






哈哈 准备开始挪一些 cv相的合集~
一、CVの文档自动扫描仪
介绍如何使用 OpenCV + GrabCut实现一个文档自动扫描仪。
背景介绍
文档扫描是将物理文档转换为数字形式的过程。可以通过扫描仪或手机摄像头拍摄图像来完成。我们将在本文中讨论如何使用计算机视觉和图像处理技术有效地实现这一目标。
有许多软件解决方案和应用程序可以做到这一点。借助计算机视觉的力量,从物理文档到扫描文档的过程与将相机对准文档并单击图片没有太大区别。速度和易用性是此类解决方案的主要优势,它们可用于计算机和移动设备。
让我们看看如何使用经典的计算机视觉技术创建一个简单的 OpenCV 文档扫描仪,其中输入将是我们要扫描的文档的图像,而预期的输出将是正确对齐的文档扫描图像。
实现目标
如下图所示,给定一张包含文档的图片,通过代码自动将文档提取并矫正。

编辑
实现步骤
测试原图如下:

编辑
实现步骤:
【1】通过形态学处理,得到一个空白页。这里直接用闭运算即可,闭运算是膨胀,然后是腐蚀。不断重复这些关闭操作,直到你得到一个空白页。
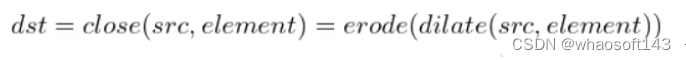
编辑

编辑
为什么我们想要一个空白文档呢?因为后面会进行边缘检测,并且我们不希望被页面的文字内容干扰该。
【2】用GrabCut去掉背景。
- 它只需要在前景中的对象周围设置一个边界框,边界框之外的所有内容都被视为背景。
- GrabCut 会自动消除所有背景,即使在边界框内也是如此。现在剩下的就是前景对象。
我们将角落 20 像素作为背景,GrabCut 会自动确定前景和背景,只留下文档。

编辑
【3】Canny边缘检测 + 轮廓提取。
- 首先将空白页的图像转换为灰度,因为canny只对灰度图像起作用。
- 然后执行高斯模糊以去除图像中的噪声。
- 最后,对图像进行精确边缘检测。
- 此外,放大图像以获得文档的细轮廓。
- 根据大小对检测到的轮廓进行排序
- 只保留检测到的最大轮廓
- 然后在空白画布上绘制这个检测到的最大轮廓

编辑
【4】角点检测 + 排序。
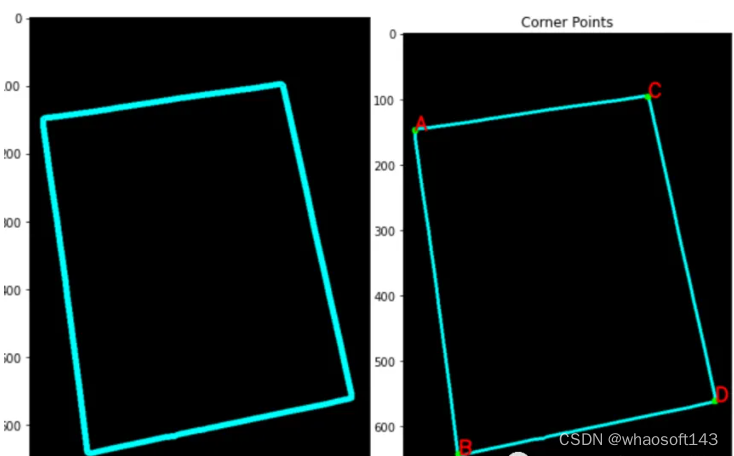
编辑
角点排序:
确定目标坐标:一旦获得文档的角点,接下来只需要目标坐标来执行透视变换和对齐文档。
【5】透视变换对齐文档。

编辑
【6】扩展测试。
我们在 23 种不同的背景和不同的方向上进行了测试,自动文档扫描仪几乎在所有情况下都运行良好。

编辑
失败情况:
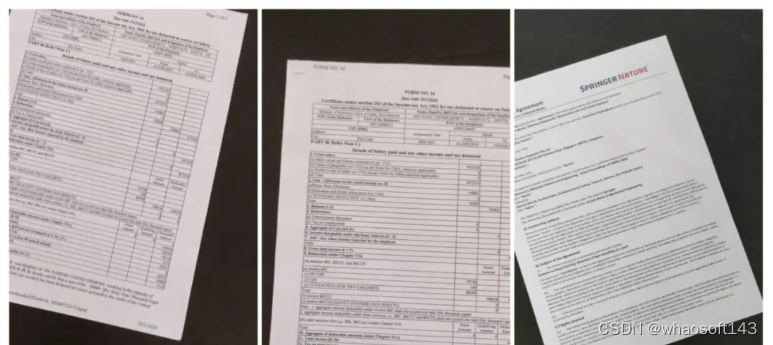
编辑
当文档的一部分在图像之外时,可能会丢失一个角落,GrabCut 无法扫描。这是使用 GrabCut 的唯一限制。在大多数其他情况下,我们的文档扫描仪运行良好。
这种方法的另一个限制是边缘和轮廓检测。如果背景中存在大量噪声,则会检测到许多不需要的边缘,并且在某些情况下,轮廓检测步骤可能会将这些边缘误认为是文档。此外,如果文档边缘与背景无法区分,则轮廓检测可能无法完全正常工作。
但 GrabCut 和轮廓检测并不是唯一经过验证的文档扫描方法。对于消费级文档扫描解决方案,首选角点检测和分割等深度学习技术,因为它们更强大。
参考链接:
https://learnopencv.com/automatic-document-scanner-using-opencv/
二、CVの复杂背景下的直线提取
介绍一个基于OpenCV实现的复杂背景下直线提取实例
案例来源于网络,如下图所示,要求提取图中的直线轮廓并标出:

