









1.倒排索引的建立:
需求:有大量的文本(文档、网页),需要建立搜索索引
计算每个单词在每个文件的出现次数并且将他们排序
创建好输入的文件:
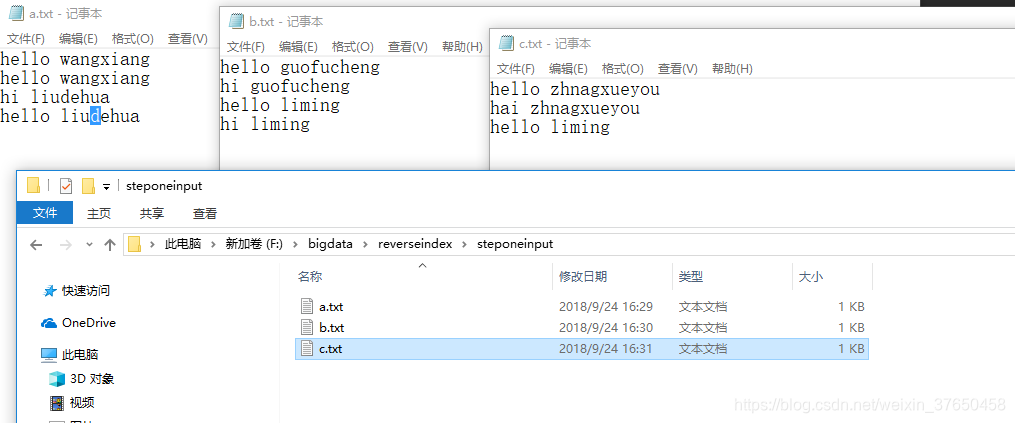
思路:一行一行的读,拿到单词,并且拿到文件名字,将单词和文件名字合并在一起作为key输出,然后在reduce端统计即可
第一次输出的结果:
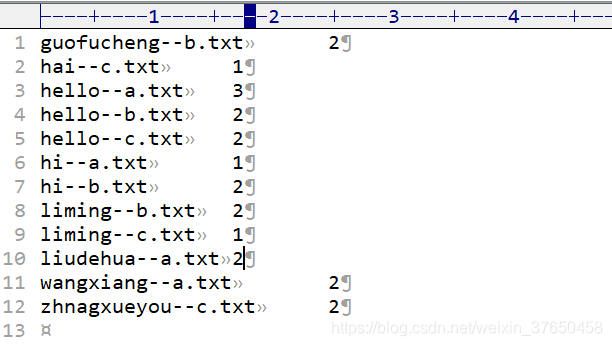
第二次的输出结果:

代码:
package com.wx.mapreduce5;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ReverseIndexOne {
/*
* 倒排索引例子,计算每个单词在每个文件的出现次数并且将他们排序
*/
static class ReverseIndexOneMapper extends Mapper<LongWritable, Text, Text, IntWritable>
{
Text k=new Text();
IntWritable v=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(" ");//shift+alt+L
//拿到文件名字
FileSplit inputSplit = (FileSplit) context.getInputSplit();
String name = inputSplit.getPath().getName();
//拼接key,key是单词和文件名的合体
for(String word: split)
{
k.set(word+"--"+name);
context.write(k, v);
}
}
}
/*
* 输入:<hello--a.txt,1> <hello--a.txt,1> <hello--a.txt,1> <hello--b.txt,1> <hello--b.txt,1>
* 输出:<hello--a.txt,3> <hello--b.txt,2>
*/
static class ReverseIndexOneReduce extends Reducer<Text, IntWritable, Text, IntWritable>
{
IntWritable v=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
int count=0;
for(IntWritable val:values)
{
count+=val.get();
v.set(count);
}
context.write(key, v);
}
}
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(ReverseIndexOne.class);
//设置执行map的类以及输出的数据的类型
job.setMapperClass(ReverseIndexOneMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//执行reduce的类以及最终输出结果
job.setReducerClass(ReverseIndexOneReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置读取处理文件的路径
FileInputFormat.setInputPaths(job, new Path("F:/bigdata/reverseindex/steponeinput"));
FileOutputFormat.setOutputPath(job, new Path("F:/bigdata/reverseindex/steponeoutput1"));
//指定一个文件需要缓存到maptask的工作目录
//job.addArchiveToClassPath(archive);//缓存jar包到maptask运行节点的classpath中
//job.addFileToClassPath(file);//缓存普通文件到maptask的运行节点的calsspath中
//job.addCacheArchive(uri);//缓存压缩包文件到calsspath中
//job.addCacheFile(new URI("file:/F:/wordcount/mapjoincache/pds.txt"));//将产品表的产品文件缓存到task的工作目录中去
//设置不需要reduce
//job.setNumReduceTasks(0);
boolean re = job.waitForCompletion(true);
System.exit(re?0:1);
}
}
package com.wx.mapreduce5;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ReverseIndexTwo {
