





 本文展示了如何使用Tianshou库结合MARL训练井字棋游戏的智能体。训练过程中,作者添加了保存和加载模型的代码,利用pickle进行模型的序列化。训练完成后,智能体的模型被保存为pickle文件,但在尝试使用torch的`load_state_dict`方法加载模型时遇到问题。
本文展示了如何使用Tianshou库结合MARL训练井字棋游戏的智能体。训练过程中,作者添加了保存和加载模型的代码,利用pickle进行模型的序列化。训练完成后,智能体的模型被保存为pickle文件,但在尝试使用torch的`load_state_dict`方法加载模型时遇到问题。
原始代码:https://pettingzoo.farama.org/tutorials/tianshou/intermediate/
代码使用的PettingZoo游戏环境是井字棋(Tic Tac Toe)。
我在原始代码里加了保存模型的代码,以便训练结束后可以随时拿出来测试、可视化训练的成果(智能体的表现)。
训练的代码写在train.py,测试的代码(我额外写的)写在t_ttt.py。
train.py
# 用天授训练智能体
''''''
"""This is a minimal example of using Tianshou with MARL to train agents.
这是将天授与MARL一起用于训练智能体的一个最小示例。
Author: Will (https://github.com/WillDudley)
Python version used: 3.8.10
Requirements:
pettingzoo == 1.22.0
git+https://github.com/thu-ml/tianshou
"""
import os
from typing import Optional, Tuple
import gym
import numpy as np
import torch
from tianshou.data import Collector, VectorReplayBuffer
from tianshou.env import DummyVectorEnv
from tianshou.env.pettingzoo_env import PettingZooEnv
from tianshou.policy import BasePolicy, DQNPolicy, MultiAgentPolicyManager, RandomPolicy
from tianshou.trainer import offpolicy_trainer
from tianshou.utils.net.common import Net
from pettingzoo.classic import tictactoe_v3
import pickle # 我用pickle保存模型
def _get_agents(
agent_learn: Optional[BasePolicy] = None,
agent_opponent: Optional[BasePolicy] = None,
optim: Optional[torch.optim.Optimizer] = None,
) -> Tuple[BasePolicy, torch.optim.Optimizer, list]:
env = _get_env()
observation_space = (
env.observation_space["observation"]
if isinstance(env.observation_space, gym.spaces.Dict)
else env.observation_space
)
if agent_learn is None: # 这里的学习器默认用DQN算法。
# model
net = Net(
state_shape=observation_space["observation"].shape
or observation_space["observation"].n,
action_shape=env.action_space.shape or env.action_space.n,
hidden_sizes=[128, 128, 128, 128],
device="cuda" if torch.cuda.is_available() else "cpu",
).to("cuda" if torch.cuda.is_available() else "cpu")
if optim is None:
optim = torch.optim.Adam(net.parameters(), lr=1e-4)
agent_learn = DQNPolicy(
model=net,
optim=optim,
discount_factor=0.9,
estimation_step=3,
target_update_freq=320,
)
if agent_opponent is None: # 这里的对手默认用随机策略
agent_opponent = RandomPolicy()
agents = [agent_opponent, agent_learn] # 这里设置了2个智能体,第0号是对手,第1号是学习器。
policy = MultiAgentPolicyManager(agents, env)
return policy, optim, env.agents
def _get_env():
"""This function is needed to provide callables for DummyVectorEnv."""