编辑
实现步骤与代码
【1】中值滤波滤除噪点(中值滤波对椒盐噪声效果较好)。
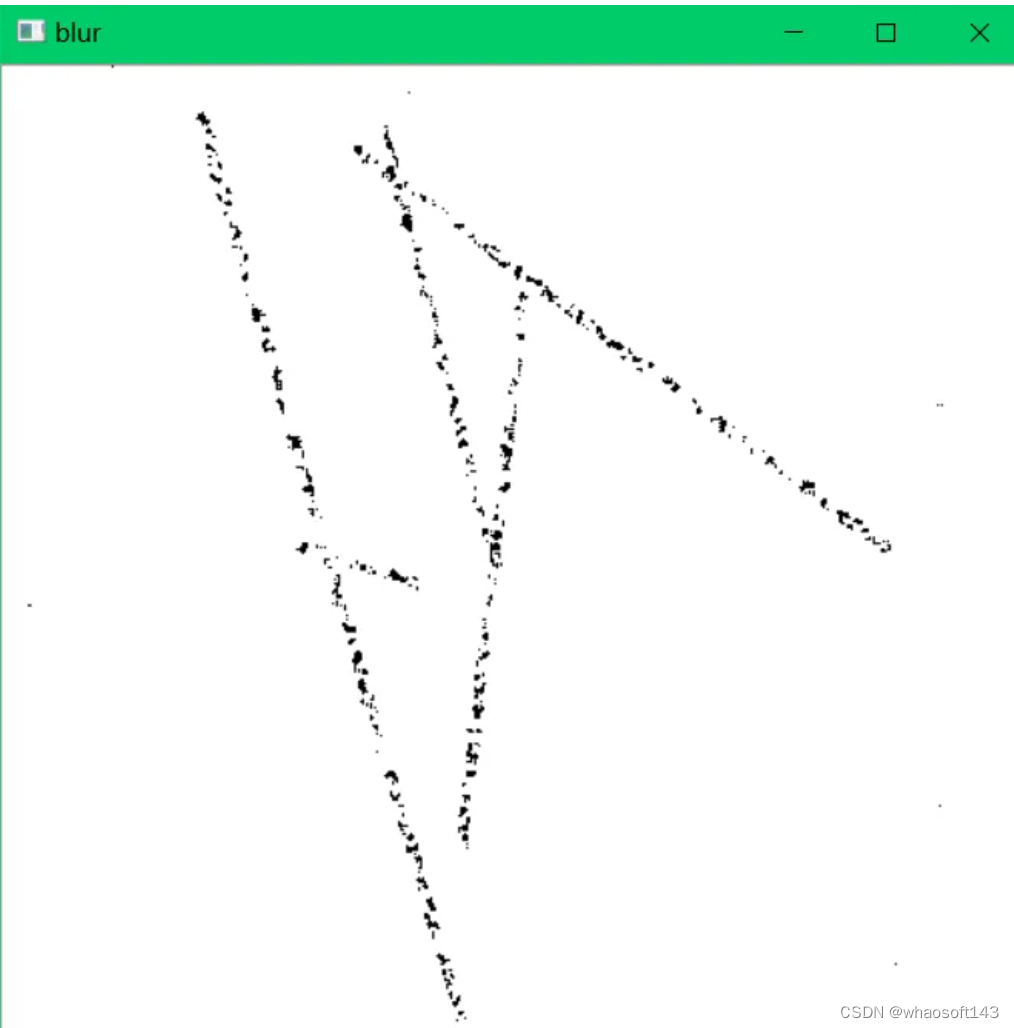
编辑
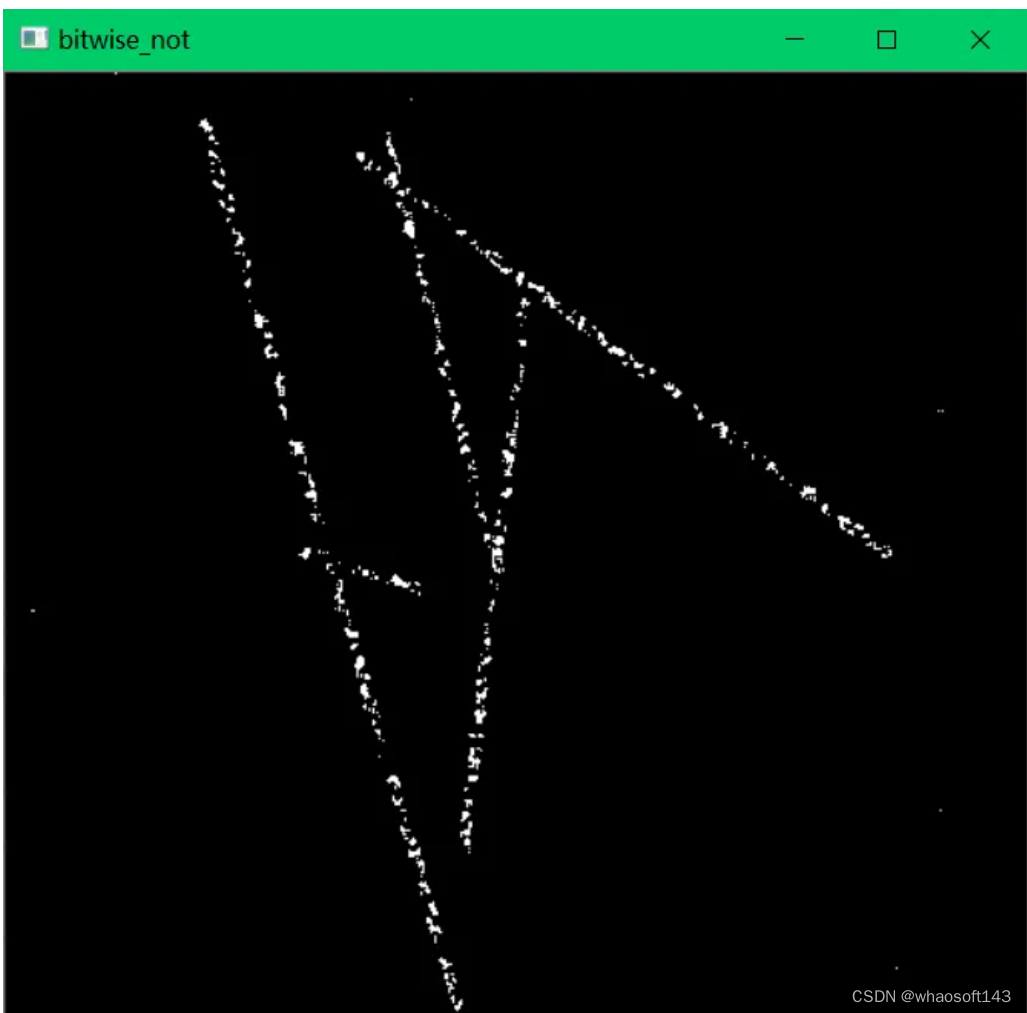
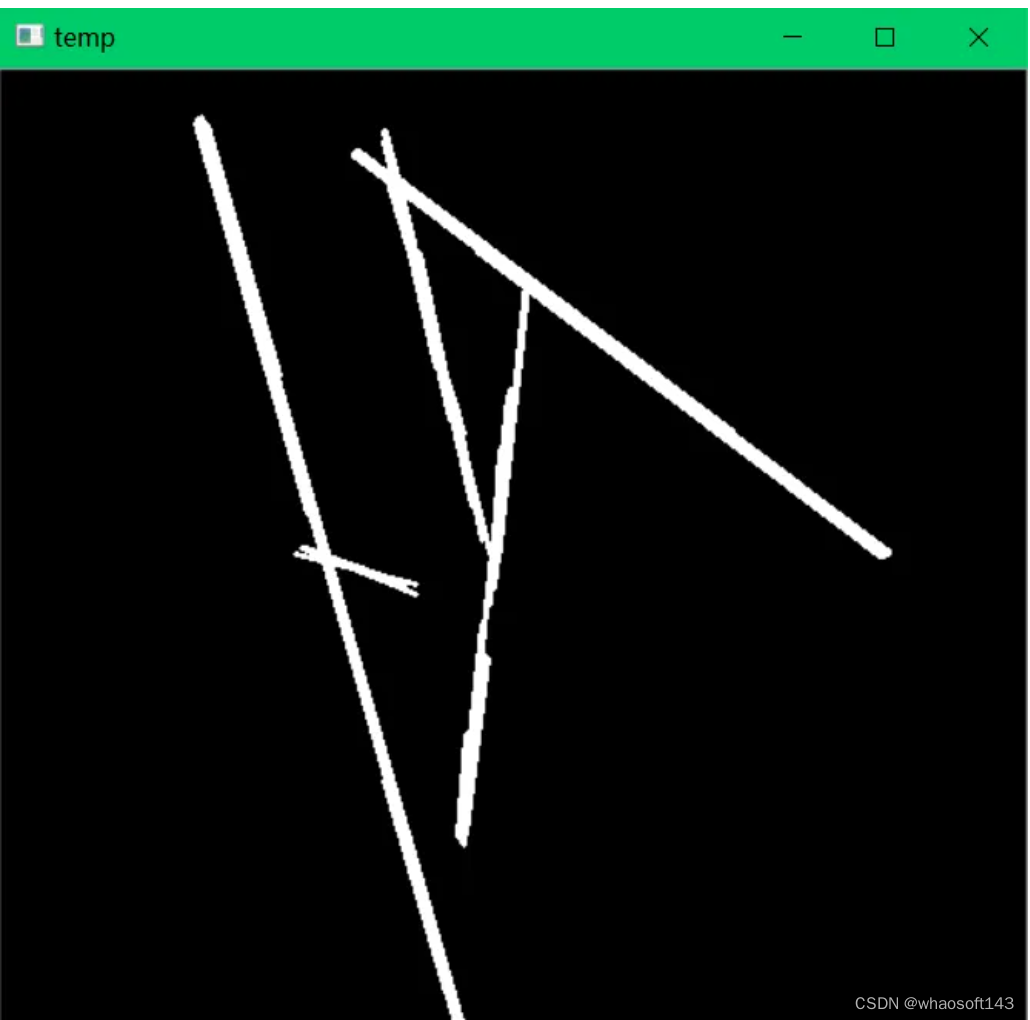
