






智能助手实时异常检测使用 Amazon Kinesis Data Firehose 和 Analytics 获取实时见解
A异常检测是数据处理中的一项关键任务,尤其是处理流数据时。随着实时生成的数据越来越多,检测任何可能表明存在问题或机会的异常模式或异常值非常重要。
传统的批处理方法无法跟上现代应用程序生成的流数据的数量、速度和多样性。这就是持续分析发挥作用的地方。
持续分析是现代数据处理的重要组成部分,尤其是在实时分析流数据时。随着物联网 (IoT) 的发展,持续分析的需求变得更加关键,因为需要实时分析这些设备生成的数据以检测任何异常或趋势。
今天我们将讨论如何使用Amazon Kinesis Data Firehose和Amazon Kinesis Data Analytics Application (KDA) 近乎实时地检测数据流中的异常。
Amazon Kinesis Data Firehose:流数据管道
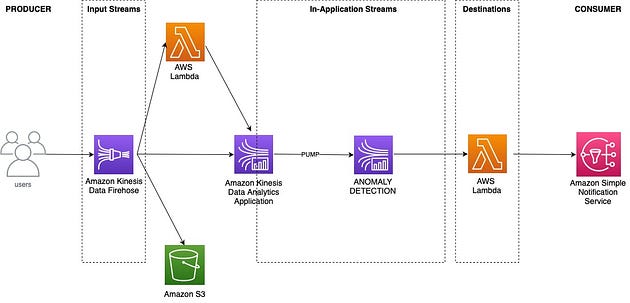
Amazon Kinesis Data Firehose 是一项完全托管的服务,可让您捕获、转换和加载来自各种来源(例如数据库、日志文件、社交媒体平台和 IoT 设备)的流数据到 Amazon S3、Amazon Redshift 和 Amazon Elasticsearch Service 等目标。使用 Amazon Kinesis Data Firehose,您无需编写任何代码即可构建或维护自定义管道。您只需指定流数据的来源、定义转换规则并配置目标终端节点即可。
Amazon Kinesis Data Analytics 应用程序:流数据的实时分析
通过 Amazon Kinesis Data Firehose 将流数据导入 Amazon S3 后,可以使用 Amazon Kinesis Data Analytics 应用程序进一步实时分析。KDA 是一种可扩展且持久的服务,可帮助您分析大量流数据。它使您能够实时连续处理数据流并发现模式、相关性、趋势、异常值和其他见解。KDA 提供内置函数,用于在数据流到达时对其进行筛选、映射、聚合、扩展和丰富,使您能够直接在服务本身内对原始数据执行复杂的计算。
Amazon Kinesis Data Firehose 和 Amazon Kinesis Data Analytics 是两种服务,可与Amazon Simple Notification Service等服务一起使用,以对流数据进行持续分析。
以下是高级系统设计:
先决条件:
- 访问 AWS 账户及其服务
- 一些 Python 和 SQL 知识
- 对基础设施和机器学习有一定的了解
概括:
- 首先,我们将设置必要的 IAM 和所需的角色
- 然后我们将创建一个 lambda 函数,它将从 Firehose 获取输入并返回一个预测
- 现在我们将创建一个 Firehose 传输流
- 以及 Lambda SNS函数
- 在此步骤中,我们将创建 Kinesis 数据分析应用程序
- 最后,我们将记录放入 Data Firehose
- 我们将审查并发布资源
以下是具体操作方法:
0.数据集
所有机器学习解决方案都从数据集开始。
不是这个。
这里我主要关注系统架构,因为我觉得很多新工程师缺乏这种技能。
因此,我们将在需要的地方插入虚拟数据集。对于我们的问题,我们将异常定义为负面的用户情绪。
因此,如果我们从输入的评论文本中检测到用户的情绪是积极的,那么这对我们的系统来说并不是异常。我们只会针对负面情绪/标签/评论/输出创建通知。
1. 设置
在此项目中设置 IAM(身份和访问管理)和权限非常重要。由于AWS 采用零信任安全模型,因此必须创建具有有限权限的 IAM 角色,以允许用户仅执行特定任务,例如训练模型或部署终端节点。
通过设置 IAM 策略和权限,您可以控制谁有权访问您的 Amazon SageMaker 资源,例如笔记本、数据、模型和终端节点。您可以指定用户或应用程序可以在什么条件下对这些资源执行哪些操作。我建议对所有用户进行最低权限访问,并定期清除未使用的资源的用户权限。
导入json
导入时间
导入boto3
导入pandas作为pd
导入sagemaker
从botocore.exceptions导入ClientError
sess = sagemaker.Session()
bucket = sess.default_bucket()
role = sagemaker.get_execution_role()
region = boto3.Session().region_name
sts = boto3.Session().client(service_name= "sts" , region_name=region)
iam = boto3.Session().client(service_name= "iam" , region_name=region)
lam = boto3.Session().client(service_name= "lambda" , region_name=region)
firehose = boto3.Session().client(service_name= "firehose" , region_name=region)
sns = boto3.Session().client(service_name= "sns" , region_name=region)
kinesis_analytics = boto3.Session().client(
服务名称= “kinesisanalytics”,区域名称=区域
)
让我们创建一个 Kinesis 角色:
请注意,角色和函数名称中的
ADOAWS_ ***** **后缀代表AWS上****的异常检测**
iam_kinesis_role_name = “ADOAWS_Kinesis”
assume_role_policy_doc = {
“版本”:“2012-10-17”,
“声明”:[
{
“效果”:“允许”,
“主体”:{ “服务”:“kinesis.amazonaws.com” },
“操作”:“sts:AssumeRole”,
},
{
“效果”:“允许”,
“主体”:{ “服务”:“firehose.amazonaws.com” },
“操作”:“sts:AssumeRole”,
},
{
“效果”:“允许”,
“主体”:{ “服务”:“kinesisanalytics.amazonaws.com” },
“操作”:“sts:AssumeRole”,
},
],
}
尝试:
iam_role_kinesis = iam.create_role(
RoleName = iam_kinesis_role_name,
AssumeRolePolicyDocument = json.dumps(assume_role_policy_doc),
Description = “DSOAWS Kinesis Role”,
)
打印(“角色成功创建。”)
除了ClientError作为e:
如果e.response [ “Error” ] [ “Code” ] == “EntityAlreadyExists”:
iam_role_kinesis = iam.get_role(RoleName = iam_kinesis_role_name)
打印(“角色已经存在。”)
其他:
打印(“意外错误:%s”%e)
time.sleep(30)
iam_role_kinesis_name = iam_role_kinesis [ “Role” ] [ “RoleName” ]
打印(f“角色名称:{iam_role_kinesis_name} " )
iam_role_kinesis_arn = iam_role_kinesis[ "角色" ][ "Arn" ]
打印( f"角色 ARN: {iam_role_kinesis_arn} " )
account_id = sts.获取呼叫者身份 ()[ “账户” ]
成功执行后,您应该看到如下所示的输出。

成功响应
给你的流命名:
stream_name = “adows-kinesis-data-stream”
消防水带名称:
firehose_name = “dsoaws-kinesis-data-firehose”
将连接到Amazon SNS的 Lambda 函数名称:
lambda_fn_name_sns = “推送通知到SNS”
创建 Kinesis 策略:
kinesis_policy_doc = {
“版本”:“2012-10-17”,
“声明”:[
{
“效果”:“允许”,
“操作”:[
“s3:AbortMultipartUpload”,
“s3:GetBucketLocation”,
“s3:GetObject”,
“s3:ListBucket”,
“s3:ListBucketMultipartUploads”,
“s3:PutObject”,
],
“资源”:[ f“arn:aws:s3 :: {bucket} ”,f“arn:aws:s3 :: {bucket} / *” ],
},
{
“效果”:“允许”,
“操作”:[ “logs:PutLogEvents” ],
“资源”:[ f“arn:aws:logs:{region}:{account_id}:log-group:/*” ],
},
{
“效果”:“允许”,
“操作”:[
“kinesis:*”,
],
“资源”:[ f“arn:aws:kinesis:{region}:{account_id}:stream / {stream_name} ” ],
},
{
“效果”:“允许”,
“操作”:[
“firehose:*”,
],
“资源”:[
f“arn:aws:firehose:{region}:{account_id}:deliverystream / {firehose_name} ”
],
},
{
“效果”:“允许”,
“操作”:[
“kinesisanalytics:*”,
],
“资源”:[ “*” ],
},
{
“Sid”:“UseLambdaFunction”,
“效果”:“允许”,
“操作”:[ “lambda:InvokeFunction”,“lambda:GetFunctionConfiguration” ],
“资源”:[ “*” ],
},
{
“效果”:“允许”,
“操作”:“iam:PassRole”,
“资源”:[“arn:aws:iam :: *:role / service-role / kinesis *” ],
},
],
}
响应= iam.put_role_policy(
RoleName = iam_role_kinesis_name,
PolicyName = “ ADOAWS_KinesisPolicy”,
PolicyDocument = json.dumps(kinesis_policy_doc),
)
time.sleep(30)
打印(json.dumps(响应,缩进= 4,sort_keys = True,默认= str))
您可以根据需要随意更改“region”和“bucket”等变量。我在 Sagemaker Studio 上创建了此代码,因此它将在 S3 中使用默认的 Sagemaker bucket。
(您可以在设置部分更改存储桶)

创建 Lambda IAM 角色:
iam_lambda_role_name = “ADOAWS_Lambda”
assume_role_policy_doc = {
“版本”:“2012-10-17”,
“声明”:[
{
“效果”:“允许”,
“委托人”:{ “服务”:“lambda.amazonaws.com” },
“操作”:“sts:AssumeRole”,
},
{
“效果”:“允许”,
“委托人”:{ “服务”:“kinesisanalytics.amazonaws.com” },
“操作”:“sts:AssumeRole”,
},
],
}
尝试:
iam_role_lambda = iam.create_role(
RoleName = iam_lambda_role_name,
AssumeRolePolicyDocument=json.dumps(assume_role_policy_doc),
Description= "ADOAWS Lambda Role" ,
)
print ( "角色创建成功。" )
except ClientError as e:
if e.response[ "Error" ][ "Code" ] == "EntityAlreadyExists" :
iam_role_lambda = iam.get_role(RoleName=iam_lambda_role_name)
print ( "角色已存在" )
else :
print ( "意外错误:%s" % e)
time.sleep( 30 )
iam_role_lambda_name = iam_role_lambda[ "Role" ][ "RoleName" ]
print ( f"角色名称:{iam_role_lambda_name} " )
iam_role_lambda_arn = iam_role_lambda[ "角色" ][ "Arn" ]
打印(f"角色 ARN: {iam_role_lambda_arn} ")

成功响应
将 AWS Lambda 策略附加到您上面创建的 IAM 角色:
lambda_policy_doc = {
“版本”:“2012-10-17”,
“声明”:[
{
“Sid”:“UseLambdaFunction”,
“效果”:“允许”,
“操作”:[ “lambda:InvokeFunction”,“lambda:GetFunctionConfiguration” ],
“资源”:f“arn:aws:lambda:{region}:{account_id}:function:*”,
},
{ “效果”:“允许”,“操作”:“cloudwatch:*”,“资源”:“*” },
{ “效果”:“允许”,“操作”:“sns:*”,“资源”:“*” },
{
“效果”:“允许”,
“操作”:“日志:CreateLogGroup”,
“资源”:f“arn:aws:日志:{region}:{account_id}:*”,
},
