






 文章提出了深度互学习(DML)的概念,作为模型蒸馏的一种替代方法。在DML中,多个未经训练的神经网络学生互相协作和教导,而不是依赖于预训练的教师网络。实验表明,这种方法能提高不同架构网络的泛化能力,尤其在小网络中,甚至超越了从大型教师网络蒸馏出的模型。DML不仅适用于图像分类,还在人员再识别任务上取得最优结果,且能扩展到半监督学习和更大规模的网络群体。
文章提出了深度互学习(DML)的概念,作为模型蒸馏的一种替代方法。在DML中,多个未经训练的神经网络学生互相协作和教导,而不是依赖于预训练的教师网络。实验表明,这种方法能提高不同架构网络的泛化能力,尤其在小网络中,甚至超越了从大型教师网络蒸馏出的模型。DML不仅适用于图像分类,还在人员再识别任务上取得最优结果,且能扩展到半监督学习和更大规模的网络群体。
论文:Deep Mutual Learning 深度互学习
发表时间:2018 CVPR
摘要
模型蒸馏是一种将知识从教师转移到学生网络的有效且广泛应用的技术。典型的应用是从强大的大型网络或集成传输到小型网络,以满足低内存或快速执行的要求。在本文中,我们提出了一种深度互学习(DML)策略。不同于模型蒸馏中静态预定义的教师和学生之间的单向传递,使用DML,学生在整个训练过程中协作学习并相互教授。我们的实验表明,各种网络架构受益于相互学习,并在类别和实例识别任务上取得了令人信服的结果。令人惊讶的是,它揭示了强大的教师网络并非必要,简单的学生网络集合相互学习是有效的,而且比从一个更强大但静态的教师蒸馏更有效。
1.引言
深度神经网络在许多问题上实现了state of the art ,但通常具有很大的深度和/或宽度,并且包含大量的参数。这样做的缺点是执行速度慢或存储容量大,限制了它们在低内存或快速执行要求的应用程序或平台上的使用,例如移动电话。这导致了开发更小、更快模型的研究迅速增长。实现紧凑而准确的模型已经通过各种方式进行,包括explicit frugal architecture design[9],模型压缩[22],剪枝[14],二值化[18]和模型蒸馏[8]。
基于蒸馏的模型压缩的观察[3,1]发现,小网络通常具有与大网络相同的表示能力;但与大型网络相比,它们只是更难训练,更难找到实现所需功能的正确参数。也就是说,限制似乎在于优化的难度,而不是网络大小[1]。为了更好地学习小型网络,蒸馏方法从一个强大的(更深和/或更广)教师网络(或网络集成)开始,然后训练一个较小的学生网络来模仿教师[8,1,16,3]。模仿教师的类概率[8]和/或特征表示[1,19]传递了超出传统监督学习目标的额外信息。学习模仿老师的优化问题被证明比直接学习目标函数更容易,学生模型的效果可以匹敌甚至超过教师模型。
在本文中,我们的目标是解决同样的问题,即学习小型但强大的深度神经网络。然而,我们探索了一个与模型蒸馏不同但相关的想法——互学习。“蒸馏”从一个强大的、经过预先培训的教师网络开始,并向一个未经培训的小学生进行单向的知识转移。相比之下,在相互学习中,我们从一群未经训练的学生开始,他们同时学习一起解决任务。具体来说,每个学生都接受了两种损失的训练:一种是传统的监督学习损失(supervised learning loss),另一种是模仿损失(mimicry loss),它使每个学生的类后验与其他学生的类概率保持一致(这句话什么意思)。在这样的训练下,每个学生在这种以同伴教学为基础的场景下,学习效果明显优于在传统的监督学习场景下独自学习。此外,相互学习的学生网络比从一个更大的预培训教师那里通过常规蒸馏培养的学生获得更好的结果。此外,尽管传统意义上的蒸馏需要一个比目标学生更强大的老师,但事实证明,在许多情况下,与自主学习相比,几个大型网络的相互学习也能提高成绩。这使得深度互学习策略具有普遍的适用性,例如,它也可以用于不受模型大小限制,只考虑识别精度的应用场景。
