






实现高级 Agentic 向量搜索:CrewAI 和 Qdrant 综合指南
这篇文章与我之前的所有文章相比都显得与众不同。它探讨了人工智能代理团队的概念,该团队可以自主执行任务,代表我们做出决策。这篇文章强调了人工智能“代理”的强大能力及其无限潜力。
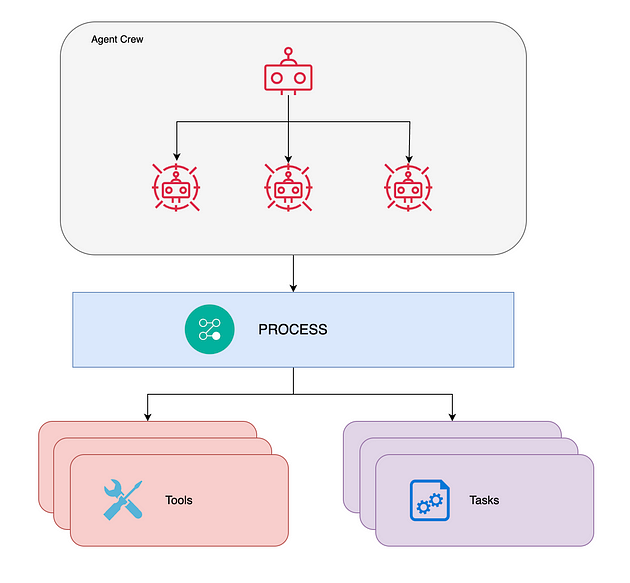
一个代理 AI 团队,能够使用一套工具自主工作以完成给定的任务。由作者 MK Pavan Kumar 创建。
什么是 AI 代理和代理应用程序?
AI 代理是可以代表用户做出决策并执行任务的自主系统。它们被设计为独立行动,通常在动态和不可预测的环境中。这些代理使用人工智能来处理信息、从经验中学习并执行与预定义目标或目的一致的操作。AI 代理的范围可以从执行自动任务的简单软件程序到机器人或自动驾驶汽车等复杂系统。
代理应用是指 AI 代理在各个领域的实际实现。这些应用利用 AI 代理的自主和决策能力来提高效率和效力,并提供可能需要人工干预的解决方案。在本文中,我们将看到一个完全自主的代理应用,它将执行向量搜索并检索与用户相似的文档。
什么是 CrewAI?
CrewAI 是一个尖端框架,旨在实现 AI 代理之间的复杂交互。CrewAI 中的每个代理都具有不同的角色和目标,使他们能够在先进的网络中执行任务并有效协作。这种结构类似于现实生活中的团队,每个成员都贡献特定的技能和见解来实现共同的目标,但具有只有 AI 才能提供的无与伦比的可扩展性和效率。这个框架代表的不仅仅是另一个 AI 系统;它是一种协调角色扮演、自主 AI 代理的变革性方法,这些代理可以共同应对复杂的挑战,将其定位为开发人员和企业的关键资源。
工具:在 CrewAi 中,工具被定义为代理用来高效执行特定任务的实用工具或设备。这些工具是系统功能不可或缺的一部分,可实现诸如网络搜索、文档加载和处理等操作。CrewAi 建立在 LangChain 框架上,允许集成现有的 LangChain 工具或开发针对特定需求的自定义工具。
任务:任务组件是指需要在 CrewAi 框架内执行的具体活动。每个任务都分配给一个代理,代理利用可用的工具有效地完成任务。
代理:CrewAi 中的代理类似于团队成员,每个代理都有独特的角色、背景故事和目标。这些代理是任务的主要执行者,并构建为 LangChain 代理。它们通过 ReActSingleInputOutputParser 得到增强*,*它支持角色扮演,使用绑定停用词来保持上下文焦点,并集成记忆机制 ( ConversationSummaryMemory ) 来跟踪上下文。
Crew:CrewAi 中的 Crew 是一群为实现共同目标而共同协作的智能体。Crew 中的智能体具有明确定义的协作方法,可以有效完成分配的任务。
流程:流程定义了机组执行任务所遵循的工作流程或策略。CrewAi 目前支持三种策略:
- 顺序:此策略涉及按指定顺序执行任务,非常适合每个任务都依赖于前一个任务的完成的管道工作流。
- 层次化:在此策略中,任务基于层次结构进行组织和执行,类似于编排模式。任务通过命令链进行委派和管理,通常涉及主管以确保优化决策。
故事
在本文中,我们的目标是创建一个**Qdrant 团队,**它将矢量化给定的查询并在 Qdrant 数据库上运行搜索查询以查找类似的文档。使用的技术堆栈。
- Qdrant 作为文档存储
- Ollama 用于嵌入模型
- CrewAI 用于协调 AI 代理
实施:
以下是架构的实现
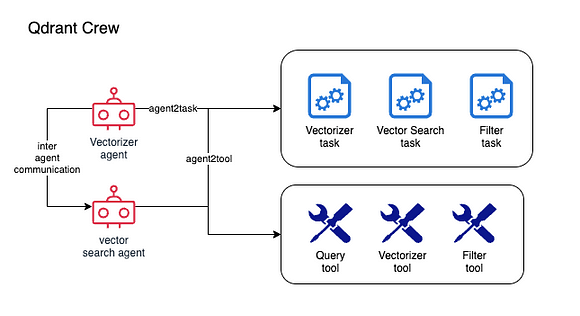
由作者 MK Pavan Kumar 创作
项目脚手架如下所示。该项目可以扩展以适应您预期的负载,因为它也可以在 Kubernetes 环境中进行容器化和扩展。
首先让我们查看一下.env所有 URL 和 API 密钥的文件
LOCAL_EMBEDDINGS = “http://localhost:11434/api/embeddings”
LOCAL_EMBEDDINGS_MODEL = “snowflake-arctic-embed:33m”
QDRANT_LOCAL = “http://localhost:6333”
QDRANT_COLLECTION_NAME = “qdrant-docs”
OPENAI_API_KEY = “sk-<你的密钥>”
OPENAI_LLM = “gpt-4-turbo-2024-04-09”
首先让我们看一下工具/core/Tools.py
从 typing 导入列表
从 crewai_tools 导入工具
