







契机
单纯用一个embedding表示用户的兴趣爱好,效果会很差,因而需要用多个embedding来共同表示用户的兴趣爱好。
模型结构
模型的核心结构如下所示:
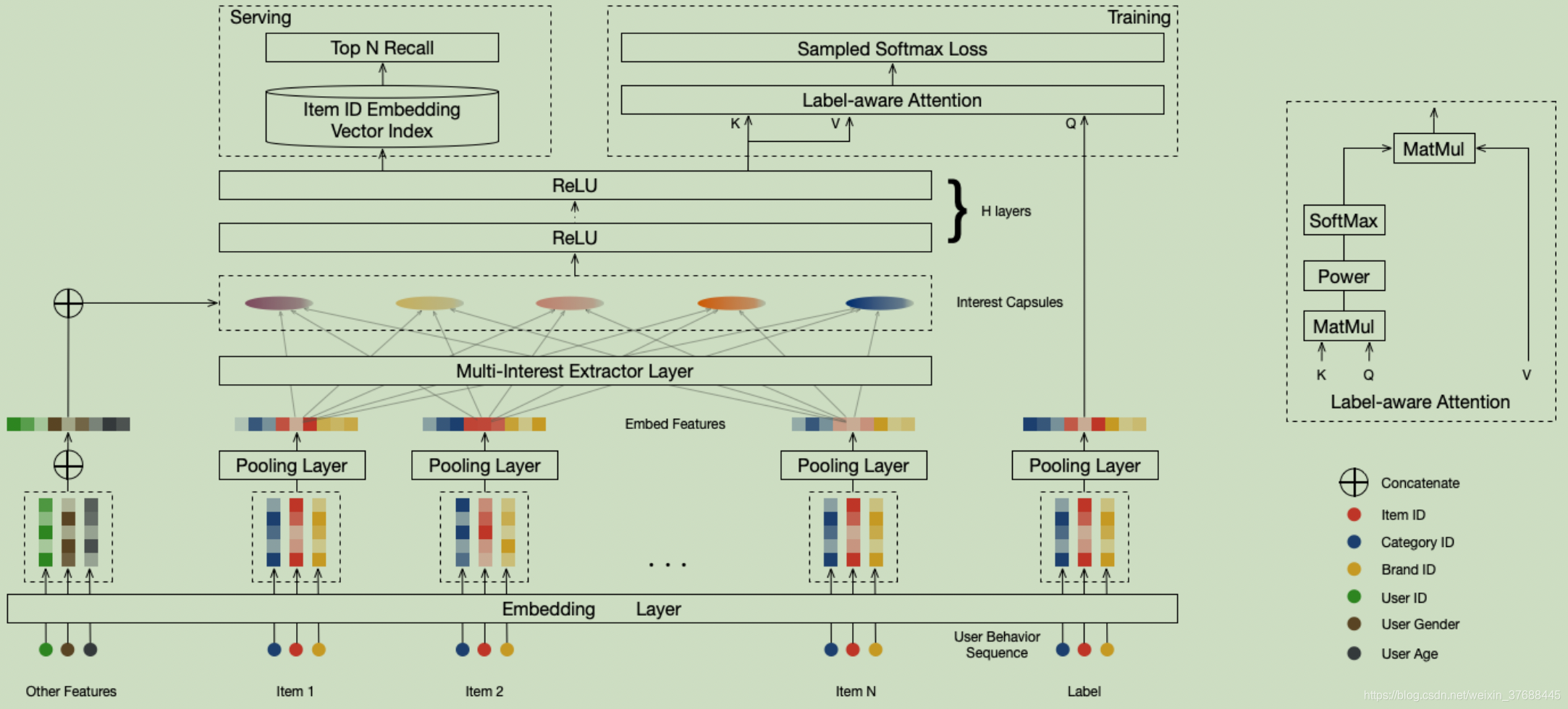
模型阐述
训练阶段:利用Capsule NN模型生成多个user_embedding,并通过Label-aware attention机制构建基于用户兴趣和target item的交叉特征,最终通过负采样机制构建正负样本以及构建损失函数,从而完成整体的模型搭建。
serving阶段:利用多个兴趣embedding向量召回item_embedding,取得分的topN item作为本路召回资源列表。
上述过程较为核心的模块有两个:Capsule NN模型和Label-aware attention机制,如下会简要讲述。
Capsule NN模型
在文章中Capsule NN模型被称作Behavior-to-interest模型(B2I),算法流程如下所示:

