






使用 ReRanker 和 UMAP 可视化增强检索生成:Llama_Index 和 Llama 2
大家好!
继续 RAG(检索增强生成)之旅,我探索了 UMAP(用于可视化)和重新排序技术。基本上,我深入研究了重新排序的其中一种方式——使用 LLM 本身对文档进行重新排序并提供比向量搜索更相关的块。与往常一样,我还将解决我面临的挑战。我将使用 llama-index 和 Llama 2-chat 7B。
主题 -
- 使用 UMAP 可视化嵌入
- 重新排序——LLMRerank
a. 创建重新排序的提示
b. 解析重新排序器的输出
大致上这就是我将要讲述的内容。
***UMAP*
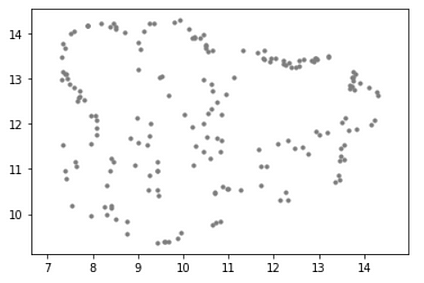
按照谷歌搜索 —***均匀流形近似和投影 (UMAP) 是一种降维技术,可用于类似于 t-SNE 的可视化,也可用于一般的非线性降维。*有一个 Python 包可以帮助将向量索引转换为 UMAP 嵌入,然后可用于绘制数据。它的功能类似于 MinMax 变换:我们首先对所有可用节点/块进行变换,然后对查询和/或相关块使用拟合的变换来可视化它们与实际节点的关系。您可以在共享的代码文件(末尾的链接)中找到完整的安装说明。请记住,UMAP 只是可视化我们的嵌入空间的一种方式。嵌入向量可以是 300-700 大小的向量,我们将它们压缩到二维空间中,因此我们需要小心解释这些图。
# 读取文档
loader = PDFReader()
docs0 = loader.load_data(file=Path( r"all_post_in_one.pdf" ))
doc_text = "\n\n" .join([d.get_content() for d in docs0])
docs = [Document(text=doc_text)]
# 从加载的文档创建节点
node_parser = SimpleNodeParser.from_defaults(chunk_size= 600 , chunk_overlap= 100 )
base_nodes = node_parser.get_nodes_from_documents(docs)
# 设置上下文并选择 wembedding 模型
embed_model = resolve_embed_model( "local:BAAI/bge-small-en" )
service_context = ServiceContext.from_defaults(
llm=llm, embed_model=embed_model
)
# 为每个节点创建嵌入并将其存储在嵌入中
base_index = VectorStoreIndex(base_nodes, service_context=service_context)
base_retriever = base_index.as_retriever(similarity_top_k= 5 )
base_node_text = [base_nodes[i].text for i in range ( len (base_nodes))]
embeddings = embed_model.get_text_embedding_batch(base_node_text)
# 最后拟合 UMAP 变换
umap_transform = umap.UMAP(random_state= 0 , transform_seed= 0 ).fit(embeddings)
# 定义一个函数来为任何数据块创建嵌入
def project_embeddings ( embeddings, umap_transform ):
umap_embeddings = np.empty(( len (embeddings), 2 ))
for i, embedding in enumerate (tqdm(embeddings)):
umap_embeddings[i] = umap_transform.transform([embedding])
return umap_embeddings
# 获取所有块的嵌入
projected_dataset_embeddings = project_embeddings(embeddings, umap_transform)
# 注意 - 您可以将嵌入保存为文件,以便下次直接加载,
# 而不是每次都创建嵌入。
# 绘制嵌入
plt.figure()
plt.scatter(projected_dataset_embeddings[:, 0 ], projected_dataset_embeddings[:, 1 ], s= 10 , color= 'gray' )
plt.gca().set_aspect( 'equal' , 'datalim' )
*绘制查询和检索到的块 —*
# 示例查询及其嵌入
query = '告诉我作者的爱好'
query_embedding = embed_model.get_text_embedding_batch([query])
projected_original_query_embedding = project_embeddings(query_embedding, umap_transform)
# 使用检索器并获取每个检索到的块的嵌入
retrievals = base_retriever.retrieve(query)