从 qdrant_client 导入 QdrantClient
从 qdrant_client.http.models 导入 ScoredPoint、SearchParams
从 dotenv 导入 load_dotenv、find_dotenv
导入请求
导入 os
class QdrantTools:
_ = load_dotenv(find_dotenv())
# 创建 Qdrant 客户端实例
client = QdrantClient(url = os.getenv(“QDRANT_LOCAL”))
@staticmethod
@tool(“vectorize_query”)
def vectorize_query(query: str)-> str:
“” “这是一个用于矢量化给定查询的工具” “”
url = os.getenv(“LOCAL_EMBEDDINGS”)
payload = {
“model”:os.getenv(“LOCAL_EMBEDDINGS_MODEL”),
“prompt”:query
}
headers = { “Content-Type”:“application/json” } response = request.post(url,json=payload,headers= headers
)
return response.json()@staticmethod @tool(“search_qdrant”)def search_qdrant(vector: List)-> str: "" " 这是一个用来从 qdrant 数据库中获取相似向量的工具" "" # 创建搜索请求结果: list[ScoredPoint] = QdrantTools.client.search( collection_name=os.getenv( "QDRANT_COLLECTION_NAME" ), query_vector=vector, search_params=SearchParams(hnsw_ef= 128 , exact=False), limit= 2 # 最近向量的数量 )返回结果
vectorize_query类中的方法旨在QdrantTools使用外部嵌入服务将文本查询转换为数字向量。它首先从环境变量中检索 URL 和模型详细信息,这些变量指定了嵌入的生成位置和生成方式。该方法使用这些详细信息和输入查询构建 JSON 负载,并通过 POST 请求将其发送到指定的嵌入服务。响应应为 JSON 格式,包含查询的矢量化形式,并由该方法返回。
第二种方法search_qdrant,使用 生成的向量vectorize_query在 Qdrant 数据库中搜索相似的向量。它在 Qdrant 客户端中初始化搜索请求,指定要搜索的集合、查询向量和其他搜索参数,例如要检索的最近向量的数量和搜索算法的设置。此搜索的结果是基于内置Qdrant's相似性指标的最接近输入向量的向量列表,然后返回该列表。此方法有效地允许检索数据库中与给定查询最相似的条目,从而促进推荐或重复检测等任务。
现在让我们看看/core/Tasks.py
从core.Agents导入QdrantAgents
从crewai导入Task
类 QdrantTasks:
def __init__(self):
self.qdrant_agents = QdrantAgents()
def vectorize_prompt_task(self,agent,prompt):
返回Task(
description =(
f“识别{prompt}并返回相应{prompt}的向量嵌入”
),
expected_output = “带有向量嵌入的 json 数组对象,响应示例如下 \n”
[-0.09073494374752045,-0.22729796171188354,-0.2276609241962433,0.2960631847381592]。”,
agent = agent
)
def vector_search_task(self,agent):
返回Task(
description =(
“识别顶部2 使用来自上一个任务的嵌入从数据库中获取相似的数据。"
),
expected_output= "具有相似向量及其相关分数的 json 对象" ,
agent=agent
)