实现代码如下所示:
def squash(inputs):
vec_squared_norm = tf.reduce_sum(tf.square(inputs), axis=-1, keep_dims=True)
scalar_factor = vec_squared_norm / (1 + vec_squared_norm) / tf.sqrt(vec_squared_norm + 1e-8)
vec_squashed = scalar_factor * inputs
return vec_squashed
class CapsuleLayer(Layer):
def __init__(self, input_units, out_units, max_len, k_max, iteration_times=3,
init_std=1.0, **kwargs):
self.input_units = input_units
self.out_units = out_units
self.max_len = max_len
self.k_max = k_max
self.iteration_times = iteration_times
self.init_std = init_std
super(CapsuleLayer, self).__init__(**kwargs)
def build(self, input_shape):
self.routing_logits = self.add_weight(shape=[1, self.k_max, self.max_len],
initializer=RandomNormal(stddev=self.init_std),
trainable=False, name="B", dtype=tf.float32)
self.bilinear_mapping_matrix = self.add_weight(shape=[self.input_units, self.out_units],
initializer=RandomNormal(stddev=self.init_std),
name="S", dtype=tf.float32)
super(CapsuleLayer, self).build(input_shape)
def call(self, inputs, **kwargs):
behavior_embddings, seq_len = inputs
batch_size = tf.shape(behavior_embddings)[0]
seq_len_tile = tf.tile(seq_len, [1, self.k_max])
for i in range(self.iteration_times):
mask = tf.sequence_mask(seq_len_tile, self.max_len)
pad = tf.ones_like(mask, dtype=tf.float32) * (-2 ** 32 + 1)
routing_logits_with_padding = tf.where(mask, tf.tile(self.routing_logits, [batch_size, 1, 1]), pad)
weight = tf.nn.softmax(routing_logits_with_padding)
behavior_embdding_mapping = tf.tensordot(behavior_embddings, self.bilinear_mapping_matrix, axes=1)
Z = tf.matmul(weight, behavior_embdding_mapping)
interest_capsules = squash(Z)
delta_routing_logits = reduce_sum(
tf.matmul(interest_capsules, tf.transpose(behavior_embdding_mapping, perm=[0, 2, 1])),
axis=0, keep_dims=True
)
self.routing_logits.assign_add(delta_routing_logits)
interest_capsules = tf.reshape(interest_capsules, [-1, self.k_max, self.out_units])
return interest_capsules
def compute_output_shape(self, input_shape):
return (None, self.k_max, self.out_units)
def get_config(self, ):
config = {'input_units': self.input_units, 'out_units': self.out_units, 'max_len': self.max_len,
'k_max': self.k_max, 'iteration_times': self.iteration_times, "init_std": self.init_std}
base_config = super(CapsuleLayer, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
Label-aware attention机制

较为传统的attention机制,代码如下所示:
class LabelAwareAttention(Layer):
def __init__(self, k_max, pow_p=1, **kwargs):
self.k_max = k_max
self.pow_p = pow_p
super(LabelAwareAttention, self).__init__(**kwargs)
def build(self, input_shape):
# Be sure to call this somewhere!
self.embedding_size = input_shape[0][-1]
super(LabelAwareAttention, self).build(input_shape)
def call(self, inputs, training=None, **kwargs):
keys = inputs[0]
query = inputs[1]
weight = reduce_sum(keys * query, axis=-1, keep_dims=True)
weight = tf.pow(weight, self.pow_p) # [x,k_max,1]
if len(inputs) == 3:
k_user = tf.cast(tf.maximum(
1.,
tf.minimum(
tf.cast(self.k_max, dtype="float32"), # k_max
tf.log1p(tf.cast(inputs[2], dtype="float32")) / tf.log(2.) # hist_len
)
), dtype="int64")
seq_mask = tf.transpose(tf.sequence_mask(k_user, self.k_max), [0, 2, 1])
padding = tf.ones_like(seq_mask, dtype=tf.float32) * (-2 ** 32 + 1) # [x,k_max,1]
weight = tf.where(seq_mask, weight, padding)
weight = softmax(weight, dim=1, name="weight")
output = reduce_sum(keys * weight, axis=1)
return output
def compute_output_shape(self, input_shape):
return (None, self.embedding_size)
def get_config(self, ):
config = {'k_max': self.k_max, 'pow_p': self.pow_p}
base_config = super(LabelAwareAttention, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
train & serve
总结
该模型解决的问题为更加细致地刻画用户兴趣,这是DIN等一系列模型所无法比拟的。














 6132
6132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









