






论文解读《Uncertainty-Guided Mutual Consistency Learning for Semi-Supervised Medical Image Segmentation》
论文出处:Artificial Intelligence in Medicine(AIIM)
论文地址:论文地址
代码地址:代码地址
一、 摘要:
(1) 现有的方法不能充分利用未标记数据的区域级形状约束和边界级距离信息。
(2) 提出了一种新的不确定性引导的相互一致性学习框架,以及来自任务级正则化的跨任务一致性学习来开发几何形状信息。
(3) 对两个公开基准数据集的实验表明:1)与监督基线相比,在左心房分割和脑肿瘤分割上的Dicecoefficient分别高达4.13%和9.82%。2)与其他半监督分割方法相比,在相同的骨干网和任务设置下,我们提出的方法在两个数据集上实现了更好的分割性能。
二、引言
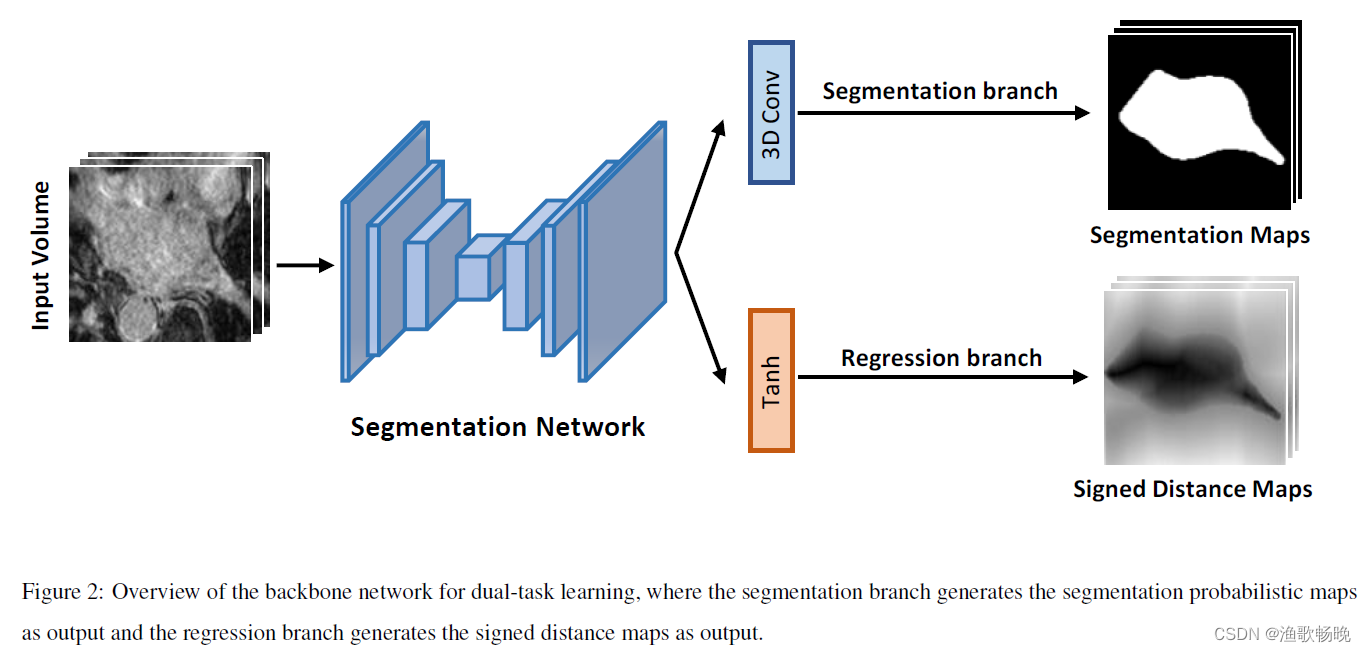
(1) 我们提出了一种新的不确定性引导的相互一致性学习框架。使用带有两个输出分支的双任务骨干网同时生成分割概率图和符号距离图。
(2) 此外,我们提出的框架以模型估计的分割不确定性为指导,选择出相对确定的预测进行一致性学习,从而有效地从未标记的数据中挖掘出更可靠的信息。左心房分割(LA)和脑肿瘤分割(BraTS)。实验结果表明,框架可以通过利用无标签图像大大提高分割性能,并优于最先进的半监督分割方法。