{ “效果”:“允许”,“操作”:“sagemaker:InvokeEndpoint”,“资源”:“*” },
{
“效果”:“允许”,
“操作”:[ “日志:CreateLogStream”,“日志:PutLogEvents” ],
“资源”:f“arn:aws:日志:{region}:{account_id}:log-group:/aws/lambda/*”,
},
],
}
response = iam.put_role_policy(
RoleName = iam_role_lambda_name,
PolicyName = “ADOAWS_LambdaPolicy”,
PolicyDocument=json.dumps(lambda_policy_doc),
)
time.sleep( 30 )
打印(json.dumps(response, indent= 4 , sort_keys= True , default= str ))

现在我们已经设置了所需的权限。如果您遇到任何错误,可能是因为您的 IAM 没有这些资源的权限。
在这种情况下,您可以逐步添加权限并尝试使其正常工作,或者添加上述资源的所有权限并逐一清除它们,直到它崩溃。选择权在您手中 🤪
2. 创建 Lambda 以返回预测
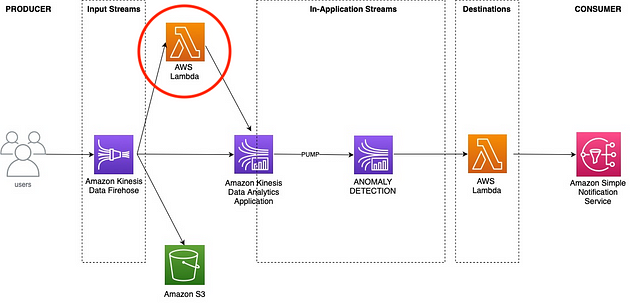
创建第一个 Lambda 函数
Firehose 中的记录将发送到此 Lambda 进行预测。预测后,我们将它发送到 Kinesis Analytics 应用程序进行异常检测。
如果 Kinesis Analytics 应用程序检测到异常,则它将触发另一个 lambda,将通知推送到 Amazon SNS(可能在凌晨 3 点😮💨)
为了在这个 Lambda 中进行预测,我们可以:
1. 训练机器学习异常检测模型并将其部署到 Lambda 在运行时将调用的端点上,
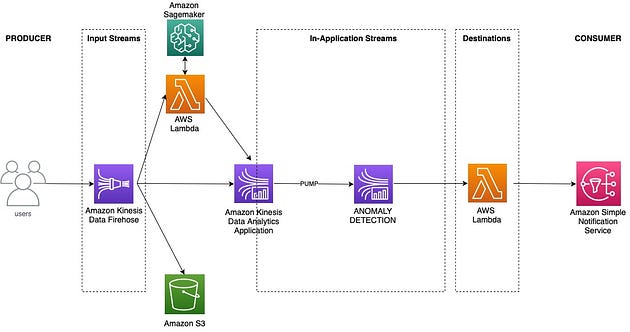
或者
2. 使用 Hugging Face 蒸馏后的 Bert 预训练模型进行情绪分析,节省虚拟示例的时间
我选择了选项 2。但对于您的用例和实际异常检测来说,选项 1 是一个不错的选择。我在本节末尾也给出了一些参考代码。
:: 选项 2(本演示中使用)
为 Python 依赖项创建一个 .zip 文件(Lambda 层)
这要求我们为 Python 环境创建一个名为 python 的目录。
! mkdir src
! touch src/get_pred_from_kinesis.py
# 如果你的环境没有 zip,请使用(推荐)
# !conda install -c conda-forge zip -y
# 或者
# !pip install zip
现在我们安装 transformers 库,它将作为一个层发布到我们的 lambda 函数:
!rm -rf 层/python
!mkdir -p 层/python
!pip install -q --target 层/python 变压器
!cd层 && zip -q --recurse-paths 层.zip 。
我们将 zip 文件作为二进制文件加载:
使用 打开(“layer/layer.zip”,“rb”)作为f:
layer = f.read()
发布该层(我们稍后会将其附加到我们的 lambda 中):
transformers_lambda_layer_name = "transformers-python-sdk-layer"
layer_response = lam.publish_layer_version(
LayerName=transformers_lambda_layer_name,
Content={ "ZipFile" : layer},
Description= "带有'pip install transformers'的层",
CompatibleRuntimes=[ "python3.9" ],
)
layer_version_arn = layer_response[ "LayerVersionArn" ]
print(
f "已成功使用 LayerVersionArn {layer_version_arn} 创建 Lambda 层 {transformers_lambda_layer_name}。"
)
如果由于上传限制而无法正常工作,您可以从 Amazon Lambda 图层 UI 手动上传 zip 文件,并layer_version_arn使用您的 ARN更新变量名称
为我们的 Python 代码(Lambda 函数)创建一个 .zip 文件
这是我们文件的内容src/get_pred_from_kinesis.py:
“”“Python Lambda 处理程序函数。””“
导入base64
导入json
导入随机
从transformers导入管道
sent_pipeline = pipeline(
“sentiment-analysis”,
model= “distilbert-base-uncased-finetuned-sst-2-english”
)
def lambda_handler ( event,context ) -> json:
“”“Lambda 处理程序函数。””“
outputs = []
for record in event[ “records” ]:
payload = base64.b64decode(record[ “data” ])
text = payload.decode( “utf-8” )
split_inputs = text.split( “\t” )
review_body = split_inputs[ 2 ]
predictions = sent_pipeline(review_body)
input = [{ “features” : [review_body]}]
for pred,input_data in zip (predictions, input):
review_id = random.randint( 0,1000 )
# review_id、star_rating、review_body output_data
= "{}\t{}\t{}" .format ( split_inputs[ 0 ], 0 if pred[ "label] == " NEGATIVE " else 1, input_data[" features "] ) output_data_encoded = output_data.encode(" utf- 8 ") output_record = { " recordId ": record[" recordId "], " result ": " Ok ", " data ": base64.b64encode(output_data_encoded).decode(" utf- 8 "), } output_record) return {" records ": output}
如果上述代码在 Amazon Lambda 中出现错误,请尝试其他选项,例如删除转换器层和硬编码预测,看看它是否有效。
