







1.卷积层的前向计算
如下图,卷积层的输入来源于输入层或者pooling层。每一层的多个卷积核大小相同,在这个网络中,我使用的卷积核均为3*3。
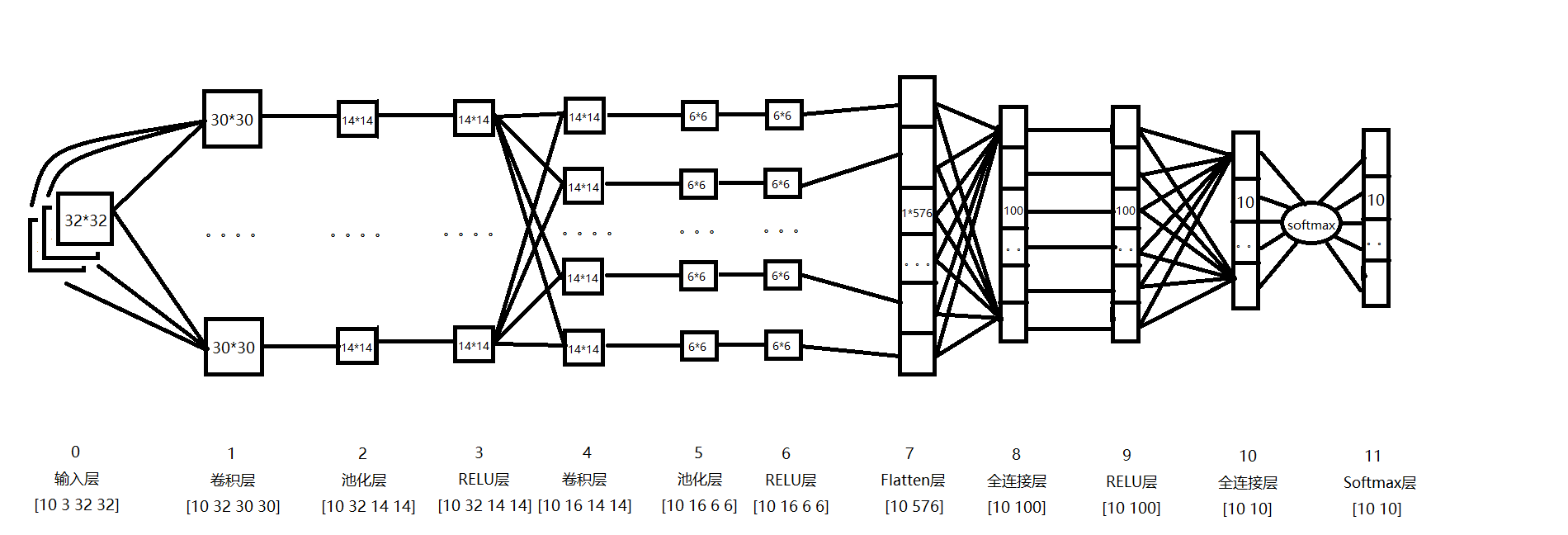
如图第4层卷积层输入为14*14的图像,经过3*3的卷积之后,得到一个(1+(14+2*1-3)/1)*(1+(14+2*1-3)/1) = 14*14的map。卷积层4的每个map是不同卷积核在前一层每个map上进行卷积,并将每个对应位置上的值相加然后再加上一个偏置项。
1.1 卷积层输出map大小【同时也是卷积核滑几步】计算公式:
1.2 正向传播原理
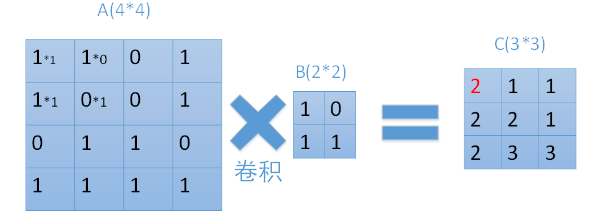