当学习过程开始于那些规模小、未经训练的学生网络时,额外的知识从何而来?为什么它会趋近于一个好的解决方案,而不是被“盲人领盲人”的群体思维所束缚?对这些问题的一些直觉可以通过考虑以下因素来获得:每个学生主要受到传统的监督学习损失的指导,这意味着他们的表现通常会提高,他们不能随意地陷入群体思维。有了监督学习,所有网络很快就会为每个训练实例预测相同的(真实的)标签;但是由于每个网络从不同的初始条件开始,它们学习不同的表示,因此它们对下一个最有可能的类别的概率的估计也不同。正是这些次要量在蒸馏[8]中提供了额外的信息,以及相互学习。在相互学习中,学生群体有效地汇集了他们对下一个最有可能的班级的集体估计。根据每个训练实例的同类,找出并匹配其他最有可能的类会增加每个学生的后验熵[4,17],这有助于他们收敛到更鲁棒(更平坦)的最小值,并对测试数据有更好的泛化。这与最近关于深度学习中高后视熵解(网络参数设置)的鲁棒性的工作有关[4,17],但与盲目熵正则化相比,是一种更明智的方案。
总的来说,互学习提供了一种简单而有效的方法,通过与其他网络进行协作训练来提高网络的泛化能力。针对对象类别识别(CIFAR100[12]上的图像分类)和实例识别问题(Market1501[33]上的人员再识别)进行了大量的实验。结果表明,与预先训练的静态大网络蒸馏相比,小同伴协作学习的效果更好。特别是,在人员再识别任务上,与最新的竞争对手相比,使用经过相互学习训练的更小的网络可以获得state-of-the art 的结果。此外,我们观察到:
(i)它适用于各种网络架构,以及由大小混合网络组成的异构队列;
(ii)效能随着队列中网络数量的增加而增加——这是一个很好的属性,因为通过只在小网络上训练,更多的网络可以适合给定的GPU资源,以实现更有效的相互学习;
(iii)它也有利于半监督学习,在标记和未标记数据上激活模仿损失。
最后,我们注意到,虽然我们的重点是获得一个单一的有效网络,但整个队列也可以用作一个高效的集成模型。
2.相关工作
模型蒸馏
基于蒸馏的模型压缩方法在十多年前[3]就被提出了,但最近被[8]重新推广,其中提出了一些关于它为什么有效的见解——由于对higher entropy soft-targets的额外监督和正则化。最初,一个常见的应用是将一个强大的模型/集成教师近似的函数提取为一个单一的神经网络学生[3,8]。但后来,这个想法被应用于将强大且易于训练的大型网络提炼成难以训练的小型网络,甚至可以超过他们的老师。最近,蒸馏与信息学习理论[15]和SVM+[25](聪明的教师为学生提供特权信息)有了更系统的联系。这种使用模型蒸馏来学习特权信息的想法已经被Zhang等人利用。[29]用于动作识别:更昂贵的光流场被视为特权信息,光流CNN被用于教授运动向量CNN。在要从教师那里提取知识的表示方面,现有模型通常使用教师的类概率[8]和/或特征表示[1,19]。最近,Yim等人[27]利用层与层之间的特征映射内积计算层与层之间的流。与模型蒸馏相比,我们解决了完全不需要教师模型的问题,允许一群学生学生模型在相互蒸馏中互相教授。
协同学习