vectorize_prompt_task类中的方法旨在QdrantTasks创建和配置一个任务,该任务旨在使用来自的代理将给定提示转换为向量嵌入QdrantAgents。此方法利用库Task中的对象crewai来指定任务的参数,其中包括任务描述和预期输出格式。描述清楚地表明代理将识别提示并生成其向量嵌入,而预期输出定义为包含向量值的 JSON 数组。此设置使代理能够遵循结构化和清晰的指令,以实现预期结果。
该vector_search_task方法设置了一个任务,用于根据先前任务生成的向量嵌入在数据库中搜索最相似的数据条目。此方法还创建一个Task对象,指定任务的目的和预期输出。该描述指导代理使用嵌入从数据库中查找并返回前两个最相似的向量。预期输出详细说明为 JSON 对象,其中包括相似向量及其相关的相似度分数。此方法有助于集成顺序任务,其中一个任务(向量嵌入)的输出用作另一个任务(搜索操作)的输入,从而提高工作流效率。
现在让我们看看/core/Agents.py
从crewai导入Agent
从langchain_openai导入ChatOpenAI
从core.Tools导入QdrantTools
从dotenv导入load_dotenv、find_dotenv
导入o s
类 QdrantAgents:
def __init__(self):
_ = load_dotenv(find_dotenv())
os.environ[ “OPENAI_API_KEY” ] = os.getenv(“OPENAI_API_KEY”)#platform.openai 密钥
self.llm = ChatOpenAI(model=os.getenv(“OPENAI_LLM”),temperature= 0.3)
def vectorizer_agent(self,prompt):
返回Agent(
role= '对任何给定的查询 pod 名称代理进行矢量化',
goal= f'获取给定{prompt}的向量嵌入',
verbose= True,
memory= True,
backstory=(
f“作为具有 qdrant 矢量数据库专业知识的高级矢量数据库工程师代理” f“您的工作是将给定的{prompt}
转换为向量嵌入。”
),
tools=[QdrantTools.vectorize_query],
allow_delegation= True,
llm=self.llm
)
def vector_search_agent(self):
return Agent(
role= “向量搜索代理”,
goal= “在 qdrant 向量存储中搜索给定的向量嵌入”,
verbose= True,
memory= True,
backstory=(“您需要搜索 qdrant 向量数据库以获取前 2 个相似数据”
“通过使用来自前一个代理的嵌入”),
tools=[QdrantTools.search_qdrant],
allow_deligation= False,
llm=self.llm
)
该类使用环境变量进行初始化,并使用库中的类QdrantAgents设置两种不同类型的代理。在构造函数()中,它加载环境变量以确保 API 密钥和其他必要设置到位。它还使用特定参数创建一个实例,设置语言处理的模型和温度,该实例充当代理在其任务中使用的低级管理器(LLM)。Agent``crewai``__init__``ChatOpenAI
该vectorizer_agent方法配置了一个用于矢量化文本提示的代理。该代理被赋予了特定的角色和目标,包括获取所提供提示的矢量嵌入。该方法为代理设置了详细程度、记忆力和背景故事等属性,以强调代理在矢量数据库工程方面的专业知识。它配备了一个工具(QdrantTools.vectorize_query)来执行矢量化任务,并允许代理在必要时委派任务,利用早期实例llm进行语言理解和处理。
该vector_search_agent方法设置了另一个代理,其角色是根据给定的向量嵌入在 Qdrant 数据库中搜索相似的数据向量。该代理的目标是从向量存储中检索前两个相似的数据条目,并配置了相关属性,如详细程度和内存。它的背景故事为使用来自前一个代理的嵌入来执行搜索的任务做好了准备。代理使用该QdrantTools.search_qdrant工具执行搜索,并设置为不允许委托,依靠自己的能力和llm高效处理搜索任务。
现在我们来看一下。/agentic_vector_search.py
从core.Agents导入QdrantAgents
从core.Tasks导入QdrantTasks
从crewai导入Crew、Process
从phoenix.trace.langchain导入LangChainInstrumentor
导入phoenix作为px
导入警告