【2】滤波图像取反,然后使用HoughLinesP(累计概率霍夫变换)检测直线。图像取反原因是HoughLinesP是在黑色背景中找白色直线,这样效果更好。
编辑
编辑
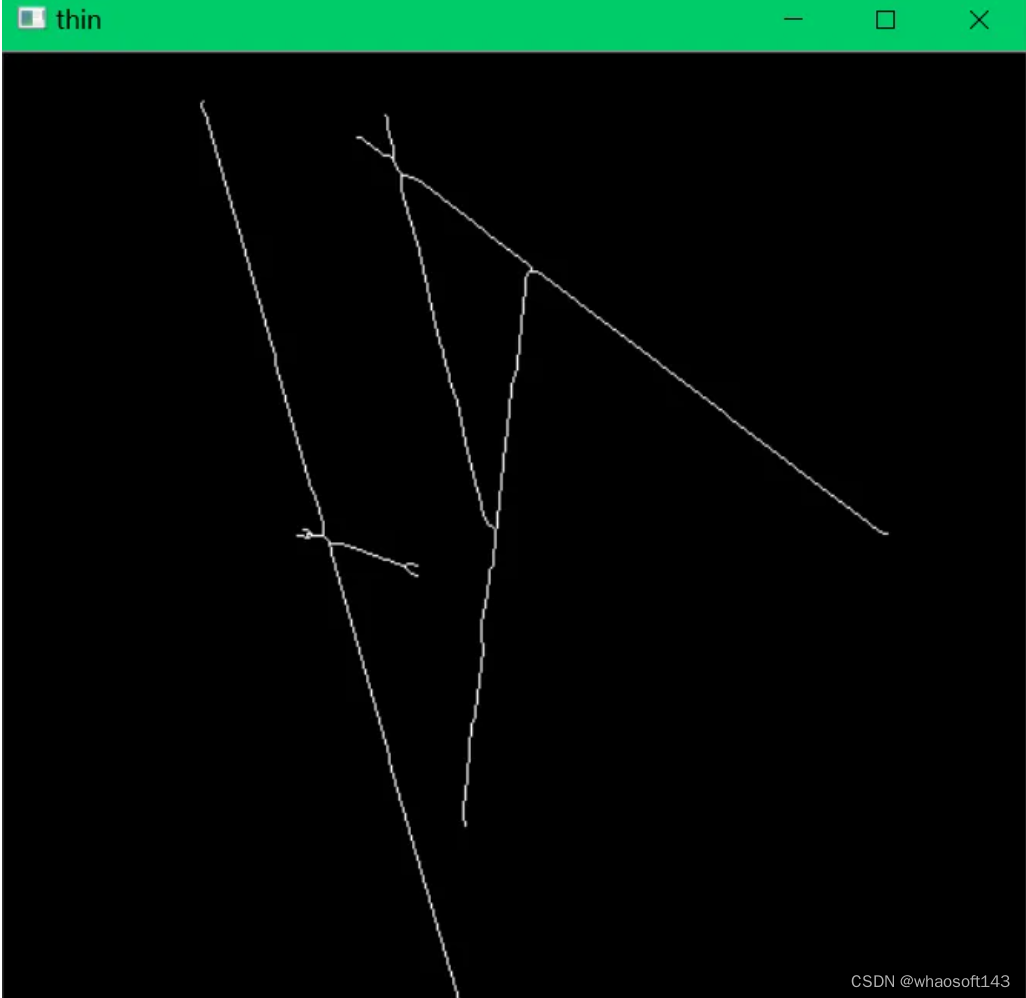
【3】将检测到的直线的二值图细化。
编辑
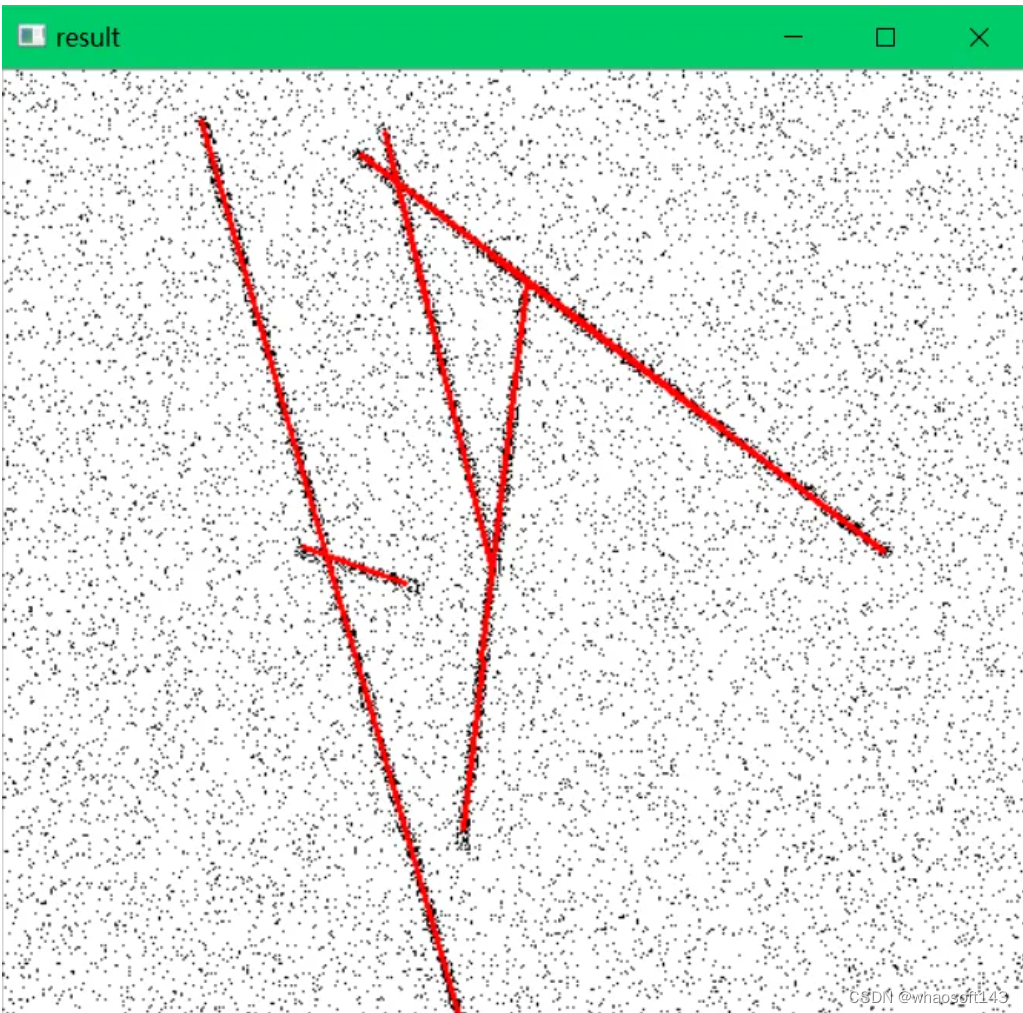
【4】使用细化图像再做一次HoughLinesP(累计概率霍夫变换)检测直线。
