







-
动机
对于分类数据,不管是硬间隔最大化的线性可分 SVM,亦或是软间隔最大化的线性 SVM,得到的分离超平面都是线性的,他们对于那些线性或近似线性可分的数据分类时的效果是不错的,但是倘若出现非线性的数据,以上两种 SVM 就束手无策了。例如:

上图这种数据使用线性分类器如论如何也分不出最好的结果。此时我们希望可以得到非线性的分类超平面,例如:
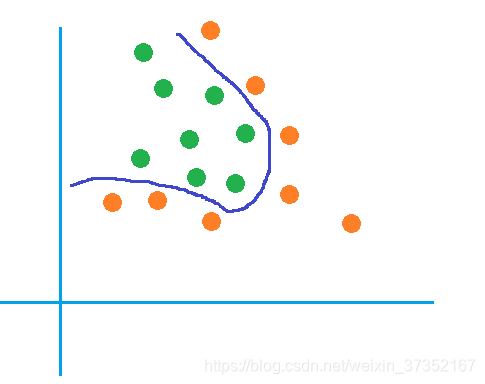
图中深蓝色的曲线就是我们希望得到的,它可以将图中的数据完美分开。但这样的曲线是如何得到的呢?请看下文。
-
核函数
讲核函数,就不得不讲维度这个概念。一幅山水画是二维空间(平面),而我们人类生活在三维空间中。为便于理解,我们使用二维空间与三维空间作为引例。
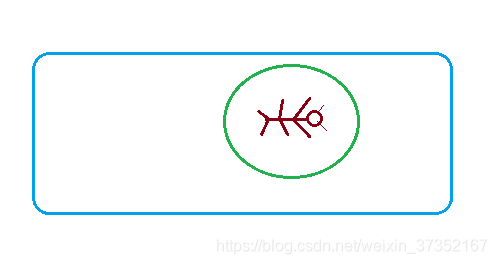
在图中,棕色图形表示的是一只在二维空间中的小虫子,就像一幅画中的生物一样。那么如果我们人类作为三维生物,用笔将它圈起来,那么这只二维的小虫子是无论如何也出不去的,但如果变成三维空间,这只小虫很轻松的就爬过了绿色的圆圈。
回到我们数据分类的场景中,假设样本点像图一数据一样,我们无论如何也不可能在二维空间中将他们分开,但是如果把数据维度升为三维,那么就轻而易举了。
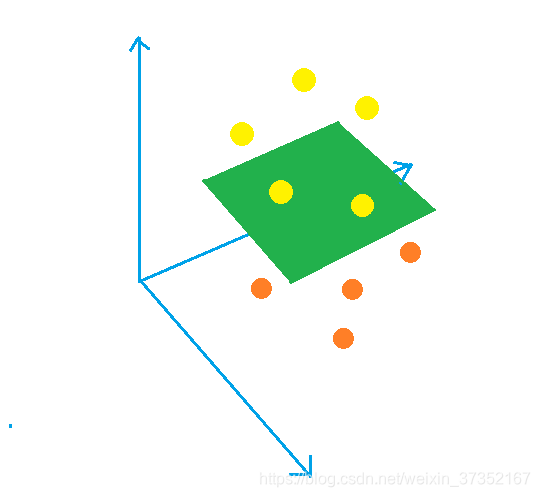
图中橘黄色样本都在绿色分离超平面下方,金黄色样本都在分离超平面上方。也许在二维平面中他们是混杂的,但是如果拍一下桌子,将这些样本震到空中,很有可能就产生了可分离的平面。了解了具体化的表述后,我们再来看看抽象的表述。
-
核技巧
是通过一个变换将原空间的数据映射到新空间的处理技巧,而后在新空间里使用线性分类学习方法从训练数据中学习分类模型。核技巧,是通过一个变换将原空间的数据映射到新空间的处理技巧,而后在新空间里使用线性分类学习方法从训练数据中学习分类模型。
-
核函数
设 X X X 为输入空间, H Η H为特征空间(希尔伯特空间),
若存在一个从 X X X 到 H Η H的映射:
Φ ( x ) : X → H Φ(x):X→Η Φ(x):X→H
使得所有函数 k ( x , z ) k(x,z) k(x,z),其中 x , z ∈ X x,z∈X x,z∈X ,满足条件:
k ( x , z ) = Φ ( x ) ⋅ Φ ( z ) k(x,z)=Φ(x)·Φ(z) k(x,z)=Φ(x)⋅Φ(z)
则称 k ( x , z ) k(x,z) k(x,z) 为核函数, Φ ( x ) Φ(x) Φ(x) 为映射函数,式中 Φ ( x ) ⋅ Φ ( z ) Φ(x)·Φ(z) Φ(x)⋅Φ(z) 为二者的内积。
-
特点
∙ \bullet ∙ 只定义核函数 k ( x , z ) k(x,z) k(x,z),而不显式地定义映射函数 Φ ( x ) Φ(x) Φ(x)。
∙ \bullet ∙ 通常直接计算 k ( x , z ) k(x,z) k(x,z) 比较容易,而计算 Φ ( x ) ⋅ Φ ( z ) Φ(x)·Φ(z) Φ(x)⋅Φ(z) 较难.