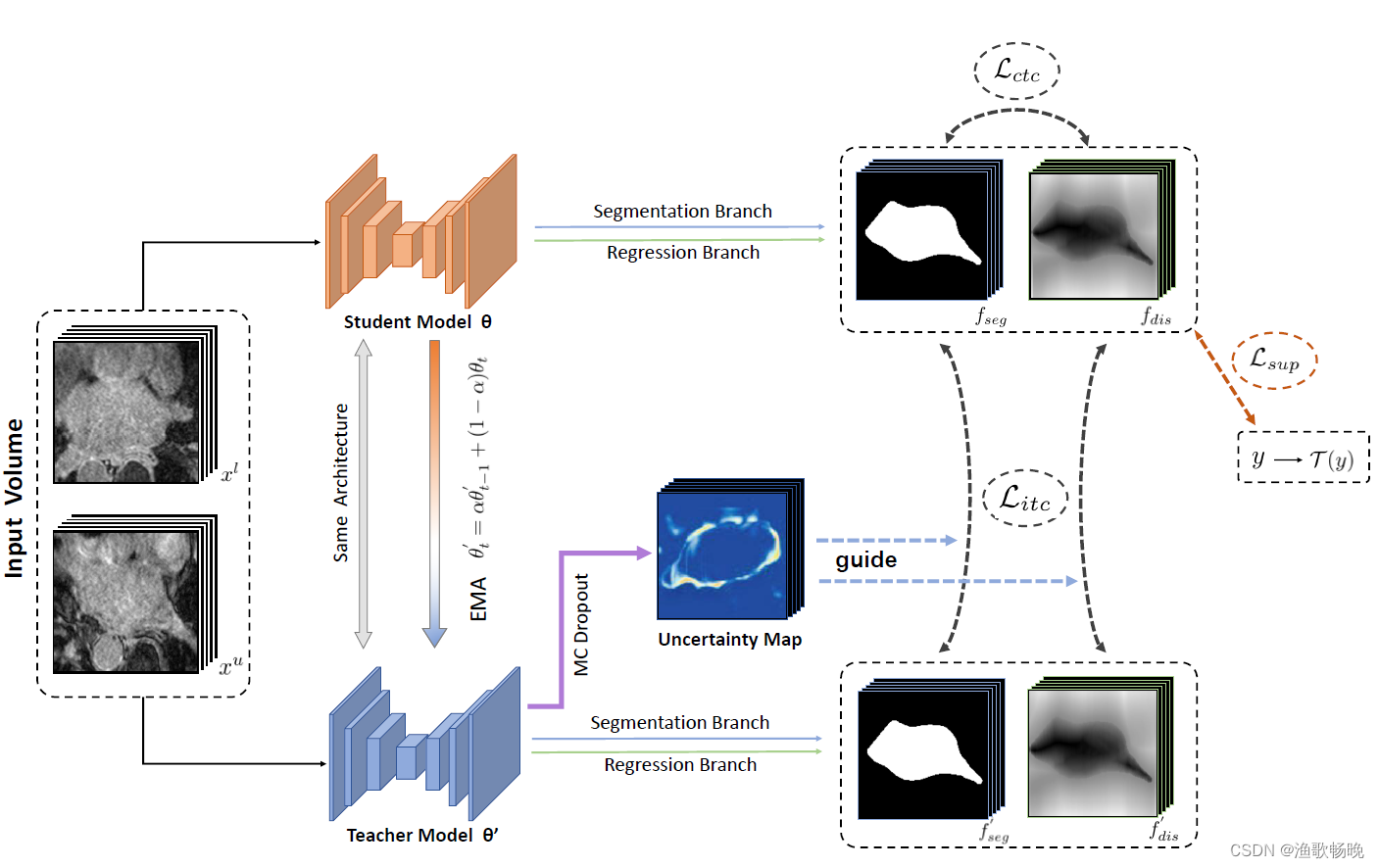
图1:我们提出的半监督医学图像分割的不确定性引导相互一致性学习框架的概述。骨干网络由两个不同的分支组成,用于不同的任务,其中第一个分支的目标是按像素分类并生成分割概率图作为输出,第二个分支的目标是水平集函数回归并回归有符号的距离图。根据平均教师框架的设计,通过最小化标记数据Dz的监督损失和标记数据D和未标记数据Du的跨任务一致性损失来优化学生模型。利用教师模型中估计的不确定性来指导学生模型的学习,从而从无标记数据中学习到更可靠的信息,进行半监督学习。
三、方法
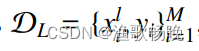
,将有N个无标记情况的未标记集表示为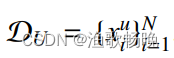
,其中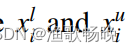
表示输入图像,yi表示标记数据对应的ground truth。
3.1 骨干网络架构与监督学习
符号距离函数(SDF)最近与分割cnn结合。具体来说,我们引入符号距离映射T(x)的变换如下:
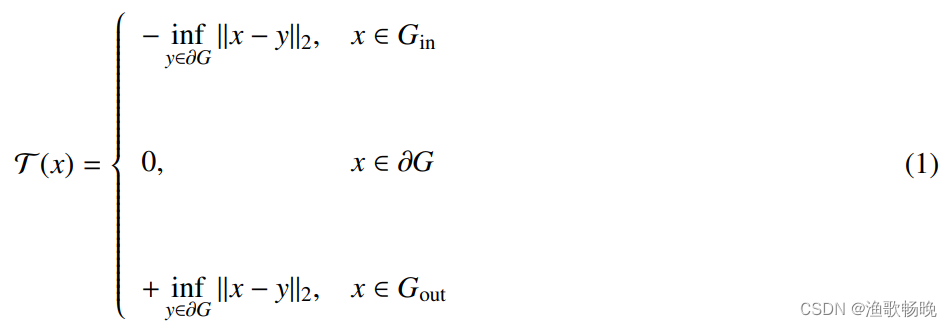