编辑
三、CVの测量圆弧长度
介绍基于OpenCV实现两种方法测量圆弧长度
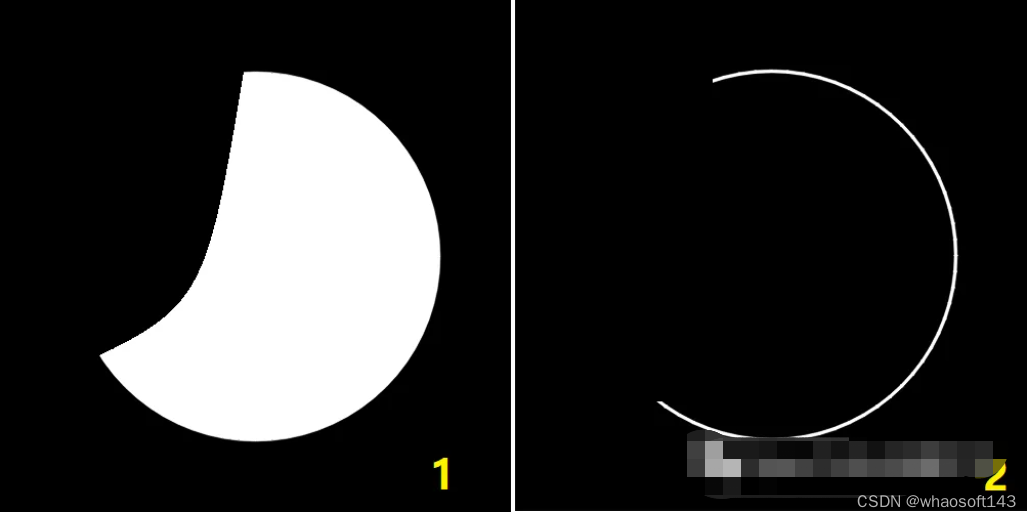
编辑
要求:如上所示,分别用OpenCV计算出图1和图2中圆弧的长度。因为OpenCV中没有提供现成计算圆弧的方法,所以需要自己编写,本文将提供2种不同的方法来实现,仅供参考。
实现步骤