removed_text = [retrievals[i].text for i in range ( len (retrievals))]
withdraw_embedding = embed_model.get_text_embedding_batch(retrieved_text)
projected_retrieved_embeddings = project_embeddings(retrieve_embedding, umap_transfor
# 在嵌入空间中绘制投影查询和检索到的文档
plt.figure()
plt.scatter(projected_dataset_embeddings[:, 0 ], projected_dataset_embeddings[:, 1 ], s= 10 , color= 'gray' )
plt.scatter(projected_retrieved_embeddings[:, 0 ], projected_retrieved_embeddings[:, 1 ], s= 100 , facecolors= 'none' , edgecolors= 'g' )
plt.scatter(projected_original_query_embedding[:, 0 ], projected_original_query_embedding[:, 1 ], s= 150 , marker= 'X' , color= 'r' )
plt.gca().set_aspect( 'equal' , 'datalim' )
plt.title( f' {query} ' )
# 灰色是基础节点
# 红色是查询
# 绿色是检索到的块
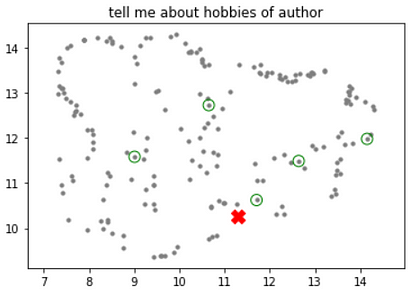
基节点、查询和检索到的块
*重新排序器*
我不确定如何或从哪里开始。下面是我们将要使用的 LLMRerank 的语法。当我们使用常规检索器时,我们通常会检索前几个值 — 比如前 5 个或前 7 个块。但是,使用重新排序器时,我们首先使用常规检索器,但现在我们检索更多的块,可能是 20 个或 25 个。随后,我们将 LLMRerank 应用于这些块以获得相关性分数。此评分由 LLM 进行,并使用所得的相关性分数来选择最高排名。
本质上,我们正在进行一个两步检索过程。首先,我们使用基于向量的方法并检索大量块。然后,我们使用 LLM 来识别相关块。因此,我们会产生额外的 LLM 调用,因此需要谨慎考虑时间和成本影响。LLM 将具有标准上下文限制,这是第一个参数**choice_batch_size*发挥作用的地方 - 此参数决定将一起处理多少个文档以获得相关性分数。参数top_n***表示我们希望从初始集合中得到的最终块数,例如 20 或 25。
从llama_index.postprocessor导入LLMRerank
A = LLMRerank(
choice_batch_size= 5 ,
top_n= 5 ,
parse_choice_select_answer_fn=custom_parse_choice_select_answer_fn)
首先,我们需要特定格式的相关分数,因此我们将以特定方式提示 LLM。有一个默认提示可用,但我不得不对其进行修改。我认为默认提示可以很好地与 openAI 配合使用,但我必须对其进行修改以进行本地实现。默认提示可以按如下方式修改 -
# 更改 LLMReranker 的默认提示
A.choice_select_prompt.template = '''[INST]<<SYS>>
您是有用的助手,根据所问查询对给定上下文的相关性进行评级。
给出从 1 到 10 的相关性分数,10 表示非常相关。无需回答问题。
如果特定文档回答了查询,则其相关性较高,否则其相关性较低。
只告诉我相关性分数.. 按从最相关到最不相关的顺序排列文档。<</SYS>>
示例问答格式 -
文档 1:<context 1>
文档 2:<context 24>
问题:<question>
答案:
文档:2,相关性:9/10
文档:3,相关性:7/10
文档:4,相关性:4/10
文档:1,相关性:3/10
严格遵循上述
格式,并按相关性降序排列文档。
即回答为 -
文档:<number>,相关性:<score>
请记住仅以上述格式回答 - 文档编号和相关性分数。没有其他内容。
仅输出如上所示的文档编号和相关性分数。--------------------------------
现在
让我们试试这个:
{context_str}
下面是问题。根据问题给出每个文档的相关性分数。
问题:{query_str}
答案:
[/INST]'''
此外,重新排序器调用的输出需要采用特定格式,但对我来说,即使这样也不正确,因此我一直收到错误。我现在使用正则表达式来捕获我得到的大多数独特情况。我们需要提取相关分数及其相应的文档编号。下面是我用来覆盖默认输出解析器的函数。
def custom_parse_choice_select_answer_fn ( answer:str, num_choices:int, raise_error= False ):
# 将答案分成几行
answer_lines = answer.split( "\n" )
answer_nums = []
answer_relevances = []
doc_pattern = r'Document (\d+)'
relevance_pattern = r'(\d+)/10'
document_numbers = []
relevance_scores = []
