







发展历史
深度学习当前非常火热,计算机的各个领域都想与深度学习挂钩。但实际上深度学习并不是最近的发明产物,最早可追溯到 1958 年的感知器。随着人类生活数据量的积累,以及近年硬件性能的不断提高,深度学习才得以又火一把。一起来看一下深度学习的起落兴衰。
— 1958 年:感知器的发明
感知器 在1958 年问世,它也被称为单层神经网络,尽管结构简单,却能解决很多复杂问题(在我看来感知器与 Logistic回归有异曲同工之妙)。
当时的感知器有着良好的发展前景,但 1969 年《Perceptrons》的出版称为了一个转折点。书中提出感知器的两个重要缺陷:无法处理亦或问题(XOR 映射);没有好方法将多层感知器训练的足够好。简而言之,要解决感知器无法解决线性不可分的问题,就要发展多层感知机,但现在没有能够训练多层感知机的有效方法。所以感知器被逐渐的不信任。
— 1986 年:BP算法重现江湖
反向传播算法(Back-Propagate)其实也同样很早就出现了,虽然有研究成果,但由于当时学术环境对神经网络的不信任,一直处于冰冻中。在 20 世纪 80 年代 LeCun Yann 在 Hinton 的实验室做博士后期间提出了神经网络反向传播算法的原型,而后 1986 年,Rumelhart、Hinton 以及 Williams 合著了《Learning representations by back-propagating errors》,BP 算法传播开来。
正当 BP 算法抬头,被热捧之时,LeCun Yann 的同事 Vapnik 发明了支持向量机(SVM),在同样可解决非线性问题的同时比神经网络有全方位的优势,因此SVM 迅速打败神经网络成为主流,神经网络再次沉沦。
— 2006 年:深度学习诞生
虽然神经网络堕入黑暗,Hinton 并未放弃,在 2006 年首次提出了深度置信网络。利用预训练以及微调优化技术大幅提升了模型的性能,神经网络东山再起,并且改头换面,以“深度学习”自居。
之后 Hinton 团队利用卷积神经网络以及微调优化技术“大杀四方”,干掉无数传统机器学习模型,深度学习开始垄断人工智能的新闻报道。
虽然深度学习的效果却是很好,但仍然有它的问题,例如黑盒模型,可解释性差等。 还是希望不要过度追捧,而是要从理论根本去创新、发展它。
从感知器到神经网络
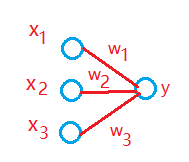
单层感知器,相当于 Logistic回归,能否表示异或运算呢?答案是,不能。
亦或运算表:
| X1 | X2 | Z |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Logistic 回归公式:
Z
=
σ
(
θ
1
X
1
+
θ
2
X
2
+
θ
0
)
Z=σ(θ_1X_1+θ_2X_2+θ_0)
Z=σ(θ1X1+θ2X2+θ0)

如图所示,面对二元的异或运算,是无法用一条线将数据完全分开,只能一种在线上,一种不在,但是当自变量增加时,则完全不可能了。所以需要多层感知器,即使用条线对数据进行划分。
如果强行使用单层来计算,则需要将所有的情况穷举,需要 2 n − 1 2^{n-1} 2n−1 个神经元。可想而知这样的神经元数量是指数级增长的。而如果使用多层,相当于每一层学一部分,后一层将前面的结果进行组合,如此大大降低了神经元的个数。
深度学习
深度学习解决的核心问题之一:自动将简单的特征组合成更加复杂的特征,并使用组合特征解决问题。“深度”是指神经网络的层数。
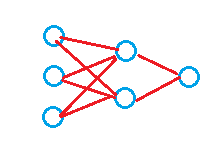
特点:
- 至少含有一个隐层的网络是一种普适近似,可以用来近似任何目标函数;
- 可以用来处理冗余特征,在权值训练过程中自动学习,冗余特征的权值会非常小;
- 对噪声比较敏感;
- 梯度下降算法经常会收敛到局部最小,可使用 SGD 或加入动量项(momentum term);
- 训练缓慢,预测快。
训练技巧
-
参数初始化
-
不能以全 0 初始化参数
考虑全连接的深度神经网络,同一层中的神经元的结构都是相同的,如果参数也相同则意味着每个神经元完全一样。那么前向与反向传播的取值都是一样的,学习将是对称的,同一层中的各个参数始终都是相同的。
-
随机生成小的随机数
-
标准初始化
初始化参数为取值范围 ( − 1 d , 1 d ) (-\frac{1}{\sqrt{d}},\frac{1}{\sqrt{d}}) (−d1,d1) 的均匀分布, d 是一个神经元接受的输入维度。
-
偏置初始化
可以设置为 0 或 较小的数,不会导致参数对称问题。
-
-
Dropout
Dropout 是指在训练中,以一定的概率临时随机让部分神经元关闭。例如:当值设置为 0.5,则意味着每次训练中将会有一半的神经元关闭,那么两次训练才会将所有神经元训练完成,相当于每次迭代都在训练不同结构的神经网络。
类比于 Bagging 方法,Dropout 可被视为神经网络的模型集成方法。
Dropout 中要给每一个神经元赋予一个概率系数,训练阶段中会以概率系数 P 随机生成一个取值为 0 或 1 的向量,代表每个神经元是否要丢弃。如果取值为 0 ,则该神经元不参与此次迭代。测试阶段则是前向计算,每个参数要乘以概率系数 P,以恢复神经元。
-
Batchnormalization(BN)
神经网络训练的本质是学习数据分布,如果训练数据与测试数据的分布不同将大大降低网络的泛化能力,因此我们需要在训练开始前对所有输入数进行归一化处理。
机器学习领域有个很重要的假设:IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。那BatchNorm的作用是什么呢?BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。
如果实例集合 <X,Y> 中的输入值 X 的分布总变,则不符合 IID假设,网络模型很难稳定的学规律。
详细介绍可见 Batchnormalization














 3006
3006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