编辑
首先以图1为例,如上图所示,方法一具体实现步骤如下:
【1】二值化 + 查找轮廓
【2】查找轮廓凸包缺陷,确定圆弧起点和终点坐标
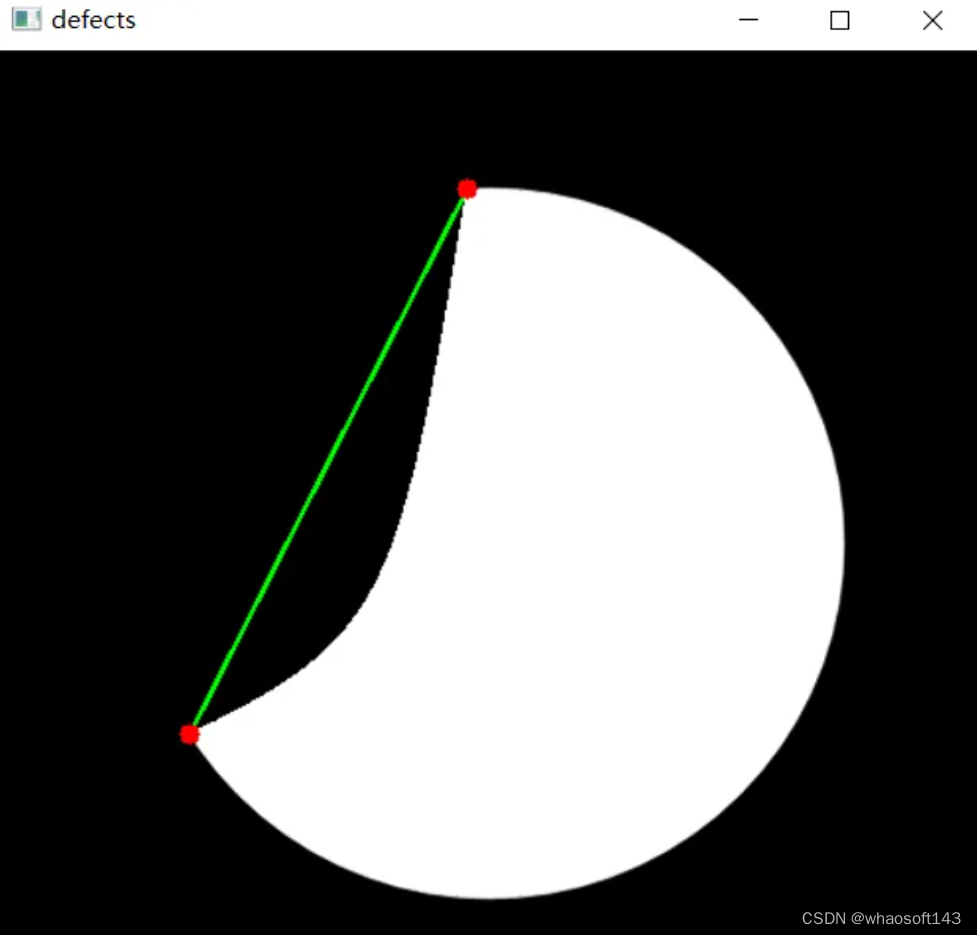
编辑
【3】获取轮廓最小外接圆,获取圆心,计算圆弧角度
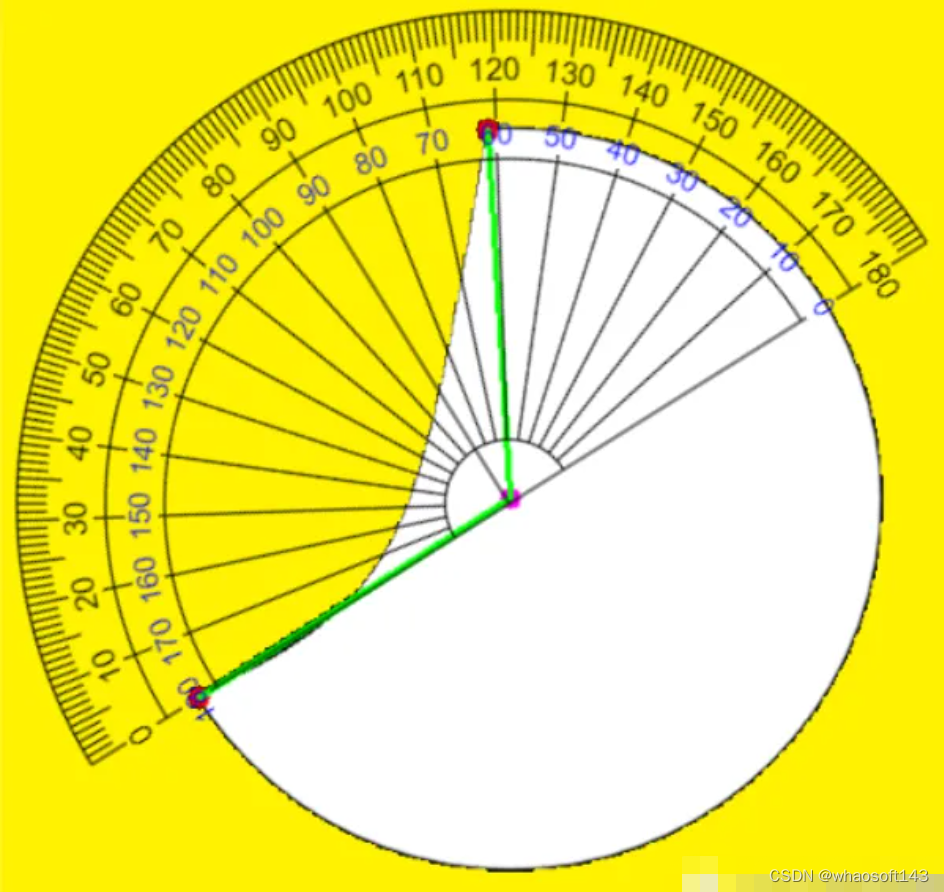
编辑