for line in answer_lines:
doc_match = re.search(doc_pattern, line)
if doc_match:
document_number = int (doc_match.group( 1 ))
document_numbers.append(document_number)
relevance_match = re.search(relevance_pattern, line)
if relevance_match:
relevance_score = int (relevance_match.group( 1 ))
relevance_scores.append(relevance_score)
else :
relevance_scores.append( 0 )
# print('\n--------------------')
# print(line)
print ( '\n--------------------' )
answer_nums = document_numbers
answer_relevances = relevance_scores
# 按降序对 answer_relevances 进行排序,并获取相应的排序索引
sorted_indices = sorted ( range ( len (answer_relevances)), key= lambda i: answer_relevances[i], reverse= True )
# 根据 answer_relevances 的排序索引对 answer_nums 进行排序
answer_nums = [answer_nums[i] for i in sorted_indices]
# 按降序对 answer_relevances 进行排序
answer_relevances = sorted (answer_relevances, reverse= True )
print (answer)
print (answer_nums)
print(答案相关性)
返回答案数量、答案相关性
将其放在一起 — 其中一种方法如下 —
base_retriever_2 = base_index.as_retriever(similarity_top_k= 20 )
query_bundle = QueryBundle(query)
retrievals_rerank = base_retriever_2.retrieve(query_bundle)
reranker = A
retrievals_rerank = reranker.postprocess_nodes(retrievals_rerank, query_bundle)
removed_text_rerank = [retrievals_rerank[i].text for i in range ( len (retrievals_rerank))]
withdraw_embedding_rerank = embed_model.get_text_embedding_batch(retrieved_text_rerank)
projected_retrieved_embeddings_rerank = project_embeddings(retrieve_embedding_rerank, umap_transform)
# 示例输出 -
--------------------
文档编号:[ 1 , 2 , 3 , 4 , 5 , 3 ]
相关性得分:[ 9 , 7 , 6 , 4 , 8 , 0 ]
我当然可以帮助您!根据文档中提供的信息,以下是每个文档的相关性得分:文档1:相关性得分 = 9/10文档中提到了作者的跑步经验以及他们在三小时内完成一场全程马拉松的目标。这与所提问题直接相关,因此高度相关。文档2:相关性得分 = 7/10文档中提到了作者的跑步经验以及他们在三小时内完成一场全程马拉松的目标。但是,它还包括有关作者个人生活和兴趣的信息,这些信息与所提问题不太相关。文档 3:相关性得分 = 6/10文档中提到了作者的跑步经验以及他们在三小时内完成一场全程马拉松的目标。但是,它还包含作者的个人生活和兴趣信息,与所提问题不太相关。文档 4:相关性得分 = 4/10文档未提及任何与作者的跑步经历或全程马拉松时间相关的内容,因此与所提问题不太相关。文档5 :相关性得分 = 8/10
文档中提到了作者的跑步经历以及他们在三小时内完成全程马拉松的目标。它还包括作者的个人生活和兴趣信息,这些信息与所提问题不太相关。
总体而言,文档1 和 5与所提问题最相关,其次是文档3。
[ 1 , 5 , 2 , 3 , 4 , 3 ]
[ 9 , 8 , 7 , 6 , 4 , 0 ]
# 注意:文档3
存在重复问题,因此存在改进的空间。
# 在嵌入空间中绘制投影查询和检索到的文档
plt.figure(figsize=( 12 , 6 ))
# 原始查询和检索到的嵌入的子图
plt.subplot( 1 , 2 , 1 )
plt.scatter(projected_dataset_embeddings[:, 0 ], projected_dataset_embeddings[:, 1 ], s= 10 , color= 'gray' )
plt.scatter(projected_retrieved_embeddings[:, 0 ], projected_retrieved_embeddings[:, 1 ], s= 100 , facecolors= 'none' , edgecolors= 'g' )