每次用卷积核与map中对应元素相乘,然后移动卷积核进行下一个神经元的计算。如图中矩阵C的第一行第一列的元素2,就是卷积核在输入map左上角时的计算结果。在图中也很容易看到,输入为一个4*4的map,经过2*2的卷积核卷积之后,结果为一个(4-2+1) *(4-2+1) = 3*3的map。
那么在一个map上进行卷积操作过程如下: 1
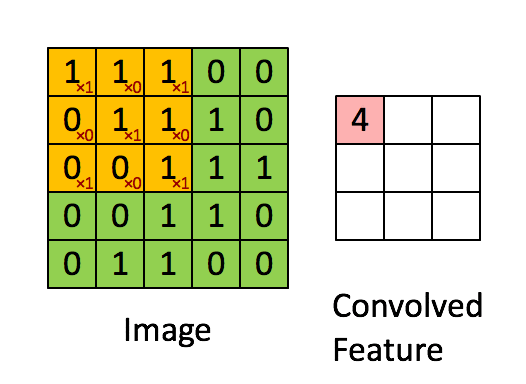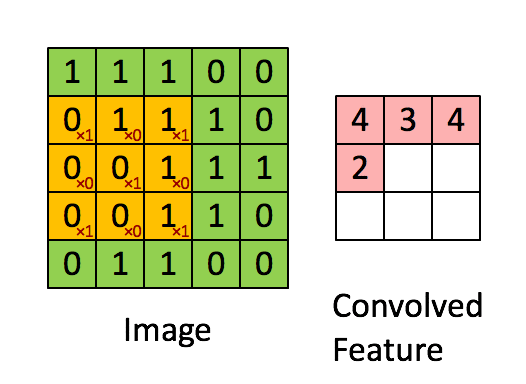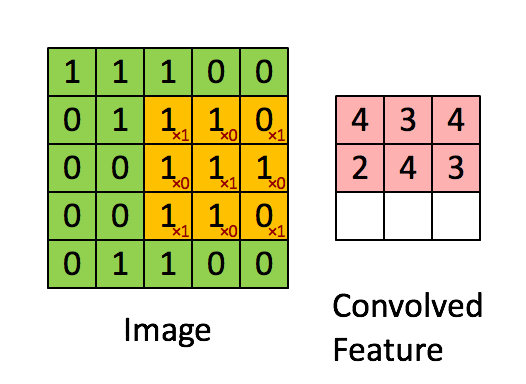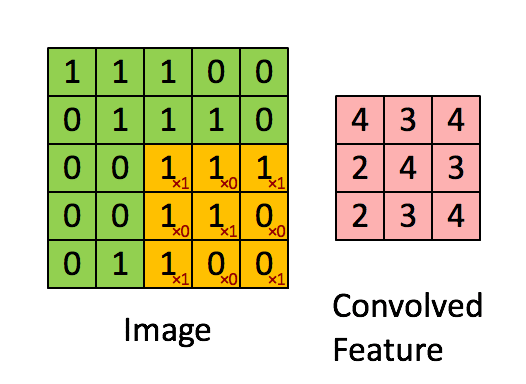
1.3 计算公式
怎样用公式表示呢?
