







 本文介绍了如何运用并查集和最小堆实现Kruskal算法来寻找图的最小生成树。Kruskal算法的核心是贪心选择和避免形成环路,最小堆用于获取最小权值边,而并查集用于判断边的两端是否已经连接。通过实例和过程图解详细阐述了算法的执行过程,并提供了代码实现中的关键点和注意事项。
本文介绍了如何运用并查集和最小堆实现Kruskal算法来寻找图的最小生成树。Kruskal算法的核心是贪心选择和避免形成环路,最小堆用于获取最小权值边,而并查集用于判断边的两端是否已经连接。通过实例和过程图解详细阐述了算法的执行过程,并提供了代码实现中的关键点和注意事项。
前言
Kruskal是在一个图(图论)中生成最小生成树的算法之一。(另外还有Prim算法,之后会涉及到)这就牵扯到了最小生成树的概念,其实就是总权值最小的一个连通无回路的子图。(结合下文的示意图不难理解)这里的代码并没有用图的存储结构(如:矩阵,邻接链表等)来处理和运用这个算法,而是最简单的三元组输入,这样会使得这个过程简化很多,至于图的存储方式,在之后总结图数据结构的时候会具体讨论。
Kruskal算法的思想与过程
(1)思想:其实这个算法的本质还是一个贪心算法的过程。其实我们可以这样想,一个图中,我们要想让生成的子图(更确切的说是树)总权值最小,那么只要依次选择图中权值最小的边、权值次小的边、……,这样自然就保证了生成的图总权值最小。但是别忘了一点,我们要求的生成的子图还得是一棵树(树的定义:一个连通无回路的图),这就带来了一个问题,我们在权值从小到大选择边的时候,可能会使生成的子图产生了回路,这就不符合概念了,所以我们不仅需要权值从小到大选择边还应该保证这些边组成的子图构不成回路!这个过程不就是贪心选择的过程吗。
过程(标准定义):
任给一个有n个顶点的连通网络N = {V, E},首先构造一个由这n个顶点组成、不含任何边的图T = {V, 空集},其中每个顶点自成一个连通分量。不断从E中取出权值最小的一条边(若有多条,任取其一),若该边的两个端点来自不同的连通分量,则将此边加入T中。如此重复,直到所有顶点在同一个连通分量上为止。
为何用并查集与最小堆实现Kruskal算法?
这个问题最根本的解答在上面Kruskal算法的实现过程当中,过程中涉及到两个重要的步骤:
(1)每次取得权值最小的边
(2)判断加入的边的两个端点是否来自同一连通分量(实质就是保证加入边后不会产生回路)
而最小堆可以实现每次取得一组数据中关键码(这里可以代表权值大小)最小的数据;并查集可以将不同的集合(这里可以代表点集合)Union起来并且可以判断不同集合是否有交集(这里可以判断两个点是否同属于一个集合,进而判断加入边后是否会出现回路!)。没错!这简直就是Kruskal算法实现的标配,下面Kruskal算法的实现过程图也体现了这一点!(注:之前的博文对最小堆和并查集都有总结,对这两个数据结构概念不清的话可以看看)
Kruskal算法生成最小生成树的一个实例:
程序输入数据(三元组格式):
7 9 //图的顶点数量、图的边的数量
0 1 28 //下面每行都存储了一个边的信息
0 5 10 //依次表示:边的端点1、边的端点2、边的权值
1 2 16
1 6 14
2 3 12
3 4 22
3 6 18
4 5 25
4 6 24
图表示:
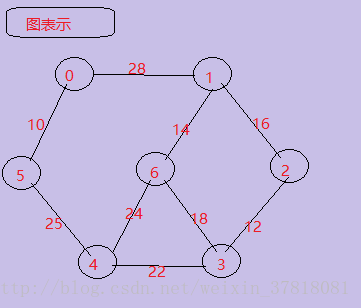
节点中的数字表示节点的序号或者是编号,边上的数字代表每条边的权值,你不要纠结于每条边的权值与其在图上的比例并不协调!因为现实环境中权值的意义有很多,比如花费、代价、重要程度等等。
Kruskal实现过程图解:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









