







 本文介绍了聚类算法的基本概念,重点讲解了K-means和DBSCAN两种方法。K-means算法简单快速,但依赖人为设定K值,对初始点选择敏感。DBSCAN能处理任意形状的簇,无需预设簇数量,但参数调整较为复杂。
本文介绍了聚类算法的基本概念,重点讲解了K-means和DBSCAN两种方法。K-means算法简单快速,但依赖人为设定K值,对初始点选择敏感。DBSCAN能处理任意形状的簇,无需预设簇数量,但参数调整较为复杂。
1、什么是聚类?
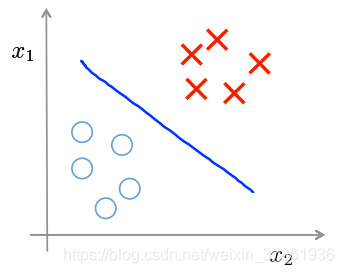
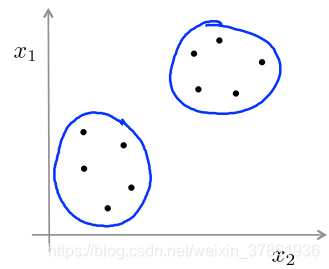
通俗地讲,聚类就是将不带任何标签的数据分成不同的组,是一种典型的无监督机器学习算法,聚类的难点:难以评估和调参。用两张图来理解分类和聚类的区别:
分类:
聚类:
2、K-means聚类
k-means算法是经典的聚类算法之一,在不带标签的多维数据集中寻找确定数量的簇。以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。
几个重要的基本概念:
- K值:需要得到的簇的个数,需要人为指定K值
- 簇中心点:各个簇的中心,属于该簇的所有数据点坐标的算术平均值
- 点到簇中心的距离:常用欧式距离和余弦相似度进行计算(先标准化)
- 优化目标: min ∑ i = 1 K ∑ x ∈ C i d i s t ( C i , x ) 2 \min\displaystyle\sum_{i=1}^K\sum_{x\in C_i}dist(C_i,x)^2 mini=1∑Kx∈Ci∑dist(Ci,x)2
K-means算法:期望最大化
期望最大化(expectation-maximization)成为E-M算法,核心步骤如下:
(1)任意选择k个对象作为初始的簇中心
(2)重复以下步骤直至收敛
- a.期望步骤(E-step):将点分配至离其距离最近的簇中心点
- b.最大化步骤(M-step):将簇中心点设置为改簇中所有点坐标的均值
K-means聚类的优缺点
优点:简单快速,适合常规数据集
缺点:
①初始随机选择的K个簇中心点对聚类影响大,可能不会达到最优全局解
②K值必须事先确定,无法从数据中自动学习到簇的数量
③K-means算法只能确定线形聚类边界,当簇中心点呈现非线性的复杂形状事,算法会失效
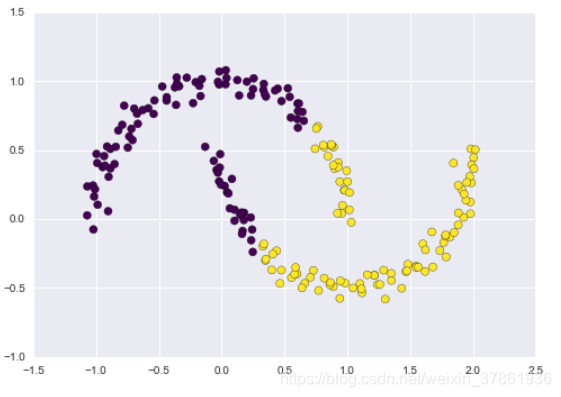
④当数据量较大时,K-means算法会很慢,因为每次迭代都必须对所有数据点进行计算
K-means算法可视化网站:https://www.naftaliharris.com/blog/visualizing-k-means-clustering/
3、DBSCAN聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法。算法假定类别可以通过样本分布的紧密程度决定,同一类别的样本,他们之间是紧密相连的,也就是说,在该类别任意样本周围不远处一定有同类别的样本存在。
定义:由密度可达关系导出的最大密度相连的样本集合,即为我们最终聚类的一个类别,或者说一个簇。
假设样本集是 D = ( x 1 , x 2 , ⋯ , x m ) , D=(x_1,x_2,\cdots,x_m), D=(x1,x2,⋯,xm),参数( ϵ \epsilon ϵ, MinPts)用来描述邻域的样本分布紧密程度。其中, ϵ \epsilon ϵ描述了某一样本的邻域距离阈值,MinPts描述了某一样本的距离为 ϵ \epsilon ϵ的邻域中样本个数的阈值。
几个重要的基本概念:
- ϵ \epsilon ϵ-领域:对于 x j ∈ D x_j\in D xj∈
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