!zip src/GetPredFromKinesis.zip src/get_pred_from_kinesis.py
将 zip 文件加载为二进制文件:
使用 打开(“src/GetPredFromKinesis.zip”,“rb”)作为f:
code = f.read()
创建 Lambda 函数
pred_lambda_fn_name = “GetPredFromKinesis”
尝试:
响应=lam.create_function(
FunctionName = f“ {pred_lambda_fn_name} ”,
运行时= “python3.9”,
角色= f“ {iam_role_lambda_arn} ”,
处理程序= “src / get_pred_from_kinesis.lambda_handler”,
代码={ “ZipFile”:code},
层= [layer_version_arn],
描述= “使用变压器对评论输入文本进行情绪预测。”,
#Firehose支持的最大超时为5分钟
Timeout = 300,
MemorySize = 128,
Publish = True,
)
打印(f“Lambda函数{pred_lambda_fn_name}已成功创建。”)
除ClientError为e外:
如果e.response [ “Error” ] [ “Code” ] == “ResourceConflictException”:
响应=lam.update_function_code(
FunctionName= f" {pred_lambda_fn_name} ",
ZipFile=code,
Publish= True,
DryRun= False,
)
print(f“更新现有的 Lambda 函数{pred_lambda_fn_name}。这没问题。”)
else:
print(f“错误:{e} ”)
# 响应:Lambda 函数 GetPredFromKinesis 已成功创建。
响应 = lam.get_function(FunctionName=pred_lambda_fn_name)
pred_lambda_fn_arn = 响应 [ “配置” ][ “FunctionArn” ]
打印(pred_lambda_fn_arn)
# 响应:arn:aws:lambda:us-east-1:XXXXXXXXX XXX:函数:GetPredFromKinesis
:: 选项 1(本演示中未使用)
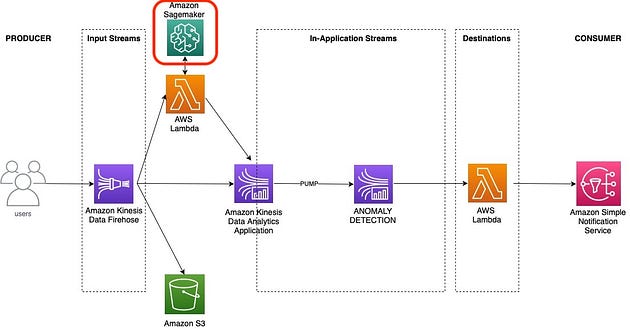
训练 Sagemaker 模型并创建端点
对于您的生产用例,您可能需要根据您的数据训练异常检测模型。
您可以使用任何工具,但由于到目前为止我们只使用 AWS,因此下面我为您提供了在 Sagemaker 上训练和部署 XGBoost 分类器模型的示例。
请注意,这尚未经过测试:
在 sagemaker 上使用 XGBoost 分类器:
导入boto3
导入sagemaker
从sagemaker导入get_execution_role
从sagemaker.amazon.amazon_estimator导入get_image_uri
# 设置 SageMaker 会话
sagemaker_session = sagemaker.Session()
# 获取 SageMaker 用于访问 AWS 资源的 IAM 角色
role = get_execution_role()
# 定义用于数据存储的 S3 存储桶的名称
bucket_name = 'my-sentiment-analysis-bucket'
# 定义训练和验证数据的位置
train_data_location = f"s3:// {bucket_name} /train"
validation_data_location = f"s3:// {bucket_name} /validation"
# 定义训练模型的存储位置
model_artifact_location = f"s3:// {bucket_name} /models"
# 使用 Amazon SageMaker XGBoost 算法设置 SageMaker 估算器
container = get_image_uri(boto3.Session().region_name, "xgboost" )
estimator = sagemaker.estimator.Estimator(
container,
role,
train_instance_count= 1 , # 这不好
train_instance_type= "ml.m4.xlarge" ,
output_path=model_artifact_location,
sagemaker_session=sagemaker_session
)
# 设置超参数
estimator.set_hyperparameters(
objective= "binary:logistic" ,
num_round= 100
)
# 设置数据通道
train_data = sagemaker.inputs.TrainingInput(
train_data_location,
content_type= "text/csv"
)
validation_data = sagemaker.inputs.TrainingInput(
validation_data_location,
content_type= "text/csv"
)
data_channels = { 'train' : train_data, 'validation' : validation_data}
# 启动训练作业
estimator.fit(inputs=data_channels)
网上有很多例子可以帮助你做到这一点。我建议你在组合中添加 Sagemaker Clarify、Sagemaker Lineage Tracking 和 Sagemaker Hyperparameter Tuning,以帮助你从 MDLC(模型开发生命周期)中获得更多收益。
training_job_name = estimator.latest_training_job.name
print ( "训练作业名称:{}" . format (training_job_name))
% %时间
estimator.latest_training_job.wait(logs = False )
显示培训工作指标
估计器.training_job_analytics.dataframe().training_job_analytics .dataframe()
在此示例代码中,我们首先设置一个 SageMaker 会话并获取 SageMaker 用于访问 AWS 资源的 IAM 角色。然后,我们定义用于数据存储的 S3 存储桶的名称,以及训练和验证数据的位置以及训练后的模型的存储位置。
我们使用 Amazon SageMaker XGBoost 算法设置 SageMaker 估算器,并指定目标函数和轮数等超参数。我们还为训练和验证数据设置了数据通道,并启动训练作业。