∙ \bullet ∙ Φ Φ Φ 是 X X X 到 H H H 的映射, H H H 一般为高维甚至无穷维。
-
举例
通俗来说, k ( x , z ) k(x,z) k(x,z) 相当于结果,而 Φ ( x ) ⋅ Φ ( z ) Φ(x)·Φ(z) Φ(x)⋅Φ(z) 相当于计算组合,这种计算组合有很多种。
实际上我们只需要得到 k ( x , z ) k(x,z) k(x,z) 这个结果就可以了,而不需要关注具体 Φ ( x ) Φ(x) Φ(x) 具体是怎样的一个函数。
例如:
我们取 k ( x , z ) = ( x ⋅ z ) 2 , x = ( x ( 1 ) , x ( 2 ) ) T , x = ( z ( 1 ) , z ( 2 ) ) T k(x,z)=(x·z)^2,x=(x^{(1)},x^{(2)})^T,x=(z^{(1)},z^{(2)})^T k(x,z)=(x⋅z)2,x=(x(1),x(2))T,x=(z(1),z(2))T
k ( x , z ) = ( x ⋅ z ) 2 = ( x ( 1 ) z ( 1 ) ) 2 + ( x ( 2 ) z ( 2 ) ) 2 + 2 x ( 1 ) z ( 1 ) x ( 2 ) z ( 2 ) k(x,z)=(x·z)^2=(x^{(1)}z^{(1)})^2+(x^{(2)}z^{(2)})^2+2x^{(1)}z^{(1)}x^{(2)}z^{(2)} k(x,z)=(x⋅z)2=(x(1)z(1))2+(x(2)z(2))2+2x(1)z(1)x(2)z(2)
为了能够得到 k ( x , z ) = ( x ⋅ z ) 2 k(x,z)=(x·z)^2 k(x,z)=(x⋅z)2 这样的核函数形式,实际上我们可以有很多种形式:
∙ \bullet ∙ Φ 1 ( x ) = ( ( x ( 1 ) ) 2 , 2 x ( 1 ) x ( 2 ) , ( x ( 2 ) ) 2 ) T Φ^1(x)=((x^{(1)})^2,\sqrt2x^{(1)}x^{(2)},(x^{(2)})^2)^T Φ1(x)=((x(1))2,2x(1)x(2),(x(2))2)T
∙ \bullet ∙ Φ 2 ( x ) = 1 2 ( ( x ( 1 ) ) 2 − ( x ( 2 ) ) 2 , 2 x ( 1 ) x ( 2 ) , ( x ( 1 ) ) 2 + ( x ( 2 ) ) 2 ) T Φ^2(x)=\frac{1}{\sqrt 2}((x^{(1)})^2-(x^{(2)})^2,2x^{(1)}x^{(2)},(x^{(1)})^2+(x^{(2)})^2)^T Φ2(x)=21((x(1))2−(x(2))2,2x(1)x(2),(x(1))2+(x(2))2)T
……
不关心中间 Φ ( x ) Φ(x) Φ(x) 函数的过程,只关注 k ( x , z ) k(x,z) k(x,z) 的最终计算形式,使得模型的学习相当于隐式的在高维特征空间中学习。
-
-
常用核函数
-
算法过程
加入了核函数的 SVM 的计算过程没有太大变化,直接将以前式子中的 ( x i ⋅ x j ) (x_i·x_j) (xi⋅xj) 内积改为 k ( x i ⋅ x j ) k(x_i·x_j) k(xi⋅xj) 即可:
-
求 w , b min L ( w , b , α ) \mathop{}_{w,b}^{\min} L(w,b,α) w,bminL(w,b,α) 对 α α α 的极大 α max w , b min L ( w , b , α ) \mathop{}_{α}^{\max}\mathop{}_{w,b}^{\min} L(w,b,α) αmaxw,bminL(w,b,α)
添 “负号”将求极大转化为求极小,得到,
α min 1 2 ∑ i = 1 M ∑ j = 1 M α i α j y i y j k ( x i ⋅ x j ) − ∑ i = 1 M α i \mathop{}_{α}^{\min} \frac{1}{2}\sum_{i=1}^{M}\sum_{j=1}^{M}α_iα_jy_iy_jk(x_i·x_j)-\sum_{i=1}^{M}α_i αmin21∑i=1M∑j=1Mαiαjyiyjk(xi⋅xj)−∑i=1Mαi
s . t . s.t. s.t. ∑ i = 1 M α i y i = 0 \sum_{i=1}^{M}α_iy_i=0 ∑i=1Mαiyi=0
α i ≥ 0 , i = 1 , 2 , . . . , M α_i\ge0,i=1,2,...,M αi≥0,i=1,2,...,M
-
求得最优解 α ∗ = ( α 1 , α 2 , . . . , α M ) T α^*=(α_1,α_2,...,α_M)^T α∗=(α1,α2,...,αM)T,根据 KKT 条件,
由此可得到 w ∗ = ∑ i = 1 M α i ∗ y i x i w^*=\sum_{i=1}^{M}α_i^*y_ix_i w∗=∑i=1Mαi∗yixi
又因 y j ( w ∗ x j + b ∗ ) − 1 = 0 y_j(w^*x_j+b^*)-1=0 yj(w∗xj+b∗)−1=0,且注意到 y j 2 = 1 y_j^2=1 yj2=1
可得到 b ∗ = y j − ∑ i = 1 M α i ∗ y i k ( x i ⋅ x j ) b^*=y_j-\sum_{i=1}^{M}α_i^*y_ik(x_i·x_j) b∗=yj−∑i=1Mαi∗yik(xi⋅xj)
-
最终
分离超平面可写成: ∑ i = 1 M α i ∗ y i k ( x ⋅ x j ) + b ∗ = 0 \sum_{i=1}^{M}α_i^*y_ik(x·x_j)+b^*=0 ∑i=1Mαi∗yik(x⋅xj)+b∗=0
分类决策函数可写成: f ( x ) = s i g n ( ∑ i = 1 M α i ∗ y i k ( x ⋅ x j ) + b ∗ ) f(x)=sign(\sum_{i=1}^{M}α_i^*y_ik(x·x_j)+b^*) f(x)=sign(∑i=1Mαi∗yik(x⋅xj)+b∗)
-















06-20
 1476
1476
1476
09-30
1723
1723
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