'''此函数是为DummyVectorEnv提供可调用程序所必需的。'''
return PettingZooEnv(tictactoe_v3.env())
if __name__ == "__main__":
# ======== Step 1: Environment setup =========
# ======== 第一步:环境设置 =========
train_envs = DummyVectorEnv([_get_env for _ in range(10)]) # 训练的环境
test_envs = DummyVectorEnv([_get_env for _ in range(10)]) # 测试的环境
# seed
seed = 1
np.random.seed(seed)
torch.manual_seed(seed)
train_envs.seed(seed)
test_envs.seed(seed)
# ======== Step 2: Agent setup =========
# ======== 第二步:智能体设置 ========
policy, optim, agents = _get_agents()
# ======== Step 3: Collector setup =========
# ======== 第三步:采集器设置 ========
train_collector = Collector(
policy,
train_envs,
VectorReplayBuffer(20_000, len(train_envs)),
exploration_noise=True,
)
test_collector = Collector(policy, test_envs, exploration_noise=True)
# policy.set_eps(1)
train_collector.collect(n_step=64 * 10) # batch size * training_num
# ======== Step 4: Callback functions setup =========
# ======== 第四步:回调函数设置 ========
def save_best_fn(policy):
model_save_path = os.path.join("log", "rps", "dqn", "policy.pth")
os.makedirs(os.path.join("log", "rps", "dqn"), exist_ok=True)
torch.save(policy.policies[agents[1]].state_dict(), model_save_path)
def stop_fn(mean_rewards):
return mean_rewards >= 0.6
def train_fn(epoch, env_step):
policy.policies[agents[1]].set_eps(0.1)
def test_fn(epoch, env_step):
policy.policies[agents[1]].set_eps(0.05)
def reward_metric(rews):
return rews[:, 1]
# ======== Step 5: Run the trainer =========
# ======== 第五步:运行训练器 ========
result = offpolicy_trainer( # 这里使用了异策略的技巧
policy=policy,
train_collector=train_collector,
test_collector=test_collector,
max_epoch=50,
step_per_epoch=1000,
step_per_collect=50,
episode_per_test=10,
batch_size=64,
train_fn=train_fn,
test_fn=test_fn,
stop_fn=stop_fn,
save_best_fn=save_best_fn,
update_per_step=0.1,
test_in_train=False,
reward_metric=reward_metric,
)
# return result, policy.policies[agents[1]]
print(f"\n==========Result==========\n{result}")
print("\n(the trained policy can be accessed via policy.policies[agents[1]])")
# 训练好的策略可以通过policy.policies[agents[1]]访问(存取)
# 以下代码是我加上的:
# 保存模型参数:
torch.save(policy.policies[agents[1]].state_dict(), 'tictactoe_dqn.pth') # 这里仅保存了第1号智能体(学习器)
t_ttt.py
# 把训练好的智能体拿来测试
# 'tictactoe_dqn.pth'
#import torch
import tianshou as ts
from pettingzoo.classic import tictactoe_v3
import pickle
env=tictactoe_v3.env(render_mode="human")
env = ts.env.PettingZooEnv(env)
device="cuda" if torch.cuda.is_available() else "cpu"
net = Net(
state_shape=env.observation_space["observation"].shape
or env.observation_space["observation"].n,
action_shape=env.action_space.shape or env.action_space.n,
hidden_sizes=[128, 128, 128, 128],
device=device,
).to(device)
optim = torch.optim.Adam(net.parameters(), lr=1e-4)
p1=DQNPolicy(
model=net,
optim=optim,
discount_factor=0.9,
estimation_step=3,
target_update_freq=320,
)
#加载模型参数
p1.load_state_dict(torch.load('tictactoe_dqn.pth'))
p2=ts.policy.RandomPolicy()
po=ts.policy.MultiAgentPolicyManager([p1, p2], env)
env = ts.env.DummyVectorEnv([lambda: env])
collector = ts.data.Collector(po, env)
result = collector.collect(n_episode=1, render=0.2)
print(result)
输出如下(截图不完全):
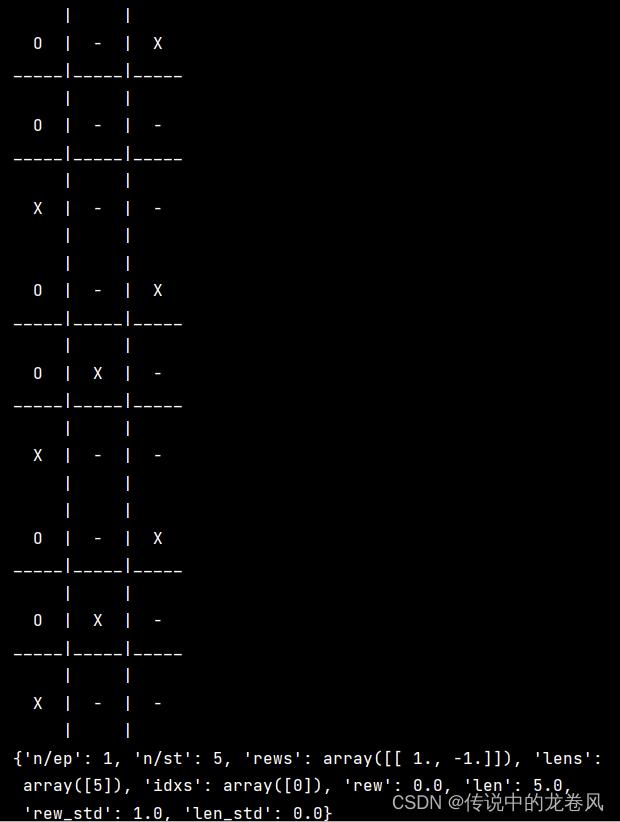
目前我遇到的问题是:使用Tianshou的方法【policy.load_state_dict(torch.load(‘tictactoe_dqn.pth’))】加载模型不行,总是提示没有这个函数。所以我仍然使用pickle来保存和加载模型。

















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