这只是一个基本示例,还有许多其他超参数和算法可用于 SageMaker 上的情绪分析。但是,此代码应该可以为您提供在 Amazon SageMaker 上训练自己的情绪分析模型的起点。
部署端点(我们仍处于::选项 1 😅)
import boto3
import sagemaker
# 设置 SageMaker 会话
sagemaker_session = sagemaker.Session()
# 定义存储训练模型的 S3 存储桶的名称
bucket_name = 'my-sentiment-analysis-bucket'
model_artifact_location = f's3:// {bucket_name} /models'
# 定义 SageMaker 端点配置的名称
end_config_name = 'my-sentiment-analysis-endpoint-config'
# 创建端点配置
xgb_endpoint_config = sagemaker.session.EndpointConfig(
name=endpoint_config_name,
model_name= 'model.tar.gz' ,
initial_instance_count= 1 ,
instance_type= 'ml.m4.xlarge'
)
# 创建端点
end_name = 'my-sentiment-analysis-endpoint'
xgb_predictor = estimator.deploy(
initial_instance_count= 1,# 这在 abomination 中是:
endpoint_name=endpoint_name,
endpoint_config_name=endpoint_config_name
)
在此示例代码中,我们首先设置一个 SageMaker 会话并定义存储训练模型的 S3 存储桶的名称。我们还定义了 SageMaker 终端节点配置的名称,该配置指定了 S3 中模型工件的名称、用于终端节点的实例数量和类型以及其他配置选项。
sagemaker.session.EndpointConfig()我们通过调用并传入name、model_name、initial_instance_count和参数来创建端点配置instance_type。
estimator.deploy()最后,我们通过调用并传入initial_instance_count、endpoint_name和参数来创建端点endpoint_config_name。
一旦创建端点,我们就可以通过调用来使用它对新数据进行预测xgb_predictor.predict()。
使用端点配置Lambda
响应 = lam.update_function_configuration(
函数名称 = lambda_fn_name_invoke_ep,
环境 = { “变量”:{ “ENDPOINT_NAME”:endpoint_name}}
)
3.创建 Kinesis Data Firehose 传输流
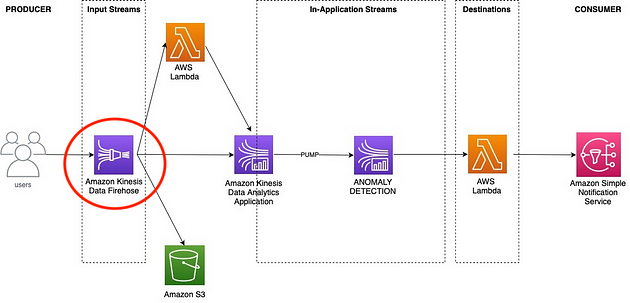
我犯了从网上的例子中复制这段代码的罪行🥸
但是您可以根据需要随意更改缓冲、CloudWatch 日志组、S3 前缀等变量。
请注意,本例中使用了“DeliveryStreamType=DirectPut”。
尝试:
响应=firehose.create_delivery_stream(
DeliveryStreamName = firehose_name,
DeliveryStreamType = “ DirectPut”,
ExtendedS3DestinationConfiguration = {
“RoleARN”:iam_role_kinesis_arn,
“BucketARN”:f“arn:aws:s3 :::{bucket} ”,
“Prefix”:“kinesis-data-firehose /”,
“ErrorOutputPrefix”:“kinesis-data-firehose-error /”,
“BufferingHints”:{ “SizeInMBs”:1,“IntervalInSeconds”:60 },
“CompressionFormat”:“UNCOMPRESSED”,
“CloudWatchLoggingOptions”:{
“Enabled”:True,
“LogGroupName”:“/aws/kinesisfirehose/dsoaws-kinesis-data-firehose”,
“LogStreamName”:“S3Delivery”,
},
“ProcessingConfiguration”:{
“Enabled”:True,
“处理器”:[
{
“类型”:“Lambda”,
“参数”:[
{
“参数名称”:“LambdaArn”,
“参数值”:f“ {pred_lambda_fn_arn}:$LATEST”,
},
{ “参数名称”:“BufferSizeInMBs”,“参数值”:“1” },
{
“参数名称”:“BufferIntervalInSeconds”,
“参数值”:“60”,
},
],
}
],
},
“S3BackupMode”:“Enabled”,
“S3BackupConfiguration”:{
“角色ARN”:iam_role_kinesis_arn,
“存储桶ARN”:f“arn:aws:s3 :::{bucket} ”,
“前缀”:“kinesis-data-firehose-source-record /”,
“ErrorOutputPrefix”:“!{firehose:error-output-type} /”,
“BufferingHints”:{ “SizeInMBs”:1,“IntervalInSeconds”:60 },
“CompressionFormat”:“UNCOMPRESSED”,
},
“CloudWatchLoggingOptions”:{
“Enabled”:False,
},
},
)
打印(f“传输流{firehose_name}已成功创建。”)
打印(json.dumps(response,indent = 4,sort_keys = True,default = str))
除ClientError外为e:
如果e.response [ “Error” ] [ “Code” ] == “ResourceInUseException”:
打印(f“传输流{firehose_name}已存在。”)
否则:
打印(“意外错误:%s”%e)
# 响应:传输流 adows-kinesis-data-firehose 已成功创建。{...}
现在我们等待流处于活动状态。
# 这将需要一段时间
status = ""
while status != "ACTIVE" :
r = firehose.describe_delivery_stream(DeliveryStreamName=firehose_name)
description = r.get( "DeliveryStreamDescription" )