这里我们要与全连接做类比:
首先看一个输入是3个数,输出是3个数的全连接的例子:
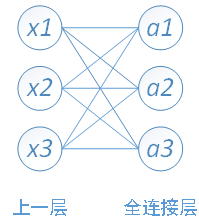
那么weight矩阵是一个3X3的矩阵:
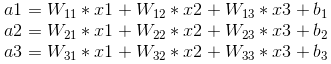
然后,我们再看一下我们当时讲解全连接的时候 2,加入batch=10时,怎样用矩阵表达:

从上图可以看出,权重矩阵weight的维数是100X10,左边100表示每个batch输入数据的神经元个数,右边10代表每个batch输出数据神经元个数。
有了以上基础,下面我们讲解卷积层的weight怎样表达:
首先,我们看一下输入数据的形式x[10 32 14 14],这个表示每个batch有10个图像,每个图像在这层有32个channel,也就是32个map,每个map大小是14*14。输出是a[10 16 14 14],说明层卷积没有改变每个map大小,只改变了channel的个数,从32变成16了。
由于10幅图像共用一套卷积核以及bias,且正向传播10幅图像数据无交叉(看到这句话,你懂得,说明反向传播数据有交叉,随后再表)。所以,这里,我们只展示一个图像,也就是x[0]的卷积过程,输入时[32 14 14]也就是32个14*14的map。输出是a[0],输出的数据形式是[16 14 14] 也就是16个14*14的map。
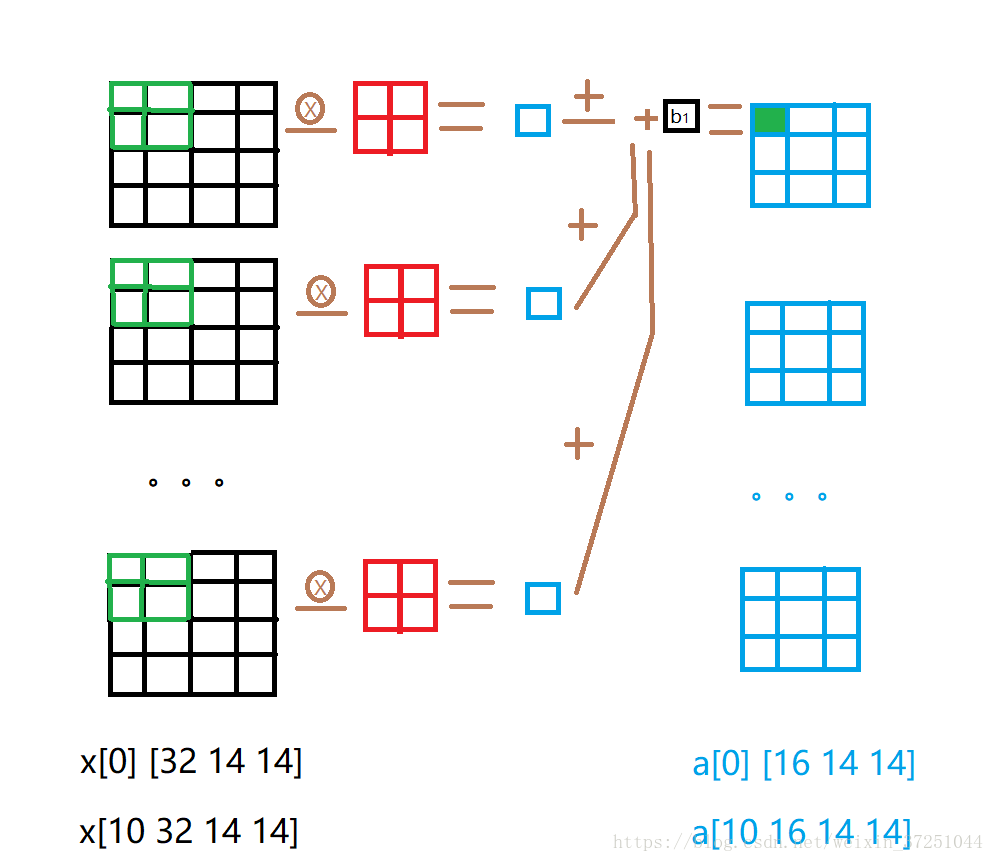
从上图可以看出我们输出的一个神经元也就是a[0]的第一个channel的map的第一个神经元是怎样通过卷积计算出来的。
有了这个基础,我们可以将3X3的卷积核类比与全连接的weight的一个数w11,那么矩阵表示batch=10的卷积层正向传播公式是:

你会发现很奇怪,为什么Bottom data数据第一维是10,怎么和Weight进行卷积,现在我们与全连接做个对比,我们将14*14的map想象成全连接中的一个神经元,那么我们上图可以简化成:

是不是和全连接很相似?