plt.scatter(projected_original_query_embedding[:, 0 ], projected_original_query_embedding[:, 1 ], s= 150 , marker= 'X' , color= 'r' )
plt.gca().set_aspect( 'equal' , 'datalim' )
plt.title( '原始查询和检索到的嵌入' )
# 增强查询嵌入的子图
plt.subplot( 1 , 2 , 2 )
plt.scatter(projected_dataset_embeddings[:, 0 ], projected_dataset_embeddings[:, 1 ], s= 10 , color= 'gray' )
plt.scatter(projected_retrieved_embeddings_rerank[:, 0 ], projected_retrieved_embeddings_rerank[:, 1 ], s= 100 , facecolors= 'none' , edgecolors= 'g' )
plt.scatter(projected_original_query_embedding[:, 0 ], projected_original_query_embedding[:, 1 ], s= 150 , marker= 'X' , color= 'r' )
plt.gca().set_aspect( 'equal' , 'datalim' )
plt.title( '重新排序的原始查询和检索到的嵌入' )
plt.tight_layout()
plt.show()
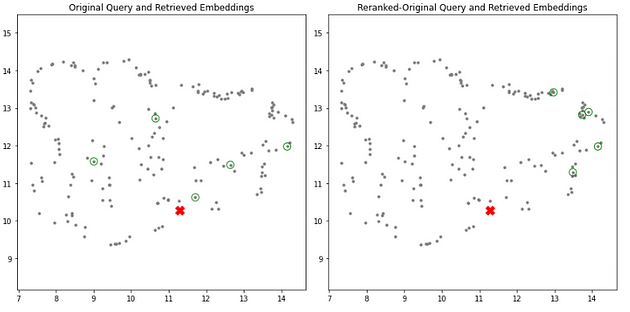
左侧是基本检索,右侧是 ReRanker,您可以观察到我们获得了一组不同的块作为输出。现在,根据 LLM 准确度和提示,第二个块应该更胜一筹。然而,我观察到,最终响应在重新排名时并不总是很好——这可能是因为我的查询将数据集中在一个区域。理想情况下,我们应该有一组多样化的文档和查询,它们需要来自文档各个部分的块。
欢迎您使用代码并尝试不同的查询和提示。此外,在笔记本中,我还包含了一些其他方法。我现在将演示如何将 ReRanker 与我们的查询一起使用,然后最终获得响应。此外,我修改了我们的 LLM 的默认提示并将其传递给查询引擎。由于我们使用相同的 LLM 进行重新排名和最终答案生成,因此我为 ReRanker 提供了一个单独的提示,如上所示。下面,我将说明如何将修改后的提示传递给查询引擎,该引擎将用于生成最终答案。
# 修改默认提示以适合Llama 2 模板
new_summary_tmpl_str = (
'''[INST]<<SYS>> 给出了一堆上下文文本并询问您一个查询。\
根据文档回答查询,不要引入外部知识。\
要精确、简洁、清晰。<</SYS>>\n
以下是来自多个来源的上下文信息。\n
---------------------\n
{context_str}\n
---------------------\n
根据来自多个来源的信息而不是先前知识,回答查询。\n
查询:{query_str}\n
答案:\n
[/INST]'''
)
new_summary_tmpl = PromptTemplate(new_summary_tmpl_str)
query = '作者去过哪些城市?获取所有提到的城市名称。'
# 非重新排序答案和嵌入
query_engine = base_index.as_query_engine(similarity_top_k= 5 ,
response_mode= "tree_summarize" )
query_engine.update_prompts(
{ "response_synthesizer:summary_template" : new_summary_tmpl}
)
response = query_engine.query(query)
retrievals = response.source_nodes
removed_text = [retrievals[i].text for i in range ( len (retrievals))]
withdraw_embedding = embed_model.get_text_embedding_batch(retrieved_text)
projected_retrieved_embeddings = project_embeddings(retrieve_embedding, umap_transform)
# 基于重新排序的响应
query_engine = base_index.as_query_engine(
similarity_top_k= 20 ,
node_postprocessors=[A], # A 是我们上面使用的重新排序器
response_mode= "tree_summarize" ,
)
query_engine.update_prompts(
{ "response_synthesizer:summary_template" : new_summary_tmpl}
)
response_reranked = query_engine.query(query)
retrievals_rerank = response_reranked.source_nodes