status = description.get( "DeliveryStreamStatus" )
time .sleep( 5 )
print (f "Delivery Stream {firehose_name} is active" )
# 响应:Delivery Stream adows-kinesis-data-firehose 处于活动状态
保存 ARN 以供进一步使用。
firehose_arn = r[ “DeliveryStreamDescription” ][ “DeliveryStreamARN” ]
打印(firehose_arn)
4.创建 Lambda 目标 SNS
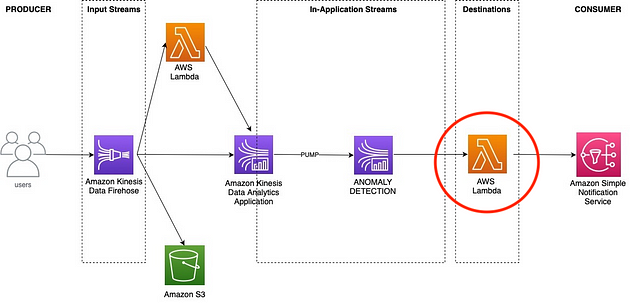
记得在第 2 点中我们讨论过,如果 Kinesis Analytics 应用程序检测到异常,那么它将触发另一个 lambda,将通知推送到 Amazon SNS。
这就是那个 lambda。
让我们创建一个 SNS 主题
响应 = sns.create_topic(
名称 = “review_anomaly_scores”,
)
打印(响应)
sns_topic_arn = 响应[ “TopicArn” ]
打印(sns_topic_arn)
现在我们将创建 Lambda 函数
我们的 Lambda 函数代码位于“src/push_notification_to_sns.py”文件中,因此我们首先创建它。
触摸src/ push_notification_to_sns.py
以下是我们的 Lambda 函数文件的内容:
导入base64
导入os
导入boto3
SNS_TOPIC_ARN = os.environ[ "SNS_TOPIC_ARN" ]
sns = boto3.client( "sns" )
print ( "Loading function" )
def lambda_handler ( event, context ):
output = []
success = 0
Failure = 0
highest_score = 0
print ( f"event: {event} " )
r = event[ "records" ]
print ( f"records: {r} " )
print ( f"type_records: { type (r)} " )
for record in event[ "records" ]:
try :
# 取消注释下面一行以将解码后的数据发布到 SNS 主题。
payload = base64.b64decode(record [ “data” ])
print(f“payload:{payload} ”)
text = payload.decode(“utf-8”)
print(f“text:{text} ”)
score = float(text)
if(score!= 0)and(score> highest_score):
highest_score = score
print(f“新的highest_score:{highest_score} ”)
# sns.publish(
# TopicArn = SNS_TOPIC_ARN,
# Message ='新异常分数:{}'。格式(text),
# Subject ='检测到新评论异常分数'
#)
output.append({ “recordId”:record [ “recordId” ],“result”:“Ok” })
success + = 1
except Exception as e:
print(e)
output.append({ “recordId”:record [ “recordId” ],“result”:“DeliveryFailed” })如果highest_score!= 0
,则 失败+= 1: sns.发布( TopicArn = SNS_TOPIC_ARN, 消息=
f“新异常分数:{ str(highest_score)} ”,
主题= “检测到新评论异常分数”,
)
打印(
f“成功传递{success}记录,未能传递{failure}记录”
)
返回{ “records”:输出}
压缩代码
!zip src /PushNotificationToSNS .zip src /推送通知到SNS .py
将 zip 文件加载为二进制文件
使用 打开(“src/PushNotificationToSNS.zip”,“rb”)作为f:
code = f.read()
现在我们创建 Lambda 函数本身:
尝试:
响应 = lam.create_function(
FunctionName = f“ {lambda_fn_name_sns} ”,
运行时 = “python3.9”,
角色 = f“ {iam_role_lambda_arn} ”,
处理程序 = “src / push_notification_to_sns.lambda_handler”,
代码 = { “ZipFile”:code},
说明 = “将输出记录从 Kinesis Analytics 应用程序传送到 CloudWatch。”,
超时 = 300,
MemorySize = 128,
发布 = True,
)
打印(f“Lambda 函数{lambda_fn_name_sns}已成功创建。”)
除ClientError为e:
如果e.response [ “Error” ][ “Code” ] == “ResourceConflictException”:
响应 = lam.update_function_code(
FunctionName = f“ {lambda_fn_name_sns} ”,
ZipFile=code,
Publish= True,
DryRun= False,
)
print(f“更新现有的Lambda函数{lambda_fn_name_sns}。这没问题。”)
else:
print(f“错误:{e} ”)
#响应:Lambda函数PushNotificationToSNS已成功创建。
响应 = lam.get_function(FunctionName=lambda_fn_name_sns)
lambda_fn_arn_sns = 响应[ “配置” ][ “FunctionArn” ]
打印(lambda_fn_arn_sns)
使用 SNS 主题 ARN 更新 Lambda 函数
响应 = lam.update_function_configuration(
函数名称 = lambda_fn_name_sns,
环境 = { “变量”:{ “SNS_TOPIC_ARN”:sns_topic_arn}},
)
5.创建 Kinesis Data Analytics 应用程序
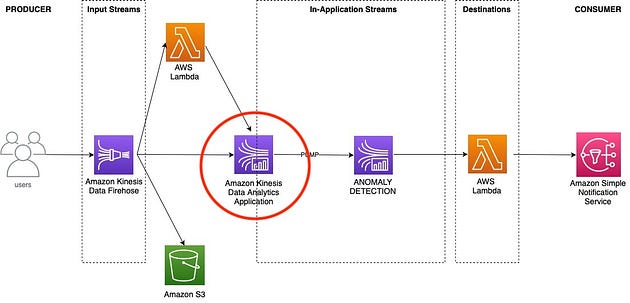
这对我们的异常检测服务来说是重要的一步。
Amazon Kinesis Data Analytics 是一项完全托管的服务,让您能够轻松地使用 SQL 或 Java 实时分析流数据。Kinesis Data Analytics 让您能够处理和分析来自各种来源(例如 Kinesis Data Streams、Kinesis Data Firehose 和其他来源)的数据流。