现在,你应该大致明白带batch=10的卷积是怎么计算的了,当然上图公式是不对的,因为中间是卷积,很难用公式表达,我们这样写仅仅是为了让你明白卷积输入输出数据维数的变化。
2.反向传播
我们首先放卷积层的反向传播公式,然后再通过一个小例子理解这个公式:
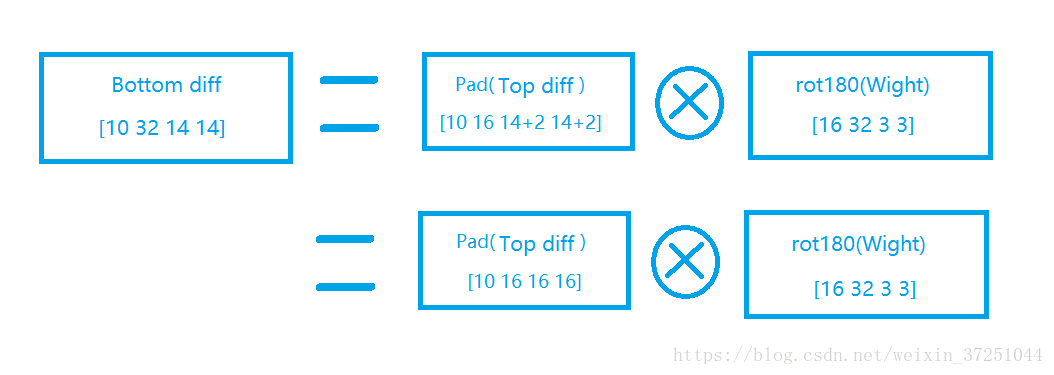
1.对输入数据的求导:
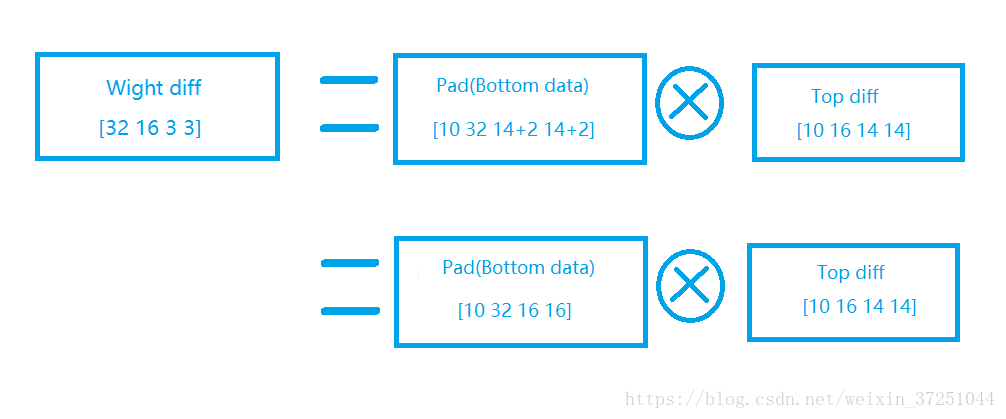
2.对W的求导:
注:
关于w求导有些博客说的是rot180(Bottom),这个说法是错误的,详情请见我的另一篇博客推导:【卷积层的误差,推导该层的W,b的梯度】
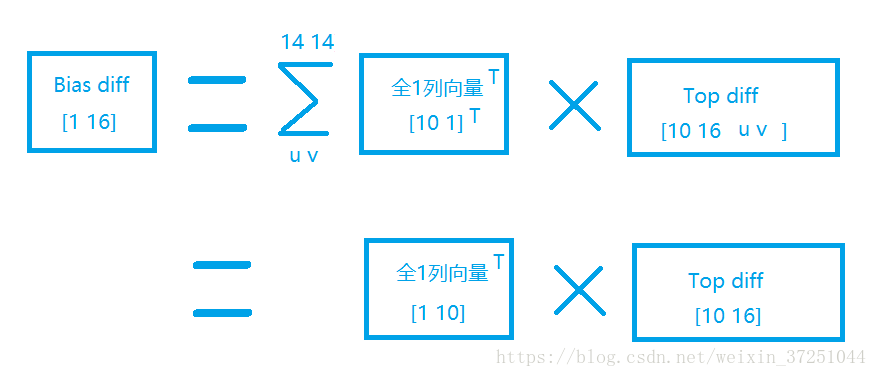
3.对b的求导:
这里,我们首先简单介绍一下公式含义:
- ⊗ ⊗ :代表卷积计算。
- rot180() r o t 180 ( ) 代表3*3的卷积核顺时针旋转180度,与数组前两位32,16无关。
3. 右上角的 T T 代表转置,转的是数组的前两维32和16,与后边卷积核无关。
下面我们通过一个简单的例子理解一下为什么要:34
首先,如下图所示,我们例子的输入x是3*3的数组,卷积核w是2*2的数组,卷积步长stride是1,所以卷积结果a是2*2的数组:

我们列出a,W,x的矩阵表达式如下:
利用卷积的定义,很容易得出:
接着我们反向求导【这里求的是对输入数据X求导,这里我们先写个伪公式】:
矩阵形式是:
那么现在问题变成了怎样求 ∂A∂X ∂ A ∂ X 。从前面的前向计算过程中可以找出x11参与了A中哪些元素的计算,并且可以根据对应的前向计算得出反向传播的计算公式:
这上面9个式子其实可以用一个矩阵卷积的形式表示,即:
为了符合梯度计算,我们在误差矩阵周围填充了一圈0,此时我们将卷积核翻转后和反向传播的梯度误差进行卷积,就得到了前一次的梯度误差。这个例子直观的介绍了为什么对含有卷积的式子求导时,卷积核要翻转180度的原因。
那么,现在我们可以把伪公式的细节补充完整了:
【注意: pad p a d 是边缘扩充, rot180 r o t 180 是顺时针旋转180度】
至此,我们这个小例子介绍完毕,最后,将公式扩展到batch=10矩阵形式,就是我刚才给的第一个公式。