warnings.filterwarnings( 'ignore' )
session = px.launch_app()
LangChainInstrumentor().instrument()
qdrant_agents = QdrantAgents()
qdrant_tasks = QdrantTasks()
prompt = ( '这就是准确性最重要之处。在本例中,'
'Qdrant 在提供出色的搜索结果方面表现不俗。' )
vectorizer_agent = qdrant_agents.vectorizer_agent(prompt=prompt)
vector_search_agent = qdrant_agents.vector_search_agent()
# 通过一些增强配置组建以技术为中心的团队
crew = Crew(
agent=[vectorizer_agent, vector_search_agent],
task=[qdrant_tasks.vectorize_prompt_task(agent=vectorizer_agent, prompt=prompt),
qdrant_tasks.vector_search_task(agent=vector_search_agent)],
process=Process.sequence, # 可选:顺序任务执行为默认
memory= True ,
cache= True ,
max_rpm= 100 ,
share_crew= True
)
# 启动带增强反馈的任务执行流程
def crew_start ():
result = crew.kickoff()
print (px.active_session().url)
print (result)
提供的代码片段集成了各种组件,以在可能利用 Crew AI 概念的框架内使用 AI 代理、任务和流程来编排任务序列。最初,它导入必要的模块并通过抑制警告和启动会话来设置环境。应用了px.launch_app()来自的仪器,可能用于调试或跟踪目的。phoenix.trace.langchain
核心功能围绕创建QdrantAgents和的实例展开QdrantTasks,它们处理特定的 AI 驱动操作。配置了两个代理:一个用于矢量化给定的提示,另一个用于在数据库中搜索向量嵌入。这些代理的相应任务在和中定义,QdrantTasks旨在首先矢量化提示,然后使用结果嵌入在 Qdrant 数据库中查找类似的条目。这些任务被组织成一个,Crew它设置为按顺序执行这些任务,由进程类型指示。此设置强调效率和同步,因为任务按定义的顺序处理,并且指定了内存、缓存和共享资源等其他配置以优化性能。最后,用启动序列crew.kickoff(),并输出结果以及会话 URL,以跟踪操作的进度和结果。
整个机组可以通过 API 驱动的方式进行控制,这使得 Agentic 机组从某个角度来看更加强大和强大,payload因为load有效载荷可以动态传递,并且整个机组都可以进行 docker 化并部署到 Kubernetes。
可以将提示‘That is where the accuracy matters the most. And in this case, ‘Qdrant has proved just commendable in giving excellent search results.’变为动态的,并使用 API 有效负载从用户处获取提示,如下节所述。
./main.py讨论如何创建简单的端点来触发船员
从fastapi导入FastAPI
从dotenv导入load_dotenv、find_dotenv
从agentic_vector_search导入crew_start
导入日志记录
导入os
_ = load_dotenv(find_dotenv())
logs.basicConfig(level=logging.INFO)
如果os.getenv( "DEBUG_LOG_LEVEL" ) == "true" :
logs.basicConfig(level=logging.DEBUG)
app = FastAPI()
@app.get( "/crew-kickoff" )
def crew_kickoff ():
crew_start()
.Dockerfile为我们指明了将整个 Creation 应用程序容器化的方向。
来自 python:3-alpine3.19
运行mkdir /code
WORKDIR /code
复制 requirements.txt .