Kinesis Data Analytics 提供交互式 SQL 编辑器,用于实时创建和运行流数据上的 SQL 查询。该服务还支持 Java 代码,用于更复杂的流处理任务。Kinesis Data Analytics 会自动配置和扩展处理和分析数据流所需的计算资源。
您还可以运行Apache Flink 应用程序来处理 Kinesis Analytics 应用程序上的流数据。
给读者提个醒:
从我开始考虑编写此演示到实际完成编写,AWS 更改了其 Kinesis Analytics App UI。并且他们已将 SQL App 置于遗留状态 😔
以下代码在发布本文时仍然有效,但我不知道它什么时候会停止工作。但网上有大量资源可帮助您解决任何主题,您也可以询问 ChatGPT 🤖
kinesis_data_analytics_app_name = “adoaws-kinesis-data-analytics-sql-app”
in_app_stream_name = “SOURCE_SQL_STREAM_001” # 默认
打印(in_app_stream_name)
创建应用程序
sql_code = """ \
创建或替换流 "ANOMALY_SCORE_SQL_STREAM" (anomaly_score DOUBLE); \
创建或替换泵 "ANOMALY_SCORE_STREAM_PUMP" AS \
插入 "ANOMALY_SCORE_SQL_STREAM" \
选择流 anomaly_score \
从表 (RANDOM_CUT_FOREST( \
CURSOR(SELECT STREAM "star_rating" \
从 "{}" \
) \
) \
); \
""" .format(
in_app_stream_name
)
尝试:
响应= kinesis_analytics.create_application(
ApplicationName = kinesis_data_analytics_app_name,
输入= [
{
“ NamePrefix”:“ SOURCE_SQL_STREAM”,
“ KinesisFirehoseInput”:{
“ ResourceARN”:f“ {firehose_arn} ”,
“ RoleARN”:f“ {iam_role_kinesis_arn} ”,
},
“ InputProcessingConfiguration”:{
“ InputLambdaProcessor”:{
“ ResourceARN”:f“ {pred_lambda_fn_arn} ”,
“ RoleARN”:f“ {iam_role_lambda_arn} ”,
}
},
“ InputSchema”:{
“ RecordFormat”:{
“ RecordFormatType”:“ CSV”,
“ MappingParameters”:{
“CSVMappingParameters”:{
“RecordRowDelimiter”:“\ n”,
“RecordColumnDelimiter”:“\ t”,
}
},
},
“RecordColumns”:[
{
“名称”:“review_id”,
“映射”:“review_id”,
“SqlType”:“VARCHAR(14)”,
},
{
“名称”:“star_rating”,
“映射”:“star_rating”,
“SqlType”:“INTEGER”,
},
{
“名称”:“review_body”,
“映射”:“review_body”,
“SqlType”:“VARCHAR(65535)”,
},
],
},
},
],
输出 = [
{
“名称”:“ANOMALY_SCORE_SQL_STREAM”,
“LambdaOutput”:{
“ResourceARN”:f“ {lambda_fn_arn_sns} ”,
“RoleARN”:f”{iam_role_kinesis_arn} " ,
},
"DestinationSchema" : { "RecordFormatType" : "CSV" },
},
],
ApplicationCode=sql_code,
)
print ( f"SQL 应用程序{kinesis_data_analytics_app_name}已成功创建。" )
print (json.dumps(response, indent= 4 , sort_keys= True , default= str ))
except ClientError as e:
if e.response[ "Error" ][ "Code" ] == "ResourceInUseException" :
print ( f"SQL 应用程序{kinesis_data_analytics_app_name}已存在。" )
else :
print ( "意外错误:%s" % e)
你会注意到,在架构中我提到了三列,
- review_id — 这只是为了简洁起见,
- star_rating — 这将是我们的 lambda 的预测
- review_body — 这将是我们的输入
响应 = kinesis_analytics.describe_application(
应用程序名称=kinesis_data_analytics_app_name
)
打印(json.dumps(响应,缩进= 4,sort_keys = True,默认= str))
让我们记下启动数据分析应用程序时将使用的input_id:
input_id = 响应[ “应用程序详细信息” ][ “输入描述” ][0][ “输入标识” ]
打印(input_id)
启动 Kinesis Data Analytics 应用程序
尝试:
响应 = kinesis_analytics.start_application(
ApplicationName = kinesis_data_analytics_app_name,
InputConfigurations = [
{
“Id”:input_id,
“InputStartingPositionConfiguration”:{ “InputStartingPosition”:“NOW” },
}
],
)
打印(json.dumps(response,indent = 4,sort_keys = True,default = str))
除了ClientError作为e:
如果e.response [ “Error” ] [ “Code” ] == “ResourceInUseException”:
打印(f“应用程序{kinesis_data_analytics_app_name}已启动。”)
否则:
打印(f“错误:{e} ”)
等待 Kinesis Data Analytics 应用程序处于运行状态
response = kinesis_analytics.describe_application(ApplicationName=kinesis_data_analytics_app_name)