/* 把步骤一处理好的数据如下,进行拼接
* guofucheng--b.txt 1
guofucheng--b.txt 2
hai--c.txt 1
hello--a.txt 1
hello--a.txt 2
*/
static class ReverseIndexTwoMapper extends Mapper<LongWritable, Text, Text, Text>
{
Text k=new Text();
Text v=new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] split = value.toString().split("--");
k.set(split[0]);
v.set(split[1]);
context.write(k, v);
}
}
//<guofucheng,b.txt 1> <guofucheng,b.txt 2>
static class ReverseIndexTwoReduce extends Reducer<Text, Text, Text, Text>
{
Text k=new Text();
Text v=new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
String str="";
for(Text value:values)//把value拼接起来即可
{
str+=value;
v.set(str);
}
k.set(key);
context.write(k,v);
}
}
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(ReverseIndexTwo.class);
//设置执行map的类以及输出的数据的类型
job.setMapperClass(ReverseIndexTwoMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//执行reduce的类以及最终输出结果
job.setReducerClass(ReverseIndexTwoReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置读取处理文件的路径
FileInputFormat.setInputPaths(job, new Path("F:/bigdata/reverseindex/steponeoutput1"));
FileOutputFormat.setOutputPath(job, new Path("F:/bigdata/reverseindex/steponeoutput2"));
//指定一个文件需要缓存到maptask的工作目录
//job.addArchiveToClassPath(archive);//缓存jar包到maptask运行节点的classpath中
//job.addFileToClassPath(file);//缓存普通文件到maptask的运行节点的calsspath中
//job.addCacheArchive(uri);//缓存压缩包文件到calsspath中
//job.addCacheFile(new URI("file:/F:/wordcount/mapjoincache/pds.txt"));//将产品表的产品文件缓存到task的工作目录中去
//设置不需要reduce
//job.setNumReduceTasks(0);
boolean re = job.waitForCompletion(true);
System.exit(re?0:1);
}
}
2.有如下订单数据,现在需要求出每一个订单中成交金额最大的一笔交易

1、利用“订单id和成交金额”作为key,可以将map阶段读取到的所有订单数据按照id分区,按照金额排序,发送到reduce
2、在reduce端利用groupingcomparator将订单id相同的kv聚合成组,然后取第一个即是最大值
经过map处理过后利用partitioner按照订单id分区,所有的id相同的订单bean分在一起,并且按钱的大小排好了顺序,但是要保证对象进入同一个reduce还需要WritableComparator将分在一个的bean安排竟日同一个reduce,依据就是把key本来是比对象进入reduce,现在把他按比id进入reduce,这样他们就会按照相同的订单号进入同一个reduce,并且已经是排好序的,直接输出最大即可。
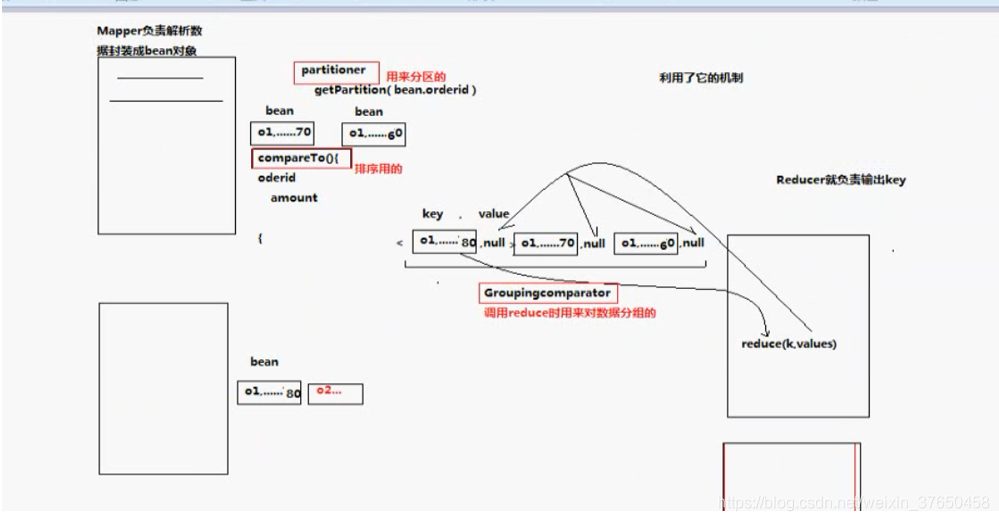
第一种分区HashPartitioner:
HashPartitioner的分区数=k.hashcode%numReduceTasks 而numReduceTasks 是用户自己设定的,job.setnumReduceTasks(5) ,比如设为5,那么k.hashcode模5的结果就可能是0,1,2,3,4所以共五个分区。