编辑
【4】通过外接圆周长角度比例来计算弧长
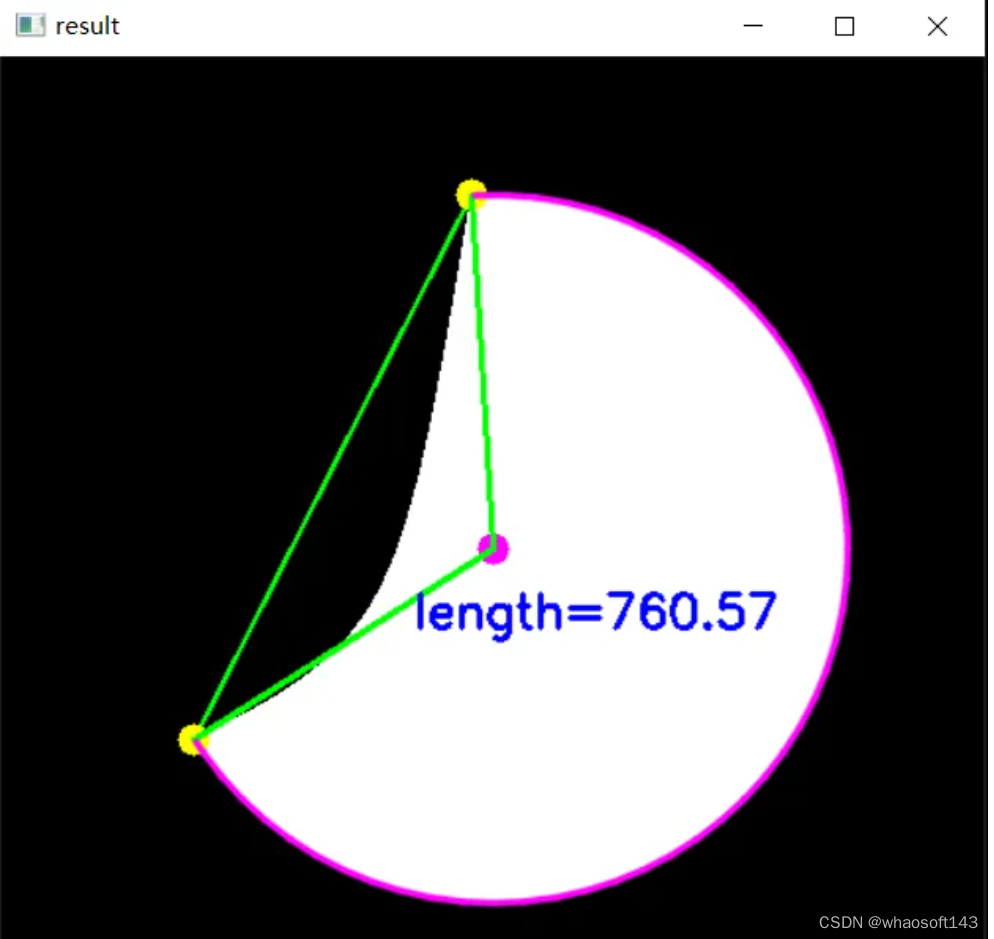
编辑
以图2做测试,验证结果:
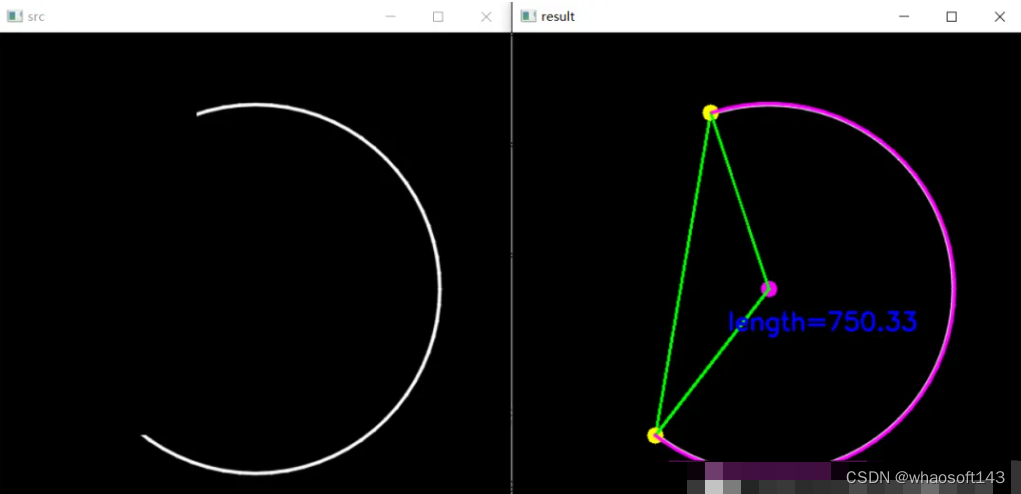
编辑
方法二将步骤【2】替换为通过角点检测来获取弧线端点坐标:
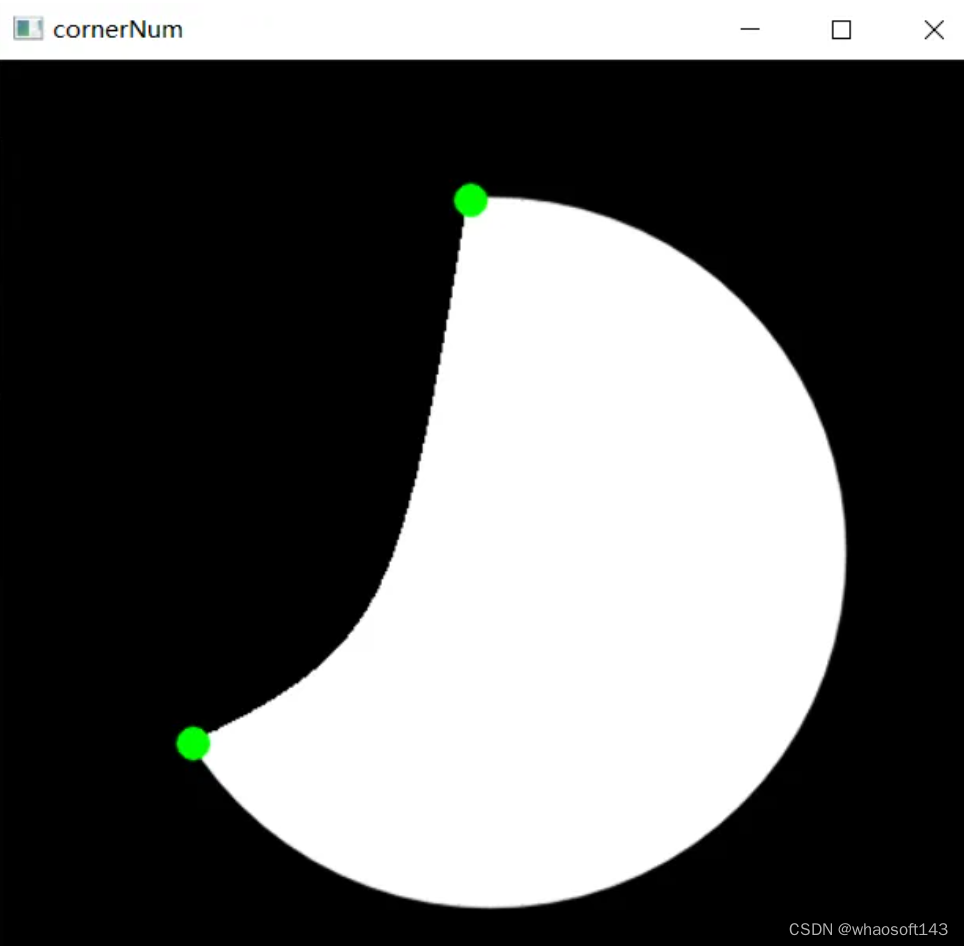
