









强化学习算法已经有各种实现平台,譬如基于tensorflow的OpenAI Baselines,rllib,基于Pytorch的 PyTorch DRL ,rlpyt。最新推荐一个轻量快速实现的RL框架,由清华大学的本科生推出,相比于之前的RL平台,有一下几点优势:
实现简洁,轻巧:1500行代码搞定
模块化:多种不同API可供调用,轮子多就是好
调用方便,速度快,3秒钟实现一个PG算法
RL算法框架比较:
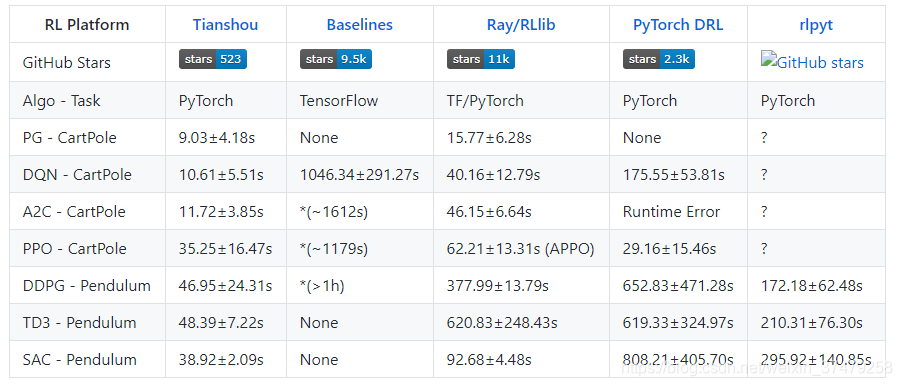
用天授实现DQN算法examples代码详情:
首先安装天授:
pip3 install tianshou
通过git同步安装最新版天授
pip3 install git+https://github.com/thu-ml/tianshou.git@master
查看安装成功与否
import tianshou as ts
print(ts.__version__)
下面摩拳擦掌在“天授”平台开始真正的DQN算法实战
代码实现解析如下:
1调用天授平台工具包
import gym, torch, numpy as np, torch.nn as nn
from torch.utils.tensorboard import SummaryWriter
import tianshou as ts
2定义参数
task = 'CartPole-v0'
lr = 1e-3
gamma = 0.9
n_step = 3
eps_train, eps_test = 0.1, 0.05
epoch = 10
step_per_epoch = 1000
collect_per_step = 10
target_freq = 320
batch_size = 64
train_num, test_num = 8, 100
buffer_size = 20000
writer = SummaryWriter('log/dqn') # tensorboard is also supported!
3环境设定
# you can also try with SubprocVectorEnv
train_envs = ts.env.VectorEnv([lambda: gym.make(task) for _ in range(train_num)])
test_envs = ts.env.VectorEnv([lambda: gym.make(task) for _ in range(test_num)])
4设计Net模型网络层/定义参数调优方式
class Net(nn.Module):
def __init__(self, state_shape, action_shape):
super().__init__()
self.model = nn.Sequential(*[
nn.Linear(np.prod(state_shape), 128), nn.ReLU(inplace=True),
nn.Linear(128, 128), nn.ReLU(inplace=True),
nn.Linear(128, 128), nn.ReLU(inplace=True),
nn.Linear(128, np.prod(action_shape))
])
def forward(self, s, state=None, info={}):
if not isinstance(s, torch.Tensor):
s = torch.tensor(s, dtype=torch.float)
batch = s.shape[0]
logits = self.model(s.view(batch, -1))
return logits, state
env = gym.make(task)
state_shape = env.observation_space.shape or env.observation_space.n
action_shape = env.action_space.shape or env.action_space.n
net = Net(state_shape, action_shape)
optim = torch.optim.Adam(net.parameters(), lr=lr)
5在Net网络层上实例化DQN策略并调用模型网络/同时调用训练和测试集
policy = ts.policy.DQNPolicy(net, optim, gamma, n_step,
use_target_network=True, target_update_freq=target_freq)
train_collector = ts.data.Collector(policy, train_envs, ts.data.ReplayBuffer(buffer_size))
test_collector = ts.data.Collector(policy, test_envs)
6训练模型
result = ts.trainer.offpolicy_trainer(
policy, train_collector, test_collector, epoch, step_per_epoch, collect_per_step,
test_num, batch_size, train_fn=lambda e: policy.set_eps(eps_train),
test_fn=lambda e: policy.set_eps(eps_test),
stop_fn=lambda x: x >= env.spec.reward_threshold, writer=writer, task=task)
print(f'Finished training! Use {result["duration"]}')
7保存/下载模型
torch.save(policy.state_dict(), 'dqn.pth')
policy.load_state_dict(torch.load('dqn.pth'))
8.查看结果
collector = ts.data.Collector(policy, env)
collector.collect(n_episode=1, render=1 / 35)
collector.close()
@misc{tianshou,
author = {Jiayi Weng, Minghao Zhang},
title = {Tianshou},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/thu-ml/tianshou}},
}
感兴趣的小伙伴们可以移步~~点击蓝字
强化学习框架 ——天授github地址(传送门)

关于作者~ AI工匠BOOK~
@欢迎关注AI工匠,给您:
不定期更新AI算法最新应用与前沿学习
分享简单易操作的AI入手项目
十分钟python敲出智能聊天机器人
CNN交通图像识别~视觉处理
TF2.0轻松上手教程系列
作者最新专栏——AI不难之深度学习算法实战代码解读:
算法工程师升级技能——轻松掌握TF2.0系列教程
1快速突击TF2.0核心知识技能点,运用TF高阶API构建自定义图像识别模型。
2从原理-网络模型设计-高阶API运用-深度学习分类模型实战算法代码-交通图像识别CNN模型TF2.0实战代码解析。
栏目内容一览:
1:如何用tf2.0自定义层网络的设计(add.weight)
2:tf2.0自定义模型的设计
3:tf2.0 loss函数和参数调优(gradient optimizer)
4:tf2.0 损失函数正则化
5:tf2.0基于高阶APIkeras构建深度学习模型
6.案例-tf2.0如何构建交通标识识别CNN
智能客服/图像识别/翻译系统是AI应用的热门方向之一,不管是外卖还是金融或者保险行业都已经有成熟的研发与应用。
本栏目将基于自然语言处理算法技术,由浅到深,涵盖NLP基本处理算法代码解读与前沿BERT解读,这是智能客服的基础层,应用层则从图文剖析-分层算法框架-实战代码解读。

















 426
426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











