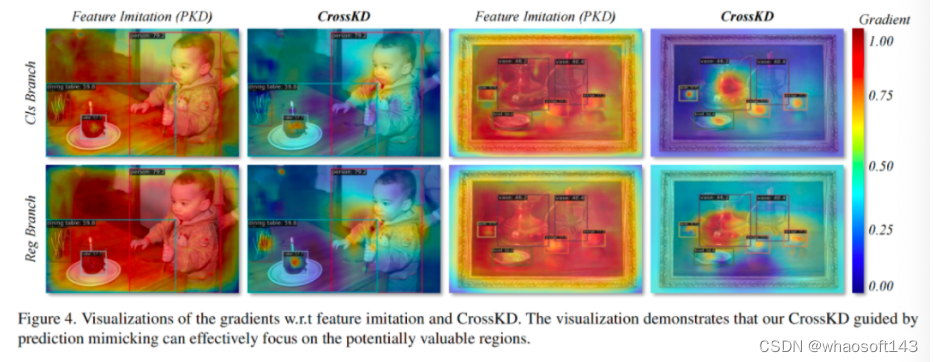
上图从可视化角度对比了PKD与CrossKD,可以看到:PKD生成的梯度对于完整特征图有大而宽的影响,而CrossKD生成的梯度仅聚焦在有潜在语义信息的区域。
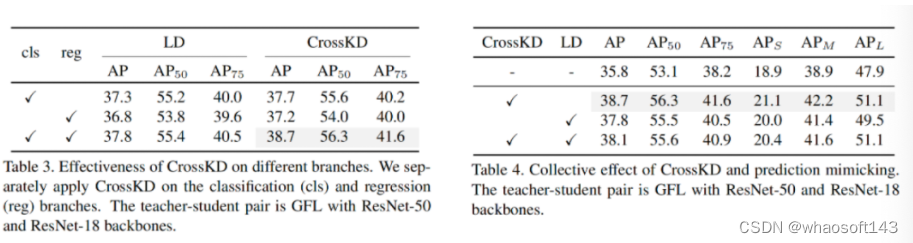
上表3+4对CrossKD与预测模拟方案LD进行了消融分析,可以看到:
- 将LD替换为CrossKD后可以取得稳定的性能提升;
- CrossKD+LD组合反而出现了性能下降,从CrossKD的38.7下降到了38.1.
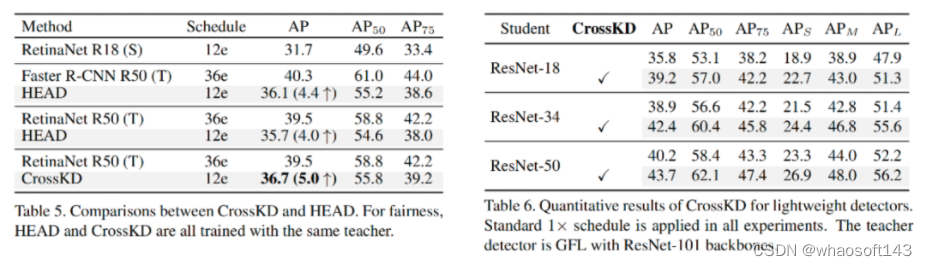
上表从异构蒸馏、轻量型检测器维度进行了消融分析。总而言之,CrossKD均可取得令人满意的性能。
















 1178
1178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