编辑
最终结果:
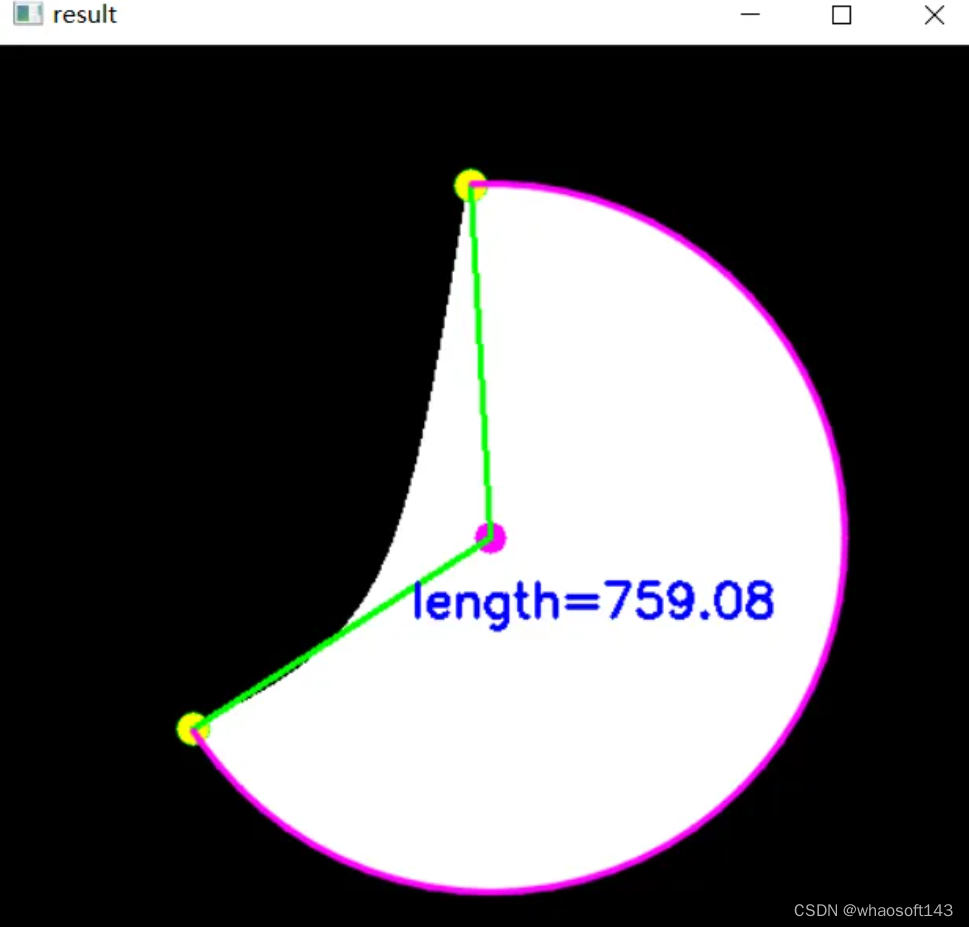
编辑
测试图2结果:
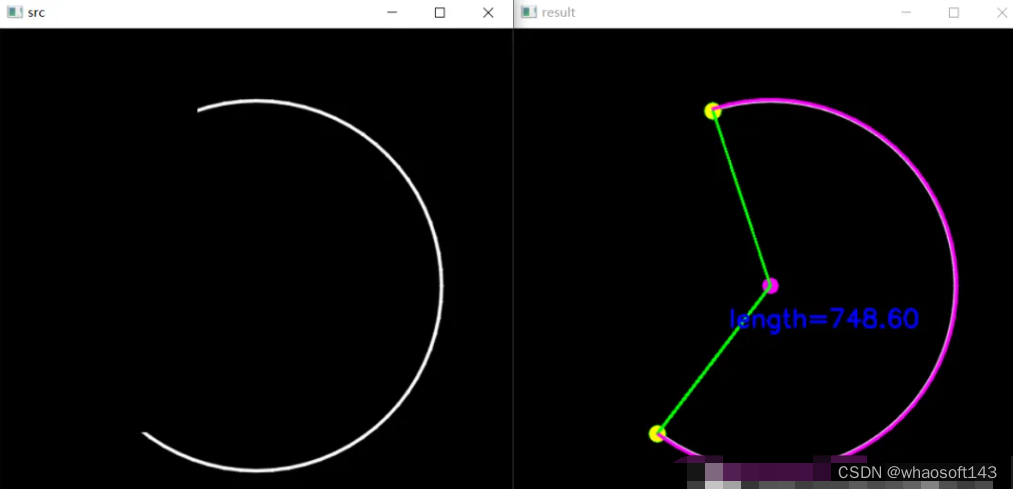
编辑
四、CVの魔方颜色识别与色块排序
为了做自动魔方识别与复原项目,需要用图像处理的方法识别魔方每个色块的位置与颜色。相机拍摄的魔方单面图像如下:

编辑
实现步骤
本文主要使用OpenCV来实现魔方颜色识别与色块位置排序。
【1】颜色识别。设定每个色块在HSV颜色空间的范围来判断和提取颜色。
【2】提取色块掩码。在步骤【1】的基础上添加形态学处理,然后通过或操作
将所有色块区域提取出来。

编辑
【3】色块排序。排序使用imutils包的contours模块实现。

编辑

编辑
当然,还可以从下到上,从右向左排序。只需要设置下面的method即可:

编辑

编辑

编辑
【4】如何获取HSV范围。可以使用下面代码,通过滑动条动态调整的方法获取:

编辑

编辑

编辑

编辑
五、CVの检测并计算直线角度
检测线可用于各种类型的应用,例如机器人导航、无人机导航、运动分析和交通管理。本文我们将使用HoughLinesP函数来检测线条并从线条中提取角度。
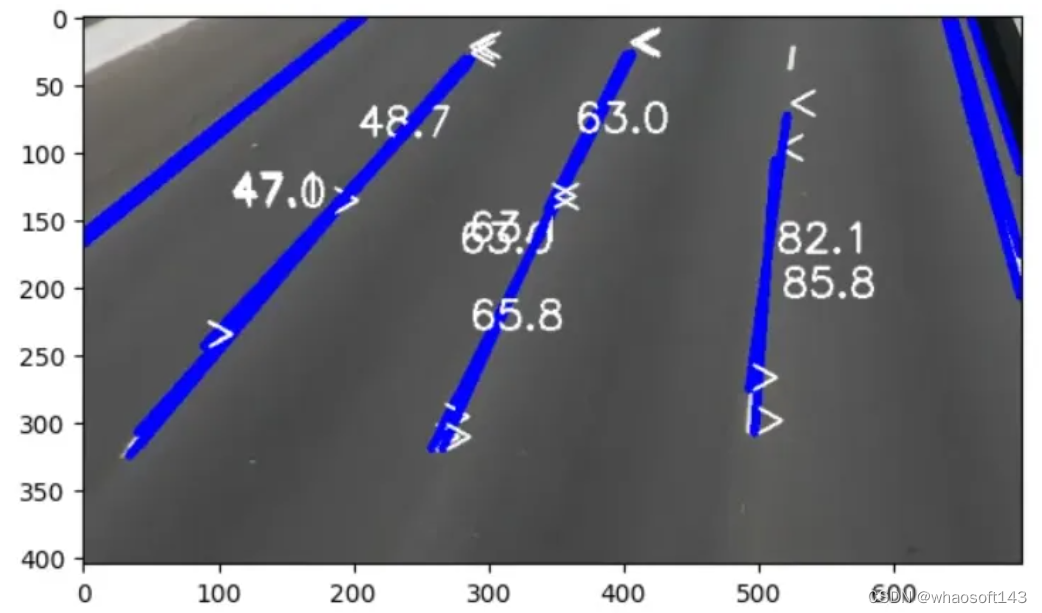
编辑
检测线
想象一下,您想要创建一架无人机或一辆可以沿着路线行驶的简单汽车。事实上,创造和使用它似乎很有趣。或者您可能想跟踪道路上的线路并根据车道对汽车进行分类。对于这些类型的程序,您需要检测线条,并且可能需要根据您的目的提取角度。OpenCV 提供了多种检测直线和提取角度的函数:
- HoughLines()
- HoughLinesP()
选择合适的功能
HoughLinesP可以检测碎片或不连续线(例如图像中的虚线或线段)时更有效。它提供有关检测到的线路的更多详细信息。
HoughLines更适合检测完整、连续的线条。当检测图像中长的、不间断的线条时,它非常有用。
我们需要一种可以检测各种形状的线条的算法,而不仅仅是直线。例如,如果道路向右成 45 度角,则 HoughLines() 函数在这种情况下可能无效。因此,我将使用HoughLinesP()函数
HoughLinesP() 函数如何工作?
我不会深入研究该HoughLinesP()函数的数学细节,因为 Google 或 Youtube 等平台上有很多可用的资源。下面简单解释一下该HoughLinesP()函数的工作原理:
OpenCV 中的函数HoughLinesP使用概率霍夫变换来检测图像中的线段。
- 从边缘检测开始提取潜在的线点,然后进行投票过程来识别经过这些点的线,在参数空间中累积投票。
- 参数空间是霍夫变换累积投票以检测图像中的线条的地方,每个维度代表被检测模型的一个参数,例如线条的斜率和截距。
- 在阈值化选择突出线之后,它提取由端点表示的线段,提供有关其位置和长度的详细信息。
这种方法可有效检测碎片或不连续的线,例如虚线或线段,与传统方法(如HoughLines.
HoughLinesP() 函数的参数
HoughLinesP(image, rho, theta, threshold,minLineLength,maxLineGap)
- image:8 位、单通道输入图像。
- rho:累加器的距离分辨率(以像素为单位)。(1在大多数情况下是有效的)
- theta:累加器的角度分辨率(以弧度为单位)。(np.pi/180)
- 阈值:简单的阈值。较高的阈值会导致线条更少但更准确,而较低的阈值会产生相反的效果。设置此参数的最佳方法是尝试不同的值。这完全取决于您的目的。
- minLineLength:最小行长度。
- maxLineGap:同一直线上的点之间允许的最大间隙以链接它们。
选择这些参数(Threshold、minLineLength 和 maxLineGap)的最佳方法是尝试不同的值组合。这些参数没有通用的最佳值;它们取决于图像的具体特征和期望的结果。
检测直线时如何使用提取的角度?
想象一下算法从直线中提取出 67 度角。等式为:
编辑
步骤/代码
1. 读取图像并将其转换为灰度
2. 使用 Canny 边缘检测器提取边缘。
3. 对Canny边缘检测后得到的图像应用HoughLinesP函数。
4. 获取 HoughLinesP 函数的输出,对其进行迭代,绘制线条,并使用简单的公式提取角度。
Canny 边缘检测
Canny 边缘检测器有助于识别图像中的边缘
编辑
检测直线并计算角度代码:
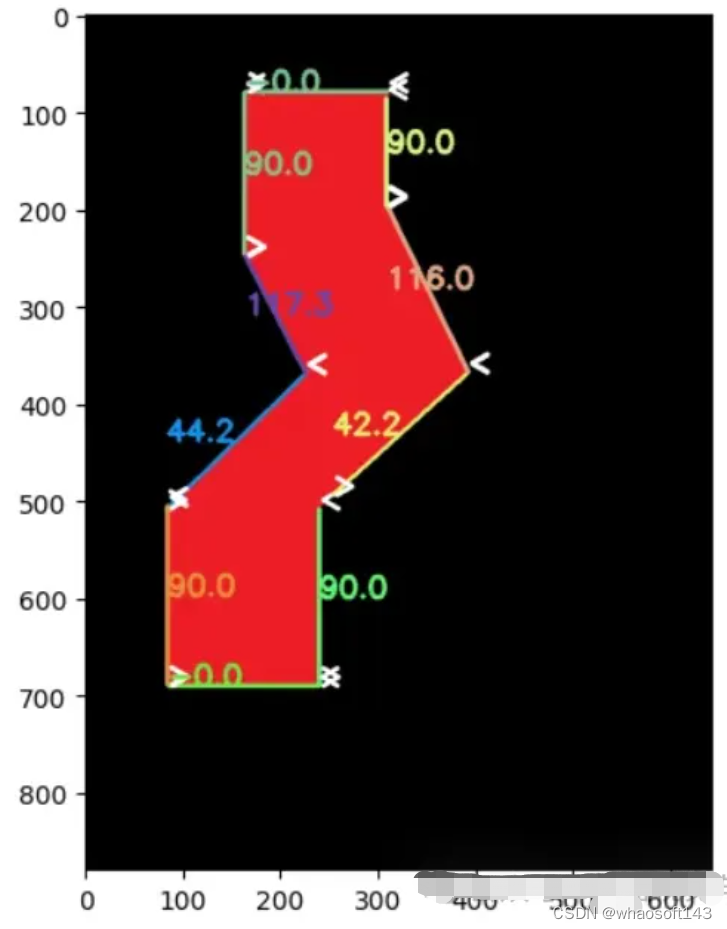
编辑
编辑















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