其中Ilx-yllz为体素x和y之间的欧氏距离。
分别表示分割目标的内部、边界和外部。
符号距离函数(sign distancefunction):简称SDF,又可以称为定向距离函数(oriented distance function),在空间中的一个有限区域上确定一个点到区域边界的距离并同时对距离的符号进行定义:点在区域边界内部为正,外部为负,位于边界上时为0。
conv1 = self.conv1(inputs)
maxpool1 = self.maxpool1(conv1)
conv2 = self.conv2(maxpool1)
maxpool2 = self.maxpool2(conv2)
conv3 = self.conv3(maxpool2)
maxpool3 = self.maxpool3(conv3)
conv4 = self.conv4(maxpool3)
maxpool4 = self.maxpool4(conv4)
center = self.center(maxpool4)
center = self.dropout1(center)
up4 = self.up_concat4(conv4, center)
up3 = self.up_concat3(conv3, up4)
up2 = self.up_concat2(conv2, up3)
up1 = self.up_concat1(conv1, up2)
up1 = self.dropout2(up1)
final = self.final(up1)##self.final = nn.Conv3d(filters[0], n_classes, 1)
dis = self.tanh(final)##self.tanh = nn.Tanh()
return dis,final
监督分割损失定义为:
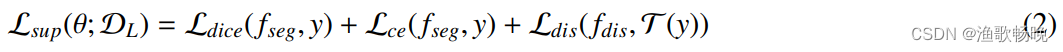
outdis, outputs = model(volume_batch)
loss_seg = F.cross_entropy(outputs[:labeled_bs], label_batch[:labeled_bs])
outputs_soft = F.softmax(outputs, dim=1)
loss_seg_dice = losses.dice_loss(outputs_soft[:labeled_bs, 1, :, :, :], label_batch[:labeled_bs] == 1)
dis_to_mask = torch.sigmoid(-1500*outdis)
loss_dis_dice = losses.dice_loss(dis_to_mask[:labeled_bs, 1, :, :, :], label_batch[:labeled_bs] == 1)