其他与协同学习(collaborative learning)相关的想法包括Dual Learning [6],两个跨语言翻译模型相互交互教学。但这只适用于这个特殊的翻译问题,在这个问题中,可以使用无条件的语言内模型来评估预测的质量,并最终提供推动学习过程的监督。此外,在对偶学习模型中,不同的学习任务是不同的,而在互学习模型中,学习任务是相同的。最近,合作学习[2]被提出,为同一任务,但在不同领域联合学习多个模型。例如,识别同一组对象类别,但一个模型输入RGB图像,另一个输入深度图像。模型通过域不变的对象属性进行通信。这与互学不同,互学中所有模型都处理相同的任务和领域。
3.深度互学习
3.1 模型提出 Formulation
我们提出两个网络的深层互学习(DML)如图1。也可以扩展到更多的网络(见第3.3部分)。
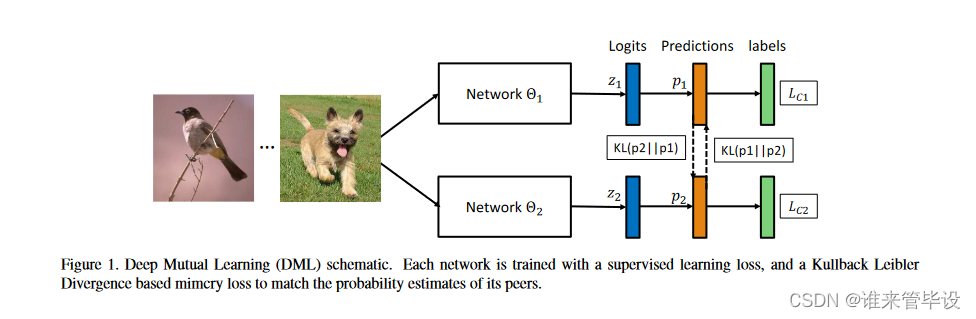
具体来说,每个网络在学习过程中有两个损失函数,一个是传统的监督损失函数,采用交叉熵损失来度量网络预测的目标类别与真实标签之间的差异,另一个是网络间的交互损失函数,采用KL散度来度量两个网络预测概率分布之间的差异。公式表示为:

(这里原文对于计算公式写的更详细一些,但没有摘录下来)
采用这两种损失函数,不仅可以使得网络学习到如何区分不同的类别,还能够使其参考另一个网络的概率估计来提升自身泛化能力。
3.2 优化 Optimisation
模型蒸馏和DML之间的一个关键区别是,在DML中,两个模型是联合和协作优化的,两个模型的优化过程被密切干预。互学习策略被嵌入到两个模型的每个基于小批量的模型更新步骤中,并贯穿于整个训练过程。模型是用相同的小批量学习的。在每次迭代中,我们计算两个模型的预测,并根据另一个模型的预测更新两个网络的参数。对Θ1和Θ2(即两个网络)进行迭代优化,直到收敛。算法1总结了优化细节。如果在单个GPU上运行,它由4个连续步骤组成。当有两个GPU可用时,分布式训练可以通过在一个GPU上并行运行步骤1、2,在另一个GPU上并行运行步骤3、4来实现。
3.3 Extension to Larger Student Cohorts
DML能够自然地扩展到更多学生网络的情况。假设有K个网络Θ1,Θ2,……Θk,优化Θk的目标函数为:
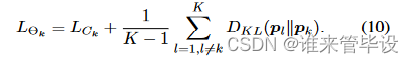
表明对于K个网络,每个学生的DML有效地将队列中其他K−1个网络作为教师提供模仿目标。两个网络的互学习即为K=2的特殊情况。
在我们的实验中(参见第4.8节),我们发现这种具有单个集成教师的DML策略(表示为DML e)比具有K−1个教师的DML性能更差。这是因为建立教师集合的模型平均步骤(式(11))使得教师的后验概率在真实班级上更趋于峰值,从而减小了所有班级的后验熵。因此,它与DML产生具有高后验熵的鲁棒解这一目标相矛盾。

3.4 Extension to Semi-supervised Learning
所提出的DML直接扩展到半监督学习。在半监督学习设置下,我们只对标记数据激活交叉熵损失,而对所有训练数据计算基于KL距离的模仿损失。这是因为KL距离计算不需要类标签,所以也可以使用无标签的数据。
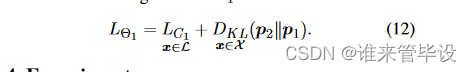
4. 实验
4.1 Datasets and Settings
