






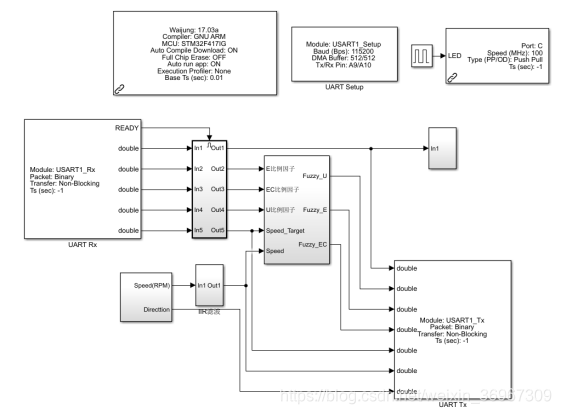
我们先来看一下整个模型
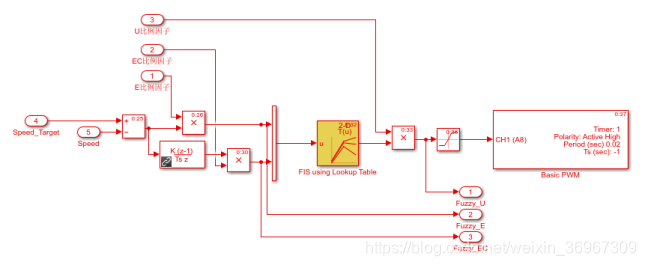
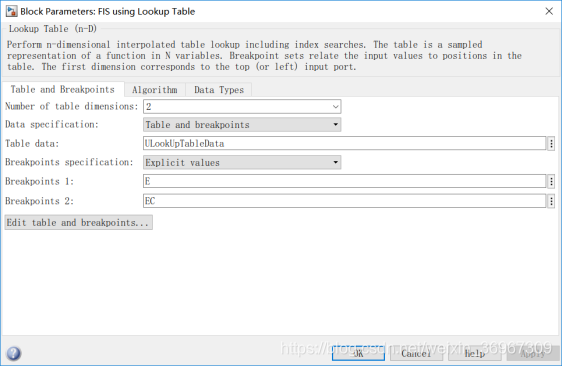
在代码生成阶段,我们需要把模糊逻辑转变成查表的形式,这样能优化不少的代码量,精度上也没有差别多少,不然代码量就成几倍的增加,运行起来就容易卡住,运行精度比较差。每次运行代码前,首先确定右边的工作区有没有我们所需要的变量,没有就先运行左边的M文件。
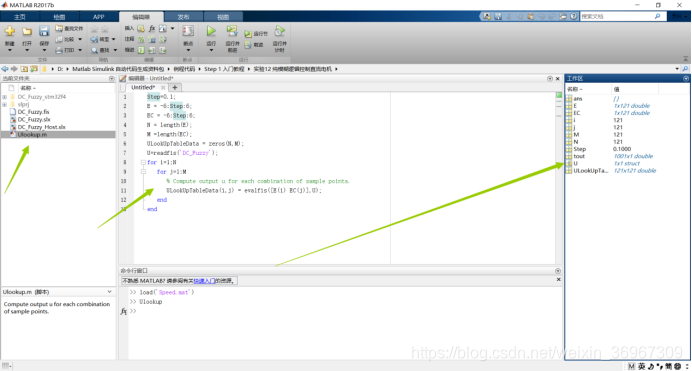
我们来看看M文件生成的表格,我们可以看到精度也是非常的高的,要是精度不要这么高,需要再进一步优化代码,2018B新出了一个优化代码的,你们可以去研究一下;
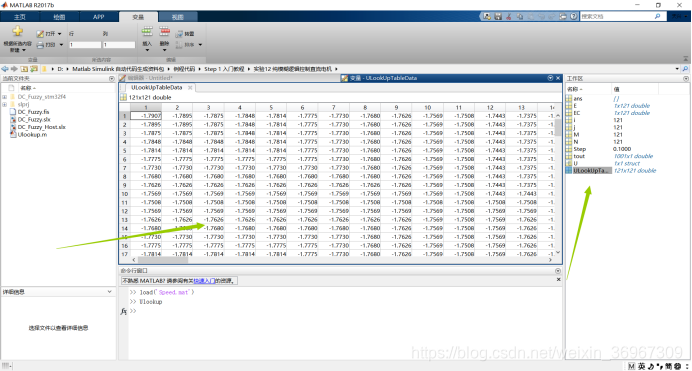
我们可以看一下代码生成的表格
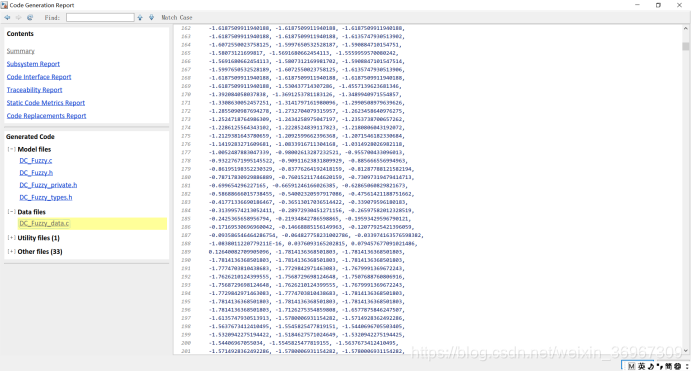
在MDK中调用的表格文件
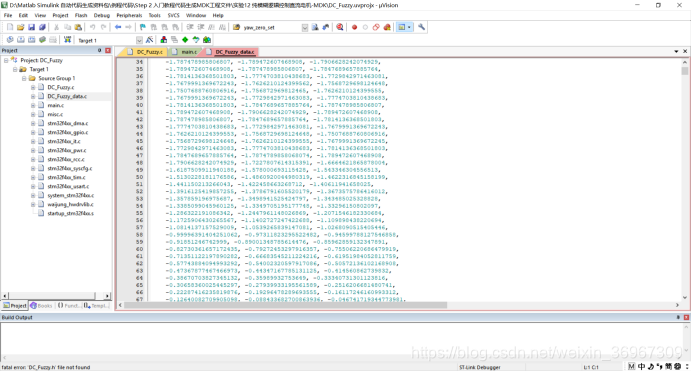
本节所需的全部文件代码如下,请自行下载:
链接:https://pan.baidu.com/s/10C9xdvA-wAwmDGp5ifVVpg
提取码:iqw1
如有疑问请留言

















 888
888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