第二种分区,ProvincePartitioner:
比如说事先定义了六个省,那么就一定会有6个分析,numReduceTasksde 的数量就不能不设,不能瞎设,必须要给前面的对的上
准备输入数据: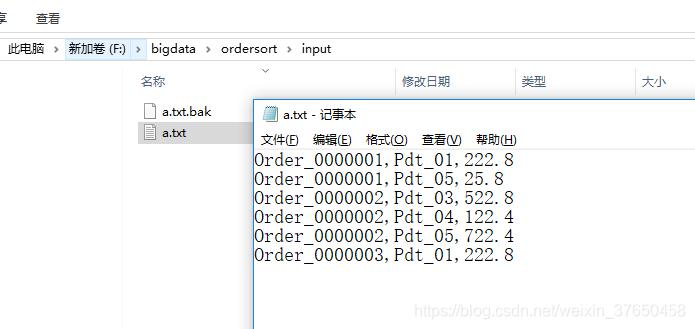
输出的结果: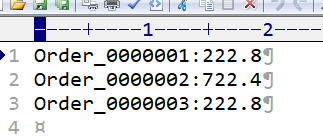
代码:
package com.wx.mapreduce7;
import java.io.IOException;
import org.apache.avro.Schema.Field.Order;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class OrderSort {
/*
* 读入一行数据Order_0000001 Pdt_01 222.8
* 输出<bran,null>,经过分区排序的
* <Order_0000001 222.8,null><Order_0000001 100,null><Order_0000002 100,null>
*/
static class OrderSortMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable>
{
OrderBean k=new OrderBean();
Text itemid=new Text();
DoubleWritable price=new DoubleWritable();
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
itemid.set(split[0]);
k.setItemid(itemid);
price.set(Double.parseDouble(split[2]));
k.setPrice(price);
context.write(k, NullWritable.get());
}
}
/*
*
*/
static class OrderSortReduce extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable>
{
@Override
protected void reduce(OrderBean bean, Iterable<NullWritable> value,Context context)
throws IOException, InterruptedException {
context.write(bean, NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf=new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(OrderSort.class);
job.setMapperClass(OrderSortMapper.class);
job.setReducerClass(OrderSortReduce.class);
//map的输出数据类型
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
//指定最终输出数据的类型
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
//指定文件输入路径
FileInputFormat.setInputPaths(job, new Path("F:/bigdata/ordersort/input"));
FileOutputFormat.setOutputPath(job, new Path("F:/bigdata/ordersort/output"));
//在此设置自定义的Groupingcomparator类
job.setGroupingComparatorClass(ItemidGroupingComparator.class);
//在此设置自定义的partitioner类
job.setPartitionerClass(ItemIdPartitioner.class);
job.setNumReduceTasks(1);
job.waitForCompletion(true);
}
}
package com.wx.mapreduce6;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
public class OrderBean implements WritableComparable<OrderBean> {
private Text itemid;
private DoubleWritable price;
//分区会调反射的方法
public OrderBean()