数据集 在我们的实验中使用了四个数据集。ImageNet[20]数据集包含1000个对象类,其中约有120万张用于训练的图像和5万张用于验证的图像。CIFAR-10和CIFAR-100[12]数据集由32 × 32彩色图像组成,分别包含10个和100个类别的物体。两者都被分为5万张图像序列集和1万张图像测试集。采用Top-1分类精度作为评价指标。Market-1501[33]数据集是在人员再识别(re-id)问题[5]中广泛使用的基准。与CIFAR中的对象类别识别问题不同,reid是一个实例识别问题,旨在跨不同的非重叠摄像机视图关联人员身份。Market-1501包含从6个摄像头视图中捕获的1501个身份的32,668张图像,其中751个身份用于训练,750个身份用于测试。根据重新识别[35]的最新方法,我们训练网络进行751路分类,并使用最后一个池化层的结果特征输出作为测试时最近邻匹配的表示。为了进行评估,使用了标准的累积匹配特征(CMC) Rank-k精度和平均平均精度(mAP)指标[33]。
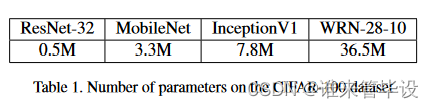
网络结构 实验中使用的网络包括典型学生规模的紧凑网络:Resnet-32[7]和MobileNet [9];以及典型教师规模的大型网络:InceptionV1[24]和Wide ResNet WRN-28-10[28]。表1比较了CIFAR-100所有网络的参数数量。
部署设置 我们在TensorFlow中实现所有网络和训练过程,并在NVIDIA GeForce GTX 1080 GPU上进行所有实验。对于CIFAR-100,我们遵循[28]的实验设置。具体来说,我们使用带有Nesterov动量的SGD,并将初始学习率设置为0.1,动量设置为0.9,minibatch大小设置为64。学习率每60个epoch下降0.1,我们训练了200个epoch。数据增强包括水平翻转和从每边填充4个像素的图像中随机裁剪,用原始图像的反射填充缺失的像素。对于Market-1501,我们使用Adam优化器[11],学习率lr = 0.0002, β1 = 0.5, β2 = 0.999,迷你批量大小为16。对于ImageNet,我们使用RMSProp衰减为0.9,mini-batch大小为64,初始学习率为0.1。学习率每20个周期衰减一次,使用0.16的指数速率。(重要!写的时候要写详细)
4.2 Results on CIFAR-100
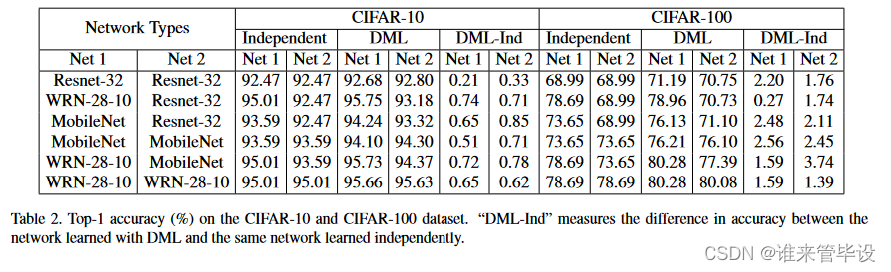
表2比较了两网络DML中不同架构获得的CIFAR-100数据集的Top-1精度。从表中我们可以得出以下观察结果:
(i) ResNet-32、MobileNet和WRN-28-10之间的所有网络组合在队列学习时比独立学习时提高了性能,这由“DMLIndependent”列中的所有正值表示。
(ii)容量较小的网络(ResNet-32和MobileNet)通常从DML中受益更多。
(iii)尽管WRN-28-10是一个比MobileNet或ResNet-32大得多的网络(表1),但它仍然受益于与较小的同行一起训练。
(iv)与独立学习相比,训练大型网络队列(WRN-28-10)仍然是有益的。因此,与传统的模型蒸馏相比,我们看到一个经过预先训练的大型教师并不一定会带来很大的收益,多个大型网络仍然可以从我们的类似蒸馏的过程中受益。
4.3 Results on Market-1501
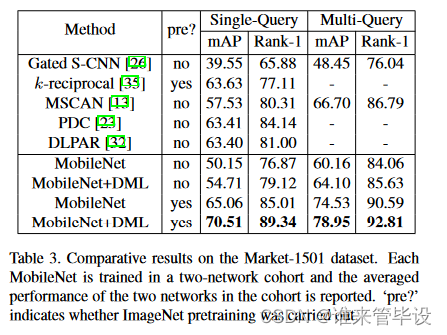
我们在一个双网络DML队列中使用MobileNet。表3总结了使用/不使用DML训练的MobileNets Market-1501的mAP(%)和rank1准确率(%),以及与现有最先进方法的比较。我们可以看到,在这个更具挑战性的实例识别问题上,与独立学习相比,无论是否在ImageNet上进行预训练,DML都大大提高了MobileNet的性能。还可以看出,我们使用两个mobilenet的DML方法显著优于先前SOTA的深度再识别方法。这一点值得注意,因为MobileNet是一个简单、小型和通用的网络。相比之下,许多最近提出的深度再识别网络(如[31,23,34]中的网络)具有复杂和特别设计的架构,以处理在跨摄像机视图匹配人物时剧烈的姿势变化和身体部位不对齐。