3 代码
3.1 正向传播代码
当然,我们首先会写出按照以上推导过程写出一般卷积计算代码,之后会介绍一种caffe使用的的将卷积展开利用类似全连接的方式的快速计算方法。
3.1.1 卷积计算代码
边缘填充:
#5.4.2 卷积层逐行推导
relu1_data = np.load('./data_pic/data_3_relu1[10-32-14-14].npy')
print ("卷积层的输入的shape是:\n"+str(relu1_data.shape))
pad = 1
in_data_pad = np.pad(relu1_data, ((0,), (0,), (pad,), (pad,)), mode='constant', constant_values=0) #边缘填充,这里上下左右各填一个像素
print ("\n卷积层的输入边缘填充之后的shape是:\n"+str(in_data_pad.shape))
print ("\n卷积层的输入边缘填充之后的第一个batch的第一个channel的前三行是:\n"+str(in_data_pad[0][0][0:3][0:3]))
输出是:
卷积层的输入的shape是:
(10, 32, 14, 14)
卷积层的输入边缘填充之后的shape是:
(10, 32, 16, 16)
卷积层的输入边缘填充之后的第一个batch的第一个channel的前三行是:
[[ 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. ]
[ 0. 228.16981617 231.87908912 10.9591378 234.18484757
333.35152431 526.07015154 526.07015154 380.23810493
309.41226069 0. 4.80179354 14.79101222 0.
670.60319805 0. ]
[ 0. 228.16981617 228.16981617 33.96253746
286.69109618 333.35152431 526.07015154 526.07015154
380.23810493 229.26636401 34.35036528 34.35036528 0.