loss = 0.5 * (loss_seg+loss_seg_dice+loss_dis_dice)
其中fseg和fdis分别表示分割分支和回归分支的输出预测。
3.2. 任务内一致性规则化
根据[17]中的设计,我们通过对教师模型在随机退出下执行T次随机正向传递,对蒙特卡罗Dropout[48]的不确定性进行估计。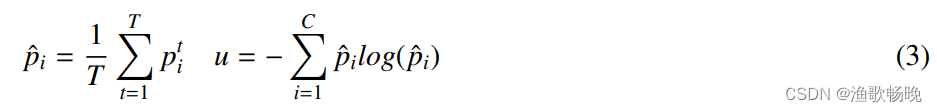
其中p’是第i类在正向传递中第th次的预测对数,C是分割任务中的类数,p =教师模型中T次随机传递的平均软最大概率,u是估计的分割不确定性。
因此,任务内一致性损失的定义如下:
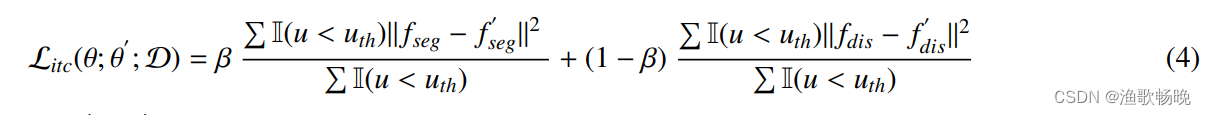
I(-)为选择出相对确定预测的指标函数,ß为分割任务与回归任务一致性学习的平衡权重。其中(Fseg,Fdis)和(F‘seg,F’dis)分别表示学生模型和教师模型的分割分支和回归分支的输出。
with torch.no_grad():
ema_dis, ema_output = ema_model(ema_inputs)
consistency_dist = 0.5 * consistency_criterion(outputs, ema_output)+ 0.5 * consistency_criterion(outdis, ema_dis)
