









背景:
2002年 起源于Apache Nutch
2004年 借鉴Google GFS, 开发Nutch MapReduce
2004年 借鉴Google MapReduce 开发Nutch MapReduce
2006年 成为Lucene下的独立子项目 改名为Hadoop
2008年 Hadoop成为Apache的顶级项目
一、基本概念
1、块 block :是文件存储处理的逻辑单元 默认一个块64MB 每个块保存3份
2、NameNode:保存元数据
3、DataNode: 保存数据块
二、数据管理策略和容错
1、每个数据块保存3份
2、心跳检测
3、二级NameNode: SecondaryNameNode
三、HDFS特点
1、数据冗余 水平拓展 高容错 廉价硬件 开源生态系统
2、流式的数据访问(写一次 读多次)
3、存储大文件
适用性和局限性:
1、适合数据批量读写 高吞吐量
2、不适合交互式应用 低延迟很难满足
3、适合一次写入多次读取,顺序读写
4、不支持多用户并发写相同文件


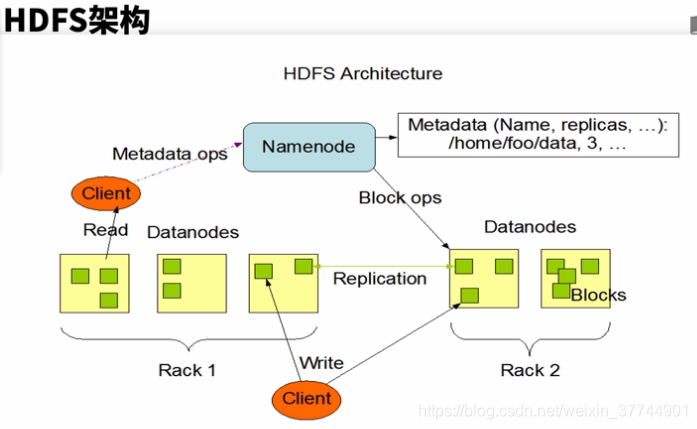
四、HDFS架构
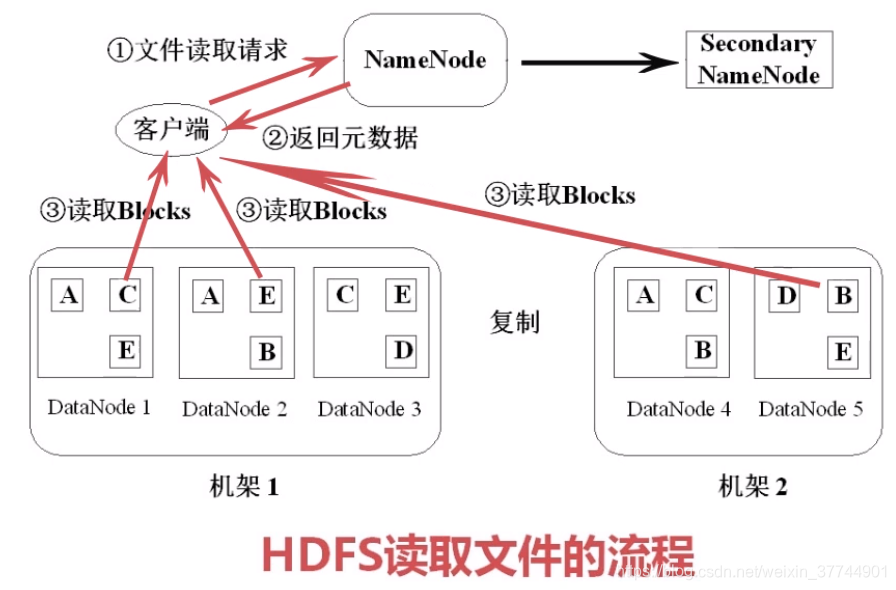
五、HDFS读写操作
1、读

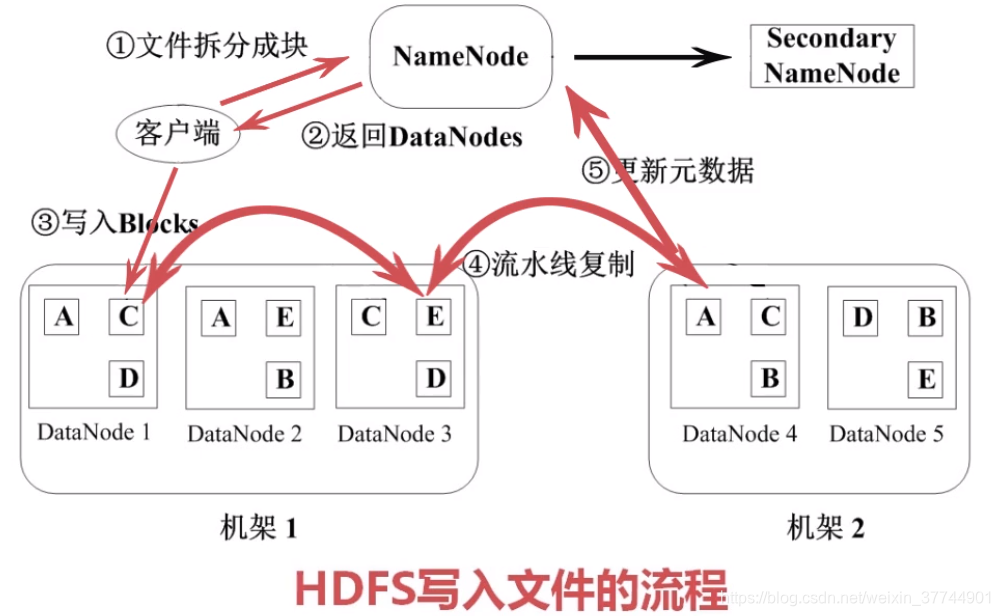
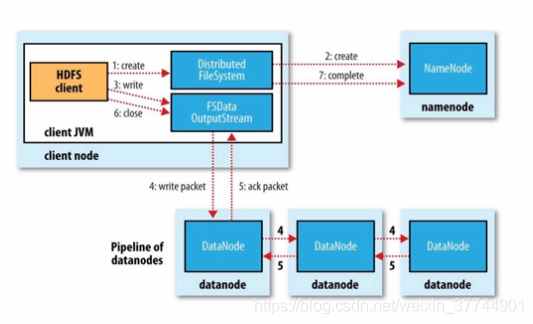
2、写