35.01976076 1028.70345771 0. ]]卷积:
in_data_pad_masked = in_data_pad[:, :, 0:3, 0:3]
print ("卷积层输入数据的32个channel的map的3X3的小块:")
print (in_data_pad_masked.shape)
print ("\n卷积层输入数据的第一个batch的第一个channel的map的3X3的小块:")
print (in_data_pad_masked[0][0])
conv2_w = np.random.randn(16,32, 3, 3) #w初值设置,随机产生标准正太分布范围内的数
print ("\n第一个输入数据对应第一个输出数据的卷积核,类似于全连接中的W11:")
print (conv2_w[0][0])
conv2_b = np.random.randn(16)
conv2_out = np.zeros((10 , 16 , 14, 14))
conv2_out[:, 0 , 0, 0] = np.sum(in_data_pad_masked * conv2_w[0, :, :, :], axis=(1,2,3))#+ conv2_b[0]
print ("\n卷积层输出数据的第一个batch的第一个channel的map的3X3的小块")
print (conv2_out[0][0][0:3])输出是:
卷积层输入数据的32个channel的map的3X3的小块:
(10, 32, 3, 3)
卷积层输入数据的第一个batch的第一个channel的map的3X3的小块:
[[ 0. 0. 0. ]
[ 0. 228.16981617 231.87908912]
[ 0. 228.16981617 228.16981617]]
第一个输入数据对应第一个输出数据的卷积核,类似于全连接中的W11:
[[ 0.20893712 -0.61285893 -3.3728003 ]
[ 0.46570862 -1.27608147 -0.16116979]
[-0.40498215 -0.01740633 1.49654965]]
卷积层输出数据的第一个batch的第一个channel的map的3X3的小块
[[-5821.67267945 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[ 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[ 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]]
3.1.2 快速计算方法
快速计算方法来源于博主5对caffe的源代码的读取。
Caffe中卷积的实现十分巧妙,它将卷积计算通过矩阵变换变换成矩阵乘法运算,详细可以参考一下这篇论文: https://hal.archives-ouvertes.fr/file/index/docid/112631/filename/p1038112283956.pdf。
下面是一张论文中的图片,看这张图片可以很清楚理解。从图中可以看出,卷积之前将输入的多个矩阵和多个卷积核先展开再组合成2个大的矩阵,用展开后的矩阵相乘。

3.1.3 快速计算方法代码待补充
3.2 反向传播代码
这里仅仅写出反向传播函数,之后有空再做一步一步分析。
def backward(self, residual):
N, C, H, W = self.bottom_val.shape
F, _, HH, WW = self.w.shape
stride, pad = self.stride, self.pad
H_out = int(1 + (H + 2 * pad - HH) / stride)
W_out = int(1 + (W + 2 * pad - WW) / stride)
x_pad = np.pad(self.bottom_val, ((0,), (0,), (pad,), (pad,)), mode='constant', constant_values=0)
dx = np.zeros_like(self.bottom_val)
dx_pad = np.zeros_like(x_pad)
dw = np.zeros_like(self.w)
# db = np.zeros_like(self.b)
db = np.sum(residual, axis=(0, 2, 3))
x_pad = np.pad(self.bottom_val, ((0,), (0,), (pad,), (pad,)), mode='constant', constant_values=0)
for i in range(H_out):
for j in range(W_out):
x_pad_masked = x_pad[:, :, i * stride:i * stride + HH, j * stride:j * stride + WW]
for k in range(F): # compute dw
dw[k, :, :, :] += np.sum(x_pad_masked * (residual[:, k, i, j])[:, None, None, None], axis=0)
for n in range(N): # compute dx_pad
temp_w = np.rot90(self.w,2,(2,3))#这种写法不旋转
dx_pad[n, :, i * stride:i * stride + HH, j * stride:j * stride + WW] += np.sum((temp_w[:, :, :, :] * (residual[n, :, i,j])[:, None, None, None]), axis=0)
dx[:,:,:,:] = dx_pad[:, :, pad:-pad, pad:-pad]
self.w -= self.lr * (dw + self.prev_gradient_w * self.reg)
self.b -= self.lr * db
self.prev_gradient_w = self.w
return dx














 1278
1278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