###############################
threshold = (0.75+0.25*ramps.sigmoid_rampup(iter_num, max_iterations))*np.log(2)
mask = (uncertainty<threshold).float()
consistency_dist = 0.5 * torch.sum(mask*consistency_dist)/(2*torch.sum(mask)+1e-16)
consistency_loss = consistency_weight * consistency_dist

3.3. 跨任务一致性正则化
对分割分支和回归分支输出之间的跨任务一致性进行了正则化,以进一步利用未标记数据。
为了将距离映射的输出转换回二进制分割输出,我们利用[21,22]中对逆变换的平滑近似,它可以定义为

其中z是体素x上有符号距离映射的值,k是选择尽可能大的变换因子来近似变换。
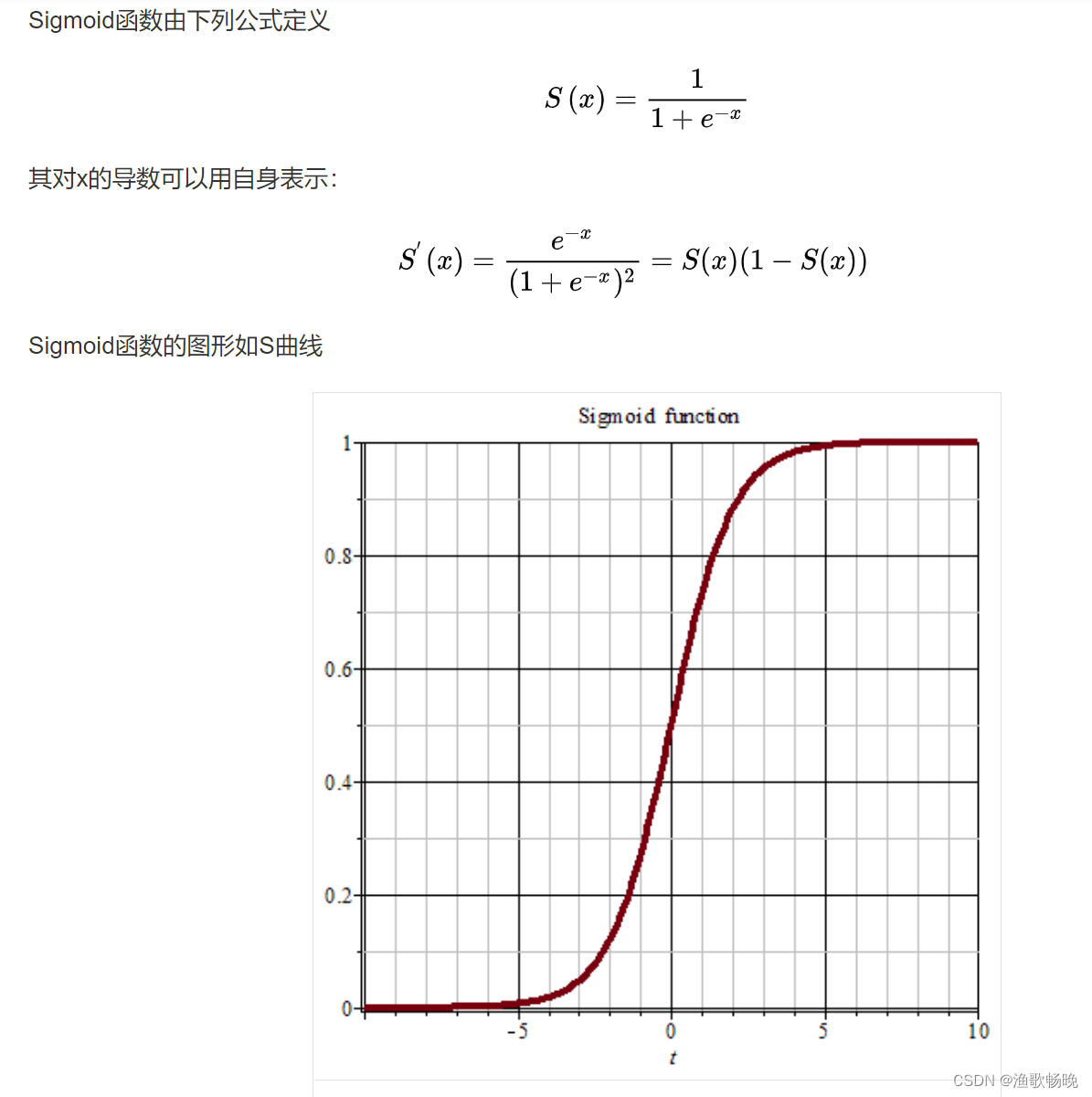
因此,半监督学习的跨任务一致性损失可以定义为:

outdis, outputs = model(volume_batch)
dis_to_mask = torch.sigmoid(-1500*outdis)