4.4 Results on ImageNet
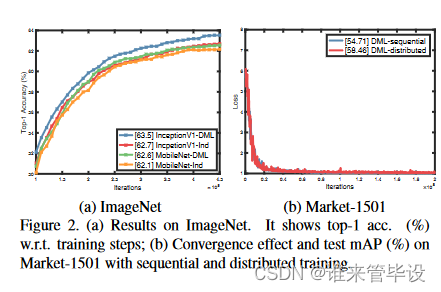
图2 (a)将MobileNet和InceptionV1在ImageNet上的准确率与独立训练和DML训练进行了比较。我们可以看到,这两种架构的DML变体始终比它们独立训练的变体表现得更好。这些结果表明,DML适用于大规模问题。
4.5 Distributed Training of DML
为了研究训练策略对DML的影响,我们比较了两种DML变体:1)sequential:在一个GPU上根据算法1训练两个网络;两个网络一个接一个地更新;2)distributed:每个网络在单独的GPU上训练,CPU用于KL散度通信;这样,两个网络的预测和参数可以同时更新。我们在带有2个mobilenet的Market-1501上进行了实验,并在图2 (b)中显示了收敛和mAP结果。有趣的是,观察到我们的DML的性能通过分布式训练得到了进一步提高。比较这两个变体,两个网络在训练分布时更“相等”,因为它们总是具有完全相同的训练迭代次数。因此,这一结果表明,当学生的学习进度差异最小化时,学生从DML同侪教学中受益最大。
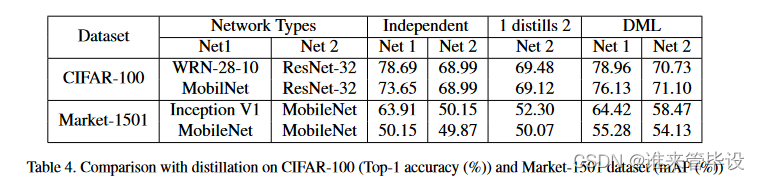
4.6 Comparison with Model Distillation
由于我们的方法与模型蒸馏密切相关,我们接下来将对蒸馏[8]进行重点比较。表4比较了我们的DML与模型蒸馏,其中教师网络(Net 1)是预训练的,并为学生网络(Net 2)提供固定的后验目标。正如预期的那样,与独立学习学生相比,来自强大的预训练教师的传统蒸馏方法确实提高了学生的表现(1蒸馏2相对于Net 2独立)。然而,结果表明,在深度相互学习中,将两个网络一起训练比蒸馏(1蒸馏2与DML Net 2相比)提供了明显的改进。这意味着在相互学习的过程中,通过与先验的未经训练的学生互动学习,扮演教师角色的网络实际上比预先接受过培训的教师更好。
4.7 DML with Larger Student Cohorts
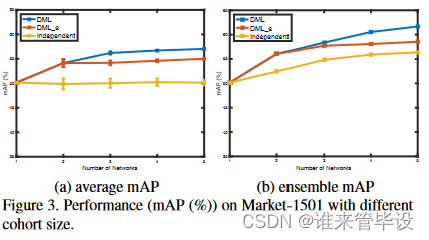
先前的实验研究了2名学生的队列。接下来,我们将研究DML如何随着队列中更多学生的增加而扩展。图3(a)显示了在Market-1501上使用增加mobilenet队列规模的DML训练的结果。图中显示的是平均mAP,以及标准差。从图3(a)中我们可以看到,平均单个网络的性能随着DML队列中网络数量的增加而增加,因此与独立训练的网络存在差距。这表明,当学生与越来越多的同伴一起学习时,学生的泛化能力得到增强。不同网络的表现也与较大的队列规模更一致,由较小的标准差表示。在训练多个网络时,常用的技术是将它们作为一个集合,并进行联合预测。在图3(b)中,我们使用与图3(a)相同的模型,但基于集合进行预测(基于所有成员的连接特征进行匹配),而不是报告每个个体的平均预测。从结果中我们可以看到,集合预测优于预期的单个网络预测(图3(b) vs. (a))。此外,集合性能也得益于将多个网络作为DML队列进行训练(图3(b) DML集合与独立集合)。
