







目录
文档链接:Python 正则表达式 | 菜鸟教程
一、概念
Regular Expression,正则表达式是一种对字符串进行匹配的语法规则。优点:速度快,效率高,准确性高。爬虫时用来提取页面内容数据。
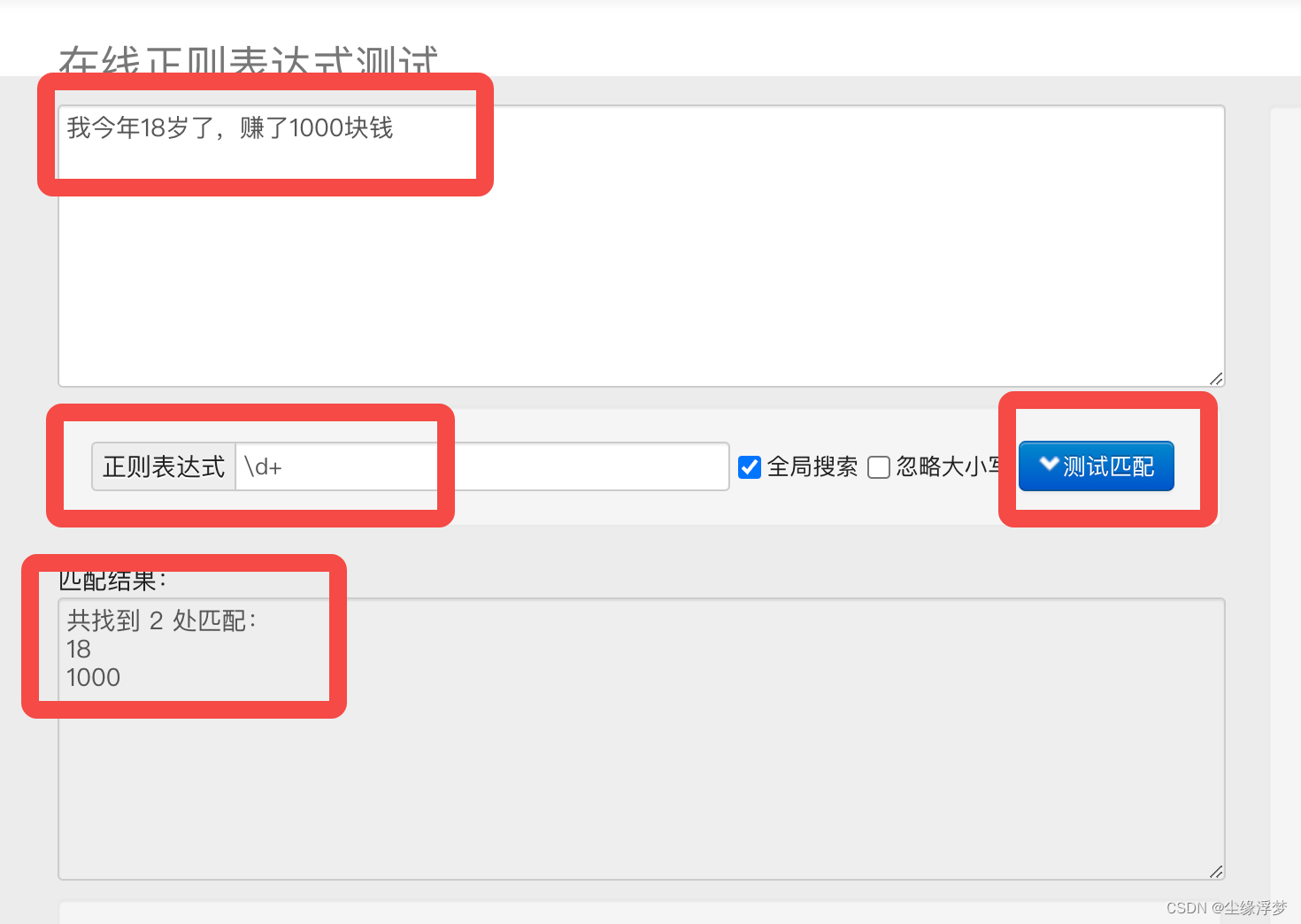
二、正则表达式工具
用来测试正则表达式是否正确
三、常用的正则表达式
贪婪匹配和惰性匹配
.* 贪婪匹配, 尽可能多的去匹配结果
.*? 惰性匹配, 尽可能少的去匹配结果 -> 回溯这两个要着重的说一下. 因为我们写爬虫用的最多的就是这个惰性匹 配
贪婪匹配:
"我们一起吃饭,我不饿我们不吃饭了"
reg: 我们.*吃饭
匹配结果:
共找到 1 处匹配:
我们一起吃饭,我不饿我们不吃饭惰性匹配
"我们一起吃饭,我不饿我们不吃饭了"
reg: 我们.*?吃饭
匹配结果:
共找到 2 处匹配:
我们一起吃饭
我们不吃饭四、re模块
import re
# result = re.findall("a", "我是一个abcdeafg")
# print(result)
# result = re.findall(r"\d+", "我今年18岁, 我有200000000块")
# print(result)
# # 这个是重点. 多多练习
# result = re.finditer(r"\d+", "我今年18岁, 我有200000000块")
# for item in result: # 从迭代器中拿到内容
# print(item.group()) # 从匹配到的结果中拿到数据
# search只会匹配到第一次匹配的内容
# result = re.search(r"\d+", "我叫周杰伦, 今年32岁, 我的班级是5年4班")
# print(result.group())
# # match, 在匹配的时候. 是从字符串的开头进行匹配的, 类似在正则前面加上了^
# result = re.match(r"\d+", "我叫周杰伦, 今年32岁, 我的班级是5年4班")
# print(result)
# # 预加载, 提前把正则对象加载完毕
# obj = re.compile(r"\d+")
# # 直接把加载好的正则进行使用
# result = obj.findall("我叫周杰伦, 今年32岁, 我的班级是5年4班")
# print(result)
# 想要提取数据必须用小括号括起来. 可以单独起名字
# (?P<名字>正则)
# 提取数据的时候. 需要group("名字")
s = """
<div class='西游记'><span id='10010'>中国联通</span></div>
<div class='西游记'><span id='10086'>中国移动</span></div>
"""
obj = re.compile(r"<span id='(?P<id>\d+)'>(?P<name>.*?)</span>")
result = obj.finditer(s)
for item in result:
id = item.group("id")
print(id)
name = item.group("name")
print(name)
五、爬虫案例
import re
import requests
import csv
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
#匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。re.S,使 . 匹配包括换行在内的所有字符
obj = re.compile(r'<div class="item">.*?<span class="title">(?P<title>.*?)</span>'
r'.*?<p class="">.*?导演: (?P<director>.*?) .*?<br>'
r'(?P<time>.*?) .*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
r'.*?<span>(?P<pingjia>.*?)人评价</span>', re.S)
for i in range(20):
start = i * 25
url = f'https://xxxxxxxxxxxxxx'
res = requests.get(url, headers=headers).text
result = obj.finditer(res)
for item in result:
row_list = []
title = item.group('title')
director = item.group('director').strip()
zhuyan = item.group('score')
pubtime = item.group('time').strip()
pingjia = item.group('pingjia')
row_list.append(title)
row_list.append(director)
row_list.append(zhuyan)
row_list.append(pubtime)
row_list.append(pingjia)
print(row_list)
# 将数据保存到csv
with open('data.csv', 'a', encoding='utf-8') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(row_list)
















 781
781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