%%时间
导入时间
app_status = response[ "ApplicationDetail" ][ "ApplicationStatus" ]
print ( "应用程序状态 {}" .格式(app_status))
while app_status != "RUNNING" :
time .sleep( 5 )
response = kinesis_analytics.describe_application(ApplicationName=kinesis_data_analytics_app_name)
app_status = response[ "ApplicationDetail" ][ "ApplicationStatus" ]
print ( "应用程序状态 {}" .格式(app_status))
print ( "应用程序状态 {}" .格式(app_status))
最近我检查了一下,亚马逊已经改进了 Kinesis Data Analytics 应用程序,使其更加健壮且 API 友好。
这将帮助您监控应用程序内部发生的情况,并获得更好的控制,例如通过 UI 本身停止和删除应用程序(早期的 UI 删除是有缺陷的🫤)。
6. 对 Kinesis Data Firehose 进行评论
关键时刻,让我们将一些记录放到 Firehose 上。我们只会放坏记录,因为我们没有耐心😅并且懒得获取任何真实数据集。
firehoses = firehose.list_delivery_streams(DeliveryStreamType = “DirectPut”)
firehose_response = firehose.describe_delivery_stream(DeliveryStreamName = firehose_name)
%%time
step = 1
for _ in range ( 0 , 10 , step):
timestamp = int (time.time())
df_anomalies = pd.DataFrame(
[
{
“review_id” : str (timestamp),
“review_body” : “这让我想吐到永远。” ,
},
],
columns=[ “review_id” , “star_rating” , “review_body” ],
)
reviews_tsv_anomalies = df_anomalies.to_csv(sep= “\t” , header= None , index= False )
response = firehose.put_record(
Record={ “Data” : reviews_tsv_anomalies.encode( “utf-8” )},
DeliveryStreamName=firehose_name,
)
好吧,如果你有一个真正的异常检测模型,这将改变以匹配你的模式,或者你也可以使用50K 电影评论的 IMDB 数据集来玩你的情绪分析模型。不过请记住你的 AWS 成本🫣。
同行工程师提示,在您的个人账户上设置 AWS 预算,以防止任何不必要的意外。
如果一切按计划进行,那么您应该:
- 在您的 Kinesis S3 存储桶中(我的是 Sagemaker 默认存储桶),您应该看到三个文件夹,其中包含带有预测的记录、源记录(没有预测)以及 firehose 错误
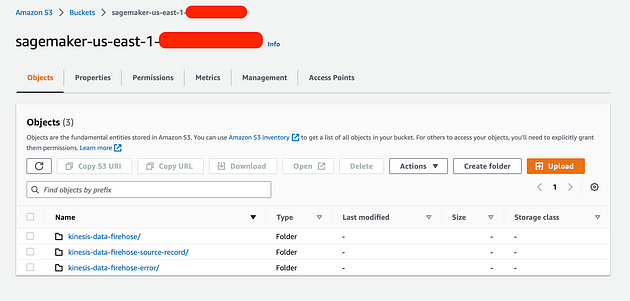
- 您还应该在 CloudWatch 中看到 Lambda 函数 PushNotificationToSNS 日志(表示记录已到达末尾)
- 检查 GetPredFromKinesis Lambda CloudWatch Log 组是否存在任何错误:
4.您还可以在 Lambda 函数 UI 中监控 PushNotificationToSNS Lambda 函数日志中的调用情况:
如果您的 SNS 主题有任何订阅者,在确认这些订阅者后,您也应该会看到一些操作。
7. 释放资源
这与其他任何步骤同样重要。
请释放资源,例如您的 sagemaker studio 实例(如果您正在使用 sagemaker studio),删除 Kinesis Data Analytics App 和 Firehose 数据流。
您还可以删除 SNS 主题和 Lambda 函数(尽管它们在静止时不花费任何费用,但如果您不打算使用它们,那么您可以删除它们)。
其他用例
-
你可以检测产品的平均评价评分来检测行为漂移
-
用户通过社交媒体实时反馈新产品或活动信息,了解公众反馈
-
近乎实时地检测有恶意的用户或试图滥用系统的人
-
还有很多…
DeliveryStreamName=firehose_name,)
好吧,如果你有一个真正的异常检测模型,这将改变以匹配你的模式,或者你也可以使用50K 电影评论的 IMDB 数据集来玩你的情绪分析模型。不过请记住你的 AWS 成本🫣。
同行工程师提示,在您的个人账户上设置 AWS 预算,以防止任何不必要的意外。
如果一切按计划进行,那么您应该:
- 在您的 Kinesis S3 存储桶中(我的是 Sagemaker 默认存储桶),您应该看到三个文件夹,其中包含带有预测的记录、源记录(没有预测)以及 firehose 错误
[外链图片转存中…(img-q8FC6aEp-1722335068958)]
- 您还应该在 CloudWatch 中看到 Lambda 函数 PushNotificationToSNS 日志(表示记录已到达末尾)
[外链图片转存中…(img-pUGhaMv6-1722335068958)]
- 检查 GetPredFromKinesis Lambda CloudWatch Log 组是否存在任何错误:
[外链图片转存中…(img-nqwQzliw-1722335068959)]
4.您还可以在 Lambda 函数 UI 中监控 PushNotificationToSNS Lambda 函数日志中的调用情况:
[外链图片转存中…(img-pm7AFEwF-1722335068959)]
如果您的 SNS 主题有任何订阅者,在确认这些订阅者后,您也应该会看到一些操作。
7. 释放资源
这与其他任何步骤同样重要。
请释放资源,例如您的 sagemaker studio 实例(如果您正在使用 sagemaker studio),删除 Kinesis Data Analytics App 和 Firehose 数据流。
您还可以删除 SNS 主题和 Lambda 函数(尽管它们在静止时不花费任何费用,但如果您不打算使用它们,那么您可以删除它们)。
其他用例
- 你可以检测产品的平均评价评分来检测行为漂移
- 用户通过社交媒体实时反馈新产品或活动信息,了解公众反馈
- 近乎实时地检测有恶意的用户或试图滥用系统的人
- 还有很多…
整个笔记本和两个 Lambda(python)文件都位于 GitHub 存储库中:
博客原文:专业人工智能社区















 5538
5538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