4.8 How and Why does DML Work?
在本节中,我们试图对深度互学习策略如何以及为什么起作用给出一些见解。最近有一波关于“为什么深度网络泛化”主题的研究[4,30,10],这些研究提供了一些见解,例如:虽然经常有许多解决方案(深度网络参数设置)产生零训练误差,但其中一些解决方案比其他解决方案泛化得更好,因为它们处于宽山谷而不是窄裂缝[4,10]-因此小扰动不会大幅改变预测效果;并且深度网络在寻找这些好的解[30]方面比预期的更好,但是通过将深度网络偏向于具有更高后验熵的解,可以增强寻找鲁棒最小值的趋势[4,17]。
DML Leads to Better Quality Solutions with More Robust Minima
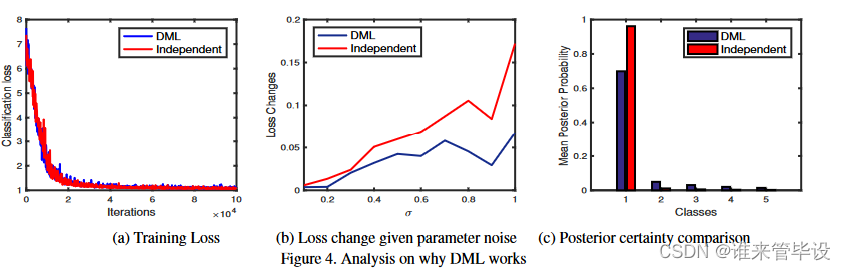
首先我们注意到,在我们的实验中,网络通常完美地拟合训练数据:训练准确率达到100%,分类损失变得最小(例如,图4(a))。然而,正如我们前面看到的,DML在测试数据上表现更好。因此,DML并不是帮助我们找到一个更好的训练损失最小值,而是帮助我们找到一个更广泛/更鲁棒的最小值,从而更好地概括测试数据。受[4,10]的启发,我们使用MobileNet进行了一个简单的测试,以分析CIFAR-100上发现的最小值的鲁棒性。对于DML模型和独立模型,我们比较了在每个模型参数上添加可变标准差σ的独立高斯噪声前后学习模型的训练损失。我们可以看到两个最小值的深度是相同的(图4(a)),但是在添加了这个扰动后,独立模型的训练损失急剧上升,而DML模型的损失增加得更少。这表明DML模型发现了一个更“宽”的最小值,这有望提供更好的泛化性能[4,17]。
How is a Better Minimum Found?
当要求每个网络匹配其同伴的概率估计时,当给定网络预测为零而它的老师/同伴预测非零时,不匹配将受到严重惩罚。因此,DML的总体效果是,当每个网络独立地将一个小质量放在一个小的次要概率集上时,DML中的所有网络都倾向于聚合它们对次要概率的预测,并且两者(i)都将更多的质量放在次要概率上,并且(ii)将非零质量放在更明显的次要概率上。
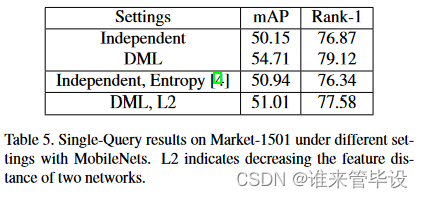
我们通过比较由DML训练的CIFAR-100上的ResNet-32与独立训练的ResNet-32模型获得的前5个排名最高的类的概率来说明这种效应,如图4(c)所示。对于每个训练样本,前5个类别根据模型产生的后验概率进行排名(第1类是真实的类别,第2类是第二最可能的类别,等等)。在这里我们可以看到,在Top-1以下的概率中,独立的质量分配比DML衰减得更快。这可以通过DML训练模型和独立训练模型在所有训练样本上的平均熵值来量化,分别为1.7099和0.2602。因此,我们的方法与基于熵正则化的方法[4,17]有关,以寻找宽极小值,但通过“合理”替代方案上的相互概率匹配,而不是盲目的高熵偏好。表5进一步表明,当将DML与基于熵正则化的方法[4](DML vs. Independent, entropy)进行比较时,这是学习更一般化模型的更有效的方法。
DML with Ensemble Teacher