cross_task_dist = torch.mean((dis_to_mask - outputs_soft) ** 2)
cross_task_loss = consistency_weight * cross_task_dist
3.4整体训练过程
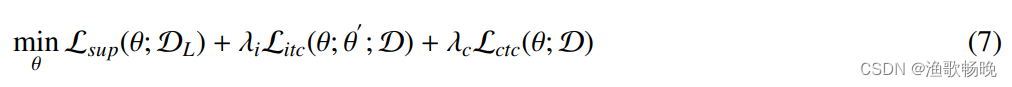
其中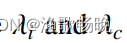
是控制有监督损失和无监督损失之间权衡的斜坡加权系数,以减轻早期训练阶段一致性损失的干扰。
loss = 0.5 * (loss_seg+loss_seg_dice+loss_dis_dice) + consistency_loss + cross_task_loss
3.5 消融实验
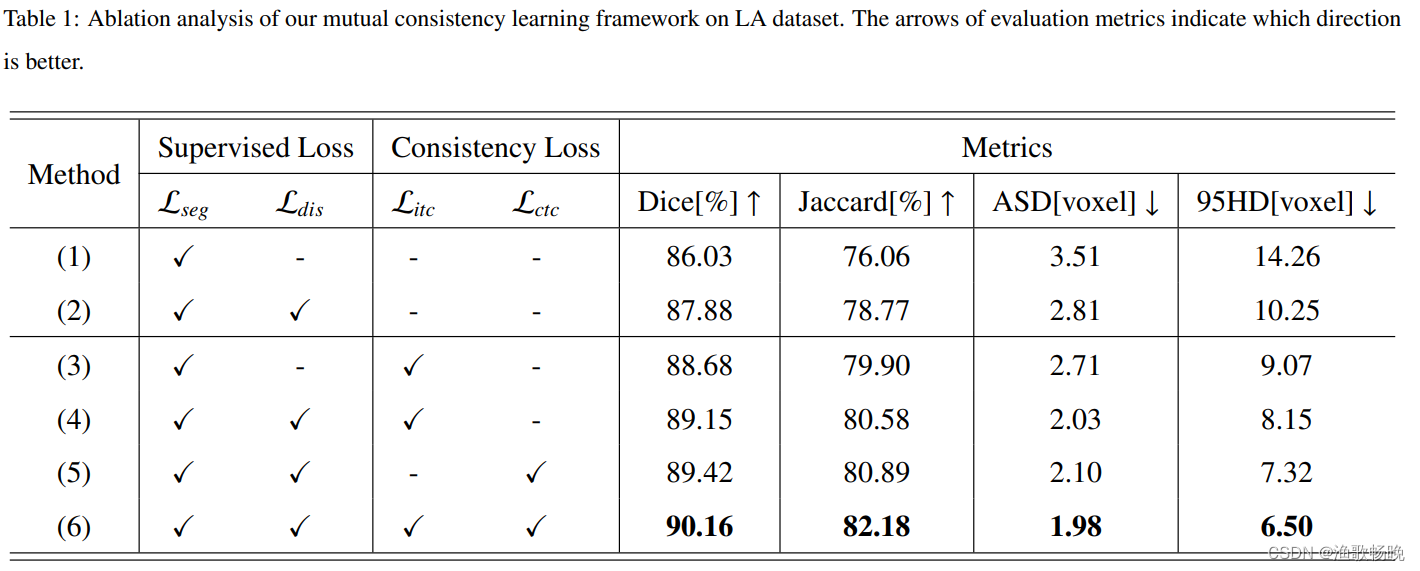
烧蚀实验测试结果见表1。
实验 (1)和(2) 是用标记数据训练的V-Net的监督基线。
在实验 (3) 中,只激活经典的分割分支进行一致性学习,而去除了回归分支。
在实验 (4) 中,利用基于变换后的标准距离图的监督对训练进行正则化。在距离上添加监督,进一步提高了Dice的分割0.47%和Jaccard的0.68%。
在实验 (5) 中,去除师生框架的任务内一致性学习后,模型只有跨任务一致性学习。