removed_text_rerank = [retrievals_rerank[i].text for i in range ( len (retrievals_rerank))]
withdraw_embedding_rerank = embed_model.get_text_embedding_batch(retrieved_text_rerank)
projected_retrieved_embeddings_rerank = project_embeddings(retrieve_embedding_rerank, umap_transform)
# 一起绘制
# 绘制嵌入中的投影查询和检索到的文档空间
plt.figure(figsize=( 12 , 6 ))
# 原始查询和检索到的嵌入的子图
plt.subplot( 1 , 2 , 1 )
plt.scatter(projected_dataset_embeddings[:, 0 ], projected_dataset_embeddings[:, 1 ], s= 10 , color= 'gray' )
plt.scatter(projected_retrieved_embeddings[:, 0 ], projected_retrieved_embeddings[:, 1 ], s= 100 , facecolors= 'none' , edgecolors= 'g' )
plt.scatter(projected_original_query_embedding[:, 0 ], projected_original_query_embedding[:, 1 ], s= 150 , marker= 'X' , color= 'r' )
plt.gca().set_aspect( 'equal' , 'datalim' )
plt.title( '原始查询和检索到的嵌入' )
# 增强查询嵌入的子图
plt.subplot( 1 , 2 , 2 )
plt.scatter(projected_dataset_embeddings[:, 0 ], projected_dataset_embeddings[:, 1 ], s= 10 , color= 'gray' )
plt.scatter(projected_retrieved_embeddings_rerank[:, 0 ], projected_retrieved_embeddings_rerank[:, 1 ], s= 100 , facecolors= 'none' , edgecolors= 'g' )
plt.scatter(projected_original_query_embedding[:, 0 ], projected_original_query_embedding[:, 1 ], s= 150 , marker= 'X' , color= 'r' )
plt.gca().set_aspect( 'equal' , 'datalim' )
plt.title( '重新排序的原始查询和检索到的嵌入' )
plt.tight_layout()
plt.show()
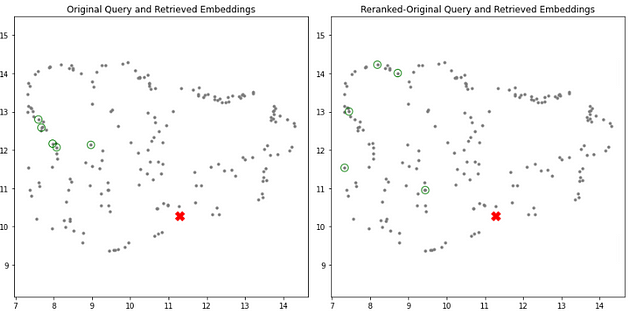
# 输出
告诉我作者的爱好
------------------------
非重新排序者回应
根据提供的文本,作者曾经去过以下城市:
1.孟买
2.本地治里
3.金奈
4.罗纳瓦拉
5.孟买(两次)
6.孟买(两次)
7.浦那
注意:作者在文中提到过这些城市,但不清楚他们是否亲自去过所有这些城市,或者只是在文中提到过这些城市。
------------------------
重新排序者的回应
根据所提供的文本,作者曾经去过以下城市:
1.班加罗尔
2.金奈
3.孟买
4.本地治里
5.马辛德拉世界城
6.祖卡(提到是一家巧克力店)
7.海滨长廊
8.马哈巴利普拉(提到是一家午餐地点)
文中提到的这些城市是作者在旅行期间访问过或经过的地方。
对于某些查询,我使用重新排序可以获得更好的结果,但对于某些查询,结果则更糟:D
现在,我将用一些评论来结束本文 —
- 提示在这里再次成为关键
- 我们可以使用 UMAP 来了解我们的数据和检索
- 我们需要将其与从小到大的检索、句子窗口解析器和许多其他技术联系起来。
请留意此处以获取更多代码块。
注意:作者在文中提到过这些城市,但不清楚他们是否亲自去过所有这些城市,或者只是在文中提到过这些城市。
重新排序者的回应
根据所提供的文本,作者曾经去过以下城市:
1.班加罗尔
2.金奈
3.孟买
4.本地治里
5.马辛德拉世界城
6.祖卡(提到是一家巧克力店)
7.海滨长廊
8.马哈巴利普拉(提到是一家午餐地点)
文中提到的这些城市是作者在旅行期间访问过或经过的地方。
对于某些查询,我使用重新排序可以获得更好的结果,但对于某些查询,结果则更糟
- 提示在这里再次成为关键
- 我们可以使用 UMAP 来了解我们的数据和检索
- 我们需要将其与从小到大的检索、句子窗口解析器和许多其他技术联系起来。
请留意此处以获取更多代码块。
代码 — https://github.com/SandyShah/llama_index_experiments
博客原文:专业人工智能社区

















 171
171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