在DML中,无论队列中有多少学生,每个学生都由队列中的所有其他学生单独教授(式(10))。在第3.3节中,讨论了另一种DML策略(DML e),通过该策略,要求每个学生匹配队列中所有其他学生的集合预测(式(11))。人们可能会合理地期望这种方法更好:由于集合预测比单独预测更好,它应该提供更清晰和更强的教学信号——更像传统的蒸馏。在实践中,集成的结果比同伴教学的结果更差(如图3所示)。通过分析集成的教学信号与同伴教学的比较,集成目标在真实标签处的峰值比同伴目标明显得多,导致DML的预测熵值(0.2805)大于DML e(0.1562)。因此,虽然集合的噪声平均特性对于做出正确的预测是有效的,但它实际上不利于提供一个教学信号,其中二级类概率是信号中的显著线索,并且具有高熵后验会导致更健壮的模型训练解决方案。
4.9 Does DML Makes Models More Similar?
我们知道,在相同的训练目标下,DML队列中不同模型的预测类后验将是相似的。问题是,这些模型是否也会产生相似的特征,特别是当模型具有相同的架构时?图5显示了两个mobilenet对Market-1501测试集上特征分布的t-SNE可视化。我们可以看到,无论是否使用DML,两个mobilenet确实有不同的特征,说明得到了不同的模型。这有助于解释为什么DML队列中的不同模型可以相互学习:每个模型都学到了其他模型没有的东西。(哇)

我们注意到,在许多模型蒸馏研究中[1,19],添加了一个特征距离损失,以迫使学生网络在相应层产生与教师相似的特征。当老师是经过预先训练和固定的,而学生的目标是模仿老师时,这是有道理的。然而,在DML中,对不同DML模型的内部表示进行对齐会减少队列多样性,从而损害每个网络教授同伴的能力。表5显示,当引入特征L2损失时,DML的确变得不那么有效(DML vs. DML, L2)。
4.10 Semi-Supervised Learning
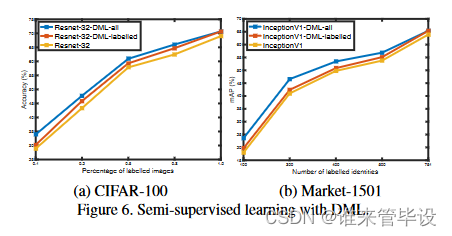
最后,我们探讨了CIFAR100和Market-1501中的半监督学习。对于CIFAR-100,我们随机选择每个类的训练图像的子集(从10%到100%)作为标记,并将其余的图像视为未标记。对于Market1501,我们随机选择训练集中标记的M个身份,M从100到751不等。实验采用了3种不同的训练策略:1)单网络标记数据训练;2)仅使用DML (DML- labeled)对标记数据进行训练。3)用DML对所有数据进行训练,其中仅对标记数据计算分类损失,对所有训练数据(DML-all)计算KL损失。
从图6的结果中,我们可以看到:
(1)用DML训练两个网络始终比训练单个网络表现得更好——和以前一样,但现在使用不同数量的标记数据。
(2)与仅向标记数据(DML- labeled)添加DML相比,DML-all利用基于kl距离的模拟损失来利用未标记数据,进一步提高了性能。当标记数据的百分比越小,改进就越大。这证实了DML对监督学习和半监督学习场景都有好处。
5.结论
我们提出了一种简单且普遍适用的方法,通过在同伴队列和相互蒸馏中训练深度神经网络来提高深度神经网络的性能。通过这种方法,我们可以获得紧凑的网络,比从强大但静态的教师那里提炼出来的网络表现得更好。DML的一个应用是获得紧凑、快速和有效的网络。我们还表明,这种方法也有望提高大型强大网络的性能,并且以这种方式训练的网络队列可以组合为一个集合,以进一步提高性能。

















 5087
5087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