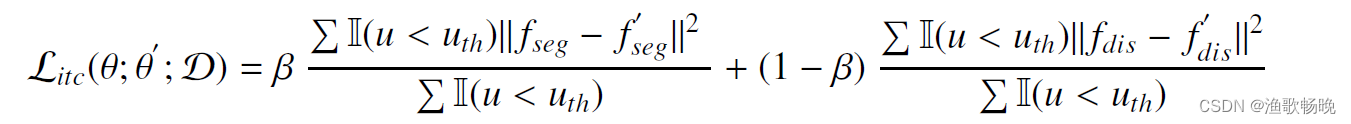
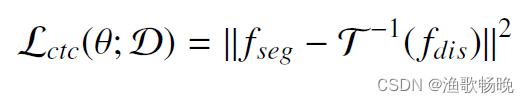
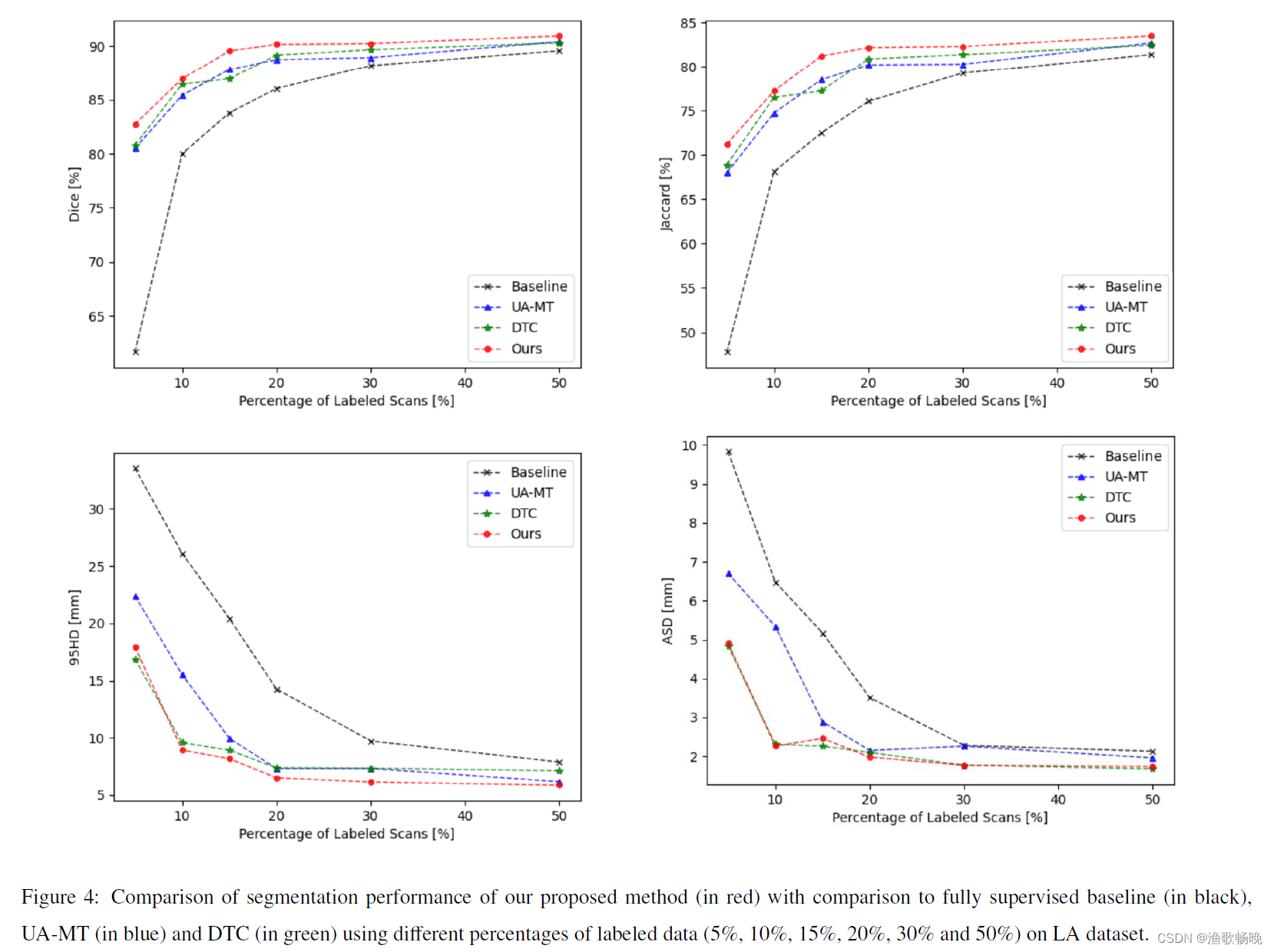
3.6. 使用不同百分比的标记数据的性能
使用LA数据集中不同百分比的标记数据进行了实验。分割结果的可视化如 图4 所示。
3.7 在LA数据集上与其他半监督分割方法的比较实验
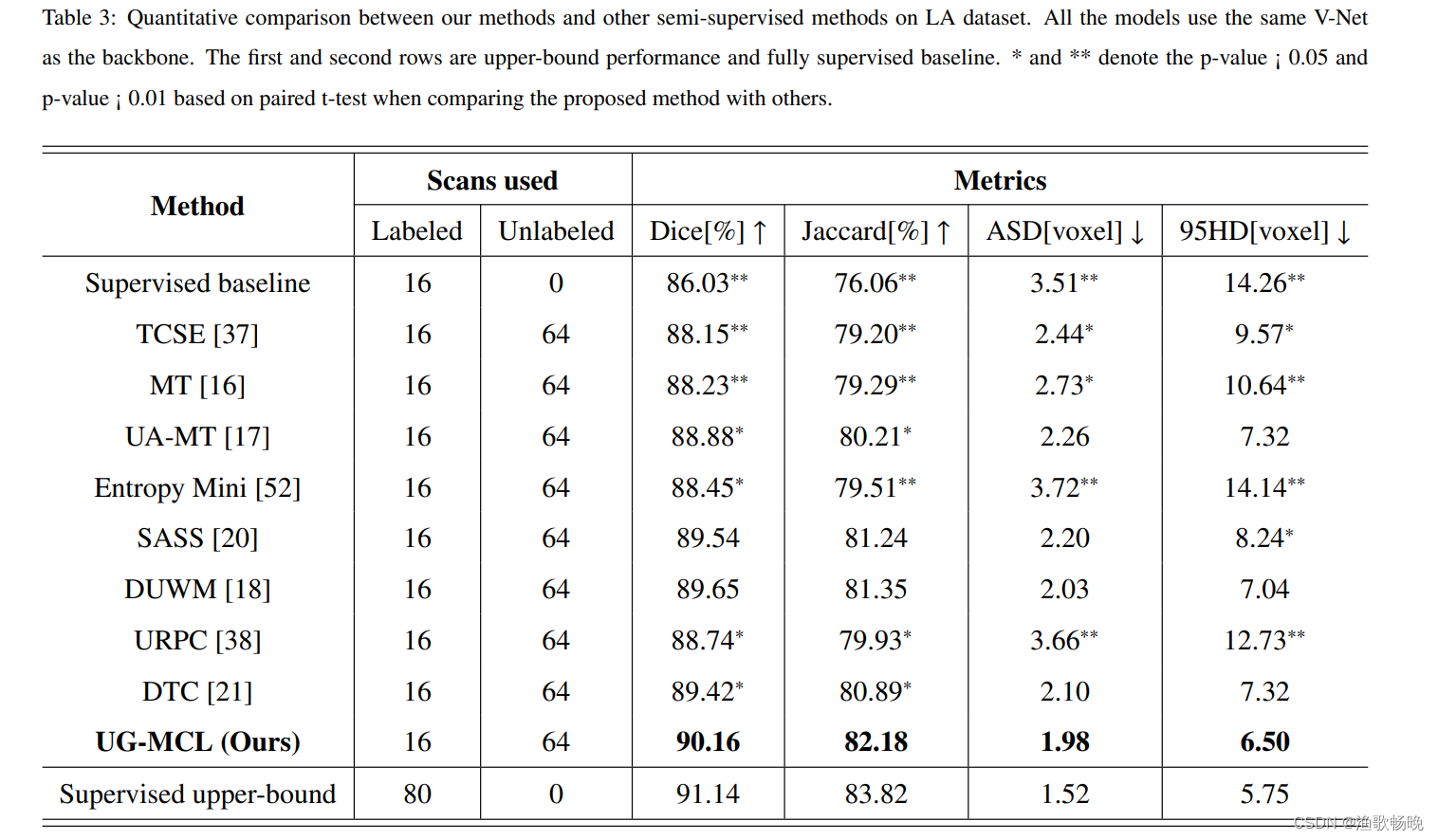
表3显示了LA数据集上的定量结果。作为对比,我们也在全监督设置下进行V-Net实验,以20%和所有标记数据作为任务的下界和上界参考。提出的方法可以实现Dice的86.03%至90.16%和Jaccard的76.06%至82.18%的显著性能提升。同时,我们的方法在Dice中获得了90.16%的可比性结果,与91.14%的上限性能相比,并且在所有四个评价指标上都显著优于其他半监督分割方法。
四、结论
在本文中,提出了一种新的不确定性引导的相互一致性学习框架,用于半监督医学图像分割。我们使用双任务骨干网和两个输出分支同时生成分割概率图和符号距离图。















 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