六、副本放置策略
1、NameNode来选择数据库的存放节点 它按照机架配置来选择节点
2、如果是3芬苯放置策略 优先放置到离写入客户端最近的DataNode节点
3、然后是该节点同机架上的一个节点
4、最后是与该节点不在同机架的一个节点
辅助策略:
1、随机选一个几点
2、随机选择2次 返回磁盘使用率较低的一个节点
七、部署安装


回收站:开启回收站之后 用户通过fs shell不小心删除的文件会被先放到回收站中 回收站的清除粗略默认1小时 也可设置更久的时间

seen_txid: 事务id
in_use.lock: 表示当前block正在被使用
edits_inprogress_00000000940393849: 表示当前文件持续更新中
可以发现: 其他处理好的文件名 有起始事务id - 结束事务id 组成 并且文件之间的事务id是首尾相连的 (如果存在不相连的事务id 那说明数据丢失)

BP: block pool
finalized: 默认有200多个subdir subdir又会生成子级subdir 多级目录
日志:

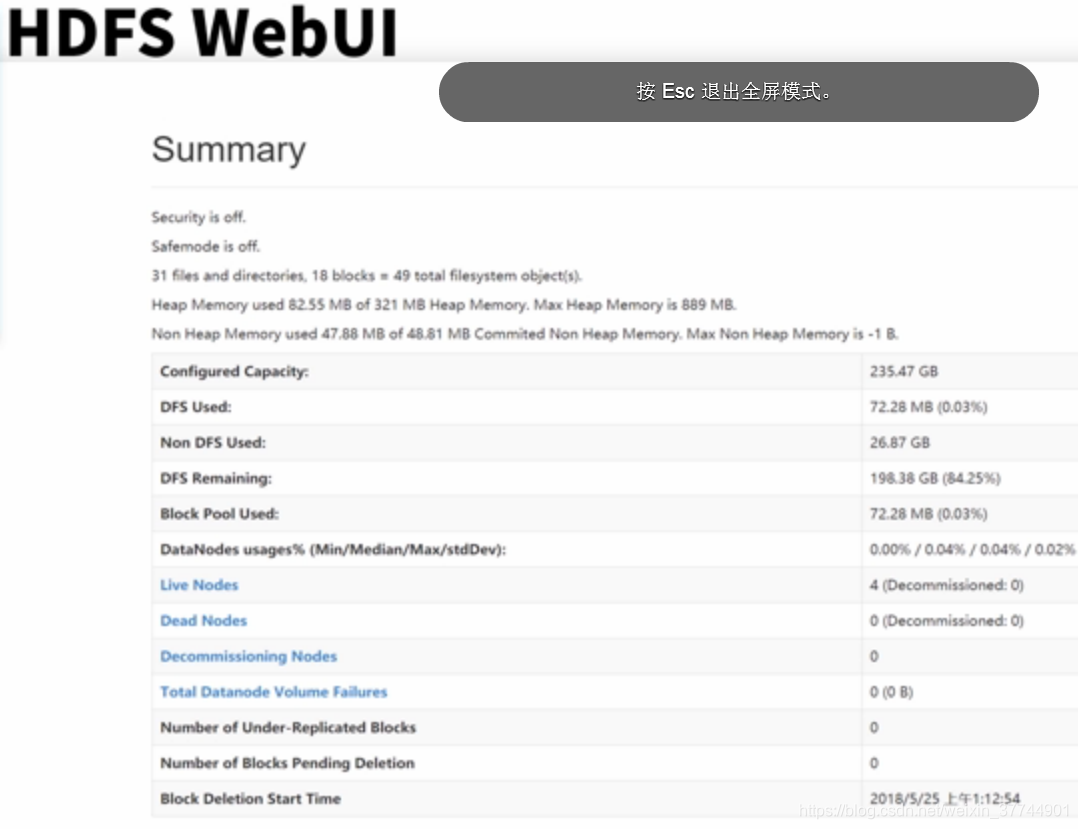
Secunity is off: 没有开启Secunity
Safemode is off: 可以提供正常读写功能
Live Nodes: 存活节点
Dead Nodes:异常节点
还有其他的HDFS的监控信息
八、HDFS相关命令:
put get cat dfsadmin -report














 982
982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