{
}
public OrderBean(Text itemid,DoubleWritable price)
{
this.itemid=itemid;
this.price=price;
}
public Text getItemid() {
return itemid;
}
public void setItemid(Text itemid) {
this.itemid = itemid;
}
public DoubleWritable getPrice() {
return price;
}
public void setPrice(DoubleWritable price) {
this.price = price;
}
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
this.itemid=new Text(in.readUTF());
this.price=new DoubleWritable(in.readDouble());
}
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeUTF(itemid.toString());
out.writeDouble(price.get());
}
public int compareTo(OrderBean o) {
//比较订单号,如果订单号相同,则按价钱倒序排序出来,如果不同,返回1就是按订单号正序排序
int com = this.itemid.compareTo(o.getItemid());
if(com==0)
{
com=-this.price.compareTo(o.getPrice());
}
return com;
}
@Override
public String toString() {
// TODO Auto-generated method stub
return itemid.toString()+":"+price.get();
}
}package com.wx.mapreduce6;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class ItemIdPartitioner extends Partitioner<OrderBean, NullWritable> {
@Override
public int getPartition(OrderBean bean, NullWritable value, int numReduceTasks) {
// TODO Auto-generated method stub
//相同id的订单bean,会发往相同的partition
//而且,产生的分区数,是会跟用户设置的reduce task数保持一致
return (bean.getItemid().hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
package com.wx.mapreduce6;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class ItemidGroupingComparator extends WritableComparator {
/*
* 利用reduce端的GroupingComparator来实现将一组bean看成相同的key
* 因为bean是一个对象如果直接传到reduce,那个每个对象就是不同的,所以用该类
*
*/
//传入作为key的bean的class类型,以及制定需要让框架做反射获取实例对象
protected ItemidGroupingComparator() {
super(OrderBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
// TODO Auto-generated method stub
OrderBean abean = (OrderBean) a;
OrderBean bbean = (OrderBean) b;
//比较两个bean时,指定只比较bean中的orderid
return abean.getItemid().compareTo(bbean.getItemid());
}
}
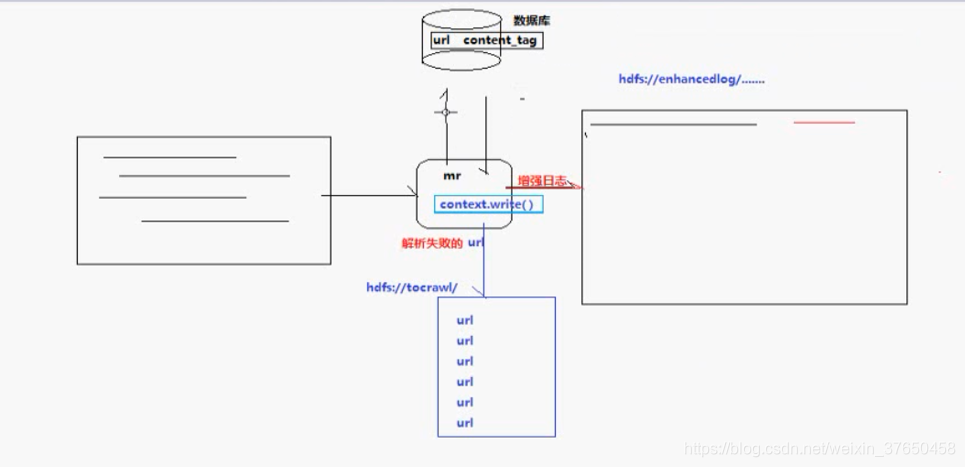
3.日志清洗:运营商流量日志增强
现有一些原始日志需要做增强解析处理,流程:
- 从原始日志文件中读取数据
- 根据日志中的一个URL字段到外部知识库中获取信息增强到原始日志
- 如果成功增强,则输出到增强结果目录;如果增强失败,则抽取原始数据中URL字段输出到待爬清单目录















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