运行 pip install -r requirements.txt
复制 . .
CMD [ "uvicorn","main:app","--host=0.0.0.0","--port=3001" ]
现在让我们看看这个船员应用程序的实际运行情况。
我已将文档从 Qdrant 中默认提供的标准数据集加载到名为qdrant-docs
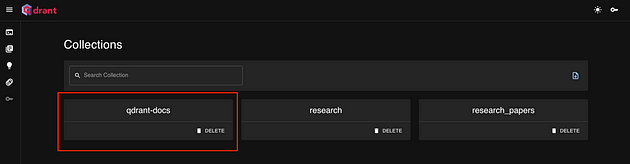
现在,如果您使用 API 触发工作人员,则响应如下。

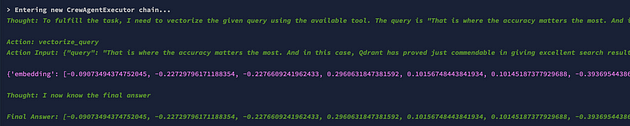

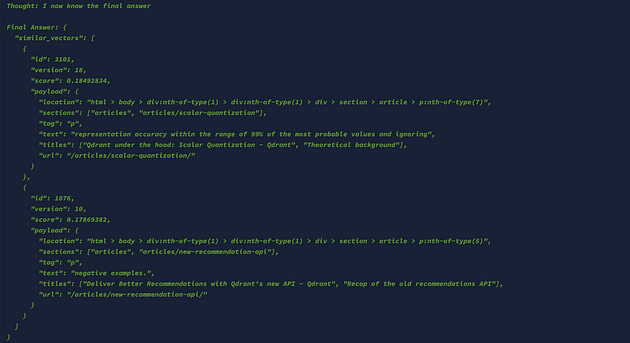
结论:
总之,CrewAI 框架代表了在协调 AI 代理之间的交互以有效解决复杂任务方面取得的重大进步。通过利用专门的代理进行矢量化和矢量搜索Qdrant database,CrewAI 展示了 AI 在数据密集型环境中简化流程和改善结果的潜力。使用特定于环境的工具和顺序任务执行进一步提高了系统的效率。
结论:
总之,CrewAI 框架代表了在协调 AI 代理之间的交互以有效解决复杂任务方面取得的重大进步。通过利用专门的代理进行矢量化和矢量搜索Qdrant database,CrewAI 展示了 AI 在数据密集型环境中简化流程和改善结果的潜力。使用特定于环境的工具和顺序任务执行进一步提高了系统的效率。
展望未来,下一步将探索更多任务执行策略,例如分层处理,以适应更复杂的决策场景。此外,使用更先进的自然语言处理工具完善代理的能力,并扩展其在不同领域的应用(假设 Kubernetes 的代理团队并将其扩展到开发运营),可以提供更大的多功能性和实用性。这些创新方法的持续开发和集成将继续突破人工智能驱动的协作框架所能实现的界限
博客原文:专业人工智能技术社区















 149
149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









