







一、文献梳理
1、文献背景
依靠深度堆叠网络层数,增加网络宽度的实现,这种结构设计会大量增加参数。一方面会拖慢运行速度,另一方面,需要很大的存储空间进行存储。这两方面也限制了很多网络在实际应用中的落地。因此,如何在保证性能的情况下设计更小,更快速的网络就成了关注的重点。
2、研究成果
1)模型意义
- 提出了一种简单且普遍适用的方法,通过在相同/不同的未预训练的网络中进行相互蒸馏,来提高深层神经网络的性能。通过这种方法,我们可以获得比静态教师从强网络中提取的网络性能更好的紧凑网络.
- 和有教师指导的蒸馏模型相比,相互学习策略具有以下优点:随着学生网络的增加其效率也得到提高;它可以应用在各种各样的网络中,包括大小不同的网络;即使是非常大的网络采用相互学习策略,其性能也能够得到提升
- 由于是学生网络相互学习,而不是传统知识萃取,文章也说明了两个以上网络共同学习的策略,并从熵值的角度给出理论支持。
2)实验及其结果
(1)cifar-100
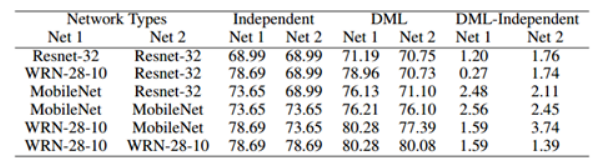
(2)Market-1501

(3)结论
可以看出,与自主学习相比,DML极大地提高了MobileNet的性能,有和没有在ImageNet上进行预培训。这也可以看出,性能的
用两个MobileNets训练的DML方法明显优于先前的先进技术深度学习的方法。
二、目标识别(分类)相关技术
1、基本思想
目标识别的挑战包括物理条件变化、类内差异大,类间差异小三部分。为解决这三方面的问题,需要更好的对物体进行抽象特征的提取与表示。随着卷积神经网络的发展,我们期望利用卷积核提取更丰富、更深层次的特征信息。基于此,网络对一张图片中的信息提取更为细致、特征提取更为全面。
2、交叉熵
1)公式
熵用来表示所有信息量的期望,二分类交叉熵损失公式:

多分类的情况实际上就是对二分类的扩展,多分类交叉熵损失公式:

2)为什么交叉熵可以用作代价?
最小化模型分布与训练数据上的分布的差异等价于最小化这两个分布间的KL散度,也就是最小化A与B的交叉熵。得证,交叉熵可以用于计算“学习模型的分布”与“训练数据分布”之间的不同。当交叉熵最低时(等于训练数据分布的熵),我们学到了“最好的模型”。但是,完美的学到了训练数据分布往往意味着过拟合,因为训练数据不等于真实数据,我们只是假设它们是相似的,而一般还要假设存在一个高斯分布的误差,是模型的泛化误差下线。
3、KL散度
1)公式
相对熵,又被称为KL散度或信息散度,是两个概率分布间差异的非对称性度量 。在信息论中,相对熵等价于两个概率分布的信息熵的差值,若其中一个概率分布为真实分布,另一个为理论(拟合)分布,则此时相对熵等于交叉熵与真实分布的信息熵之差,表示使用理论分布拟合真实分布时产生的信息损耗 。

在理论拟合出来的事件概率分布跟真实的一模一样的时候,相对熵等于0。而拟合出来不太一样的时候,相对熵大于0。这个性质很关键,因为它正是梯度下降法需要的特性。假设神经网络拟合完美了,那么它就不再梯度下降,而不完美则因为它大于0而继续下降。
2) 证明下相对熵公式只有在p(xi)等于q(xi)的时候等于0,其他时候大于0。

4、蒸馏模型
1)原理
基于教师——学生网络的方法,属于迁移学习的一种。迁移学习也就是将一个模型的性能迁移到另一个模型上,而对于教师——学生网络,教师网络往往是一个更加复杂的网络,具有非常好的性能和泛化能力,可以用这个网络来作为一个soft target来指导另外一个更加简单的学生网络来学习,使得更加简单、参数运算量更少的学生模型也能够具有和教师网络相近的性能,也算是一种模型压缩的方式。
2)模型
这个复杂的网络是提前训练好具有很好性能的网络,学生网络的训练含有两个目标:一个是hard target,即原始的目标函数,为小模型的类别概率输出与label真值的交叉熵;另一个为soft target,为小模型的类别概率输出与大模型的类别概率输出的交叉熵,在soft target中,概率输出的公式调整如下,这样当T值很大时,可以产生一个类别概率分布较缓和的输出:
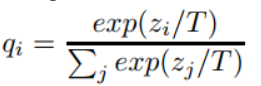
作者认为,由于soft target具有更高的熵,它能比hard target提供更加多的信息,因此可以使用较少的数据以及较大的学习率。将hard和soft的target通过加权平均来作为学生网络的目标函数,soft target所占的权重更大一些。 作者同时还指出,T值取一个中间值时,效果更好,而soft target所分配的权重应该为T^2,hard target的权重为1。 这样训练得到的小模型也就具有与复杂模型近似的性能效果,但是复杂度和计算量却要小很多。 对于distilling而言,复杂模型的作用事实上是为了提高label包含的信息量。通过这种方法,可以把模型压缩到一个非常小的规模。模型压缩对模型的准确率没有造成太大影响,而且还可以应付部分信息缺失的情况。

5、补充

三、文献重点
1、模型
结构:模型定义了两个网络。除了使用GT对各自进行监督,还引入了一个额外的loss,引导他们进行相互间的学习。这个额外的loss,利用相对熵,即KL散度来定义。

损失函数:

2、优化
两个模型一起训练,且互相学习直到收敛。不会像传统的distillation,student学习一个已经训练好的teacher,还只是用来初始化参数。
















 4783
4783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









