







关注微信公众号“时序人”获取更好的阅读体验
时间序列工业实践
- 永不停息的智能服务:流式计算、数据处理及相关技术
- 【超详细整理】时间序列数据库到底是什么?
- OpenTelemetry:服务监控可观察性统一方案
- 智能运维 | 故障诊断与根因分析论文一览
- RRCF: 基于数据流的时序异常检测
数据是实时产生的,对数据进行批处理所花费的成本太高了,数据产生的价值被低估。在高维数据下,如何能发现异常的维度?2016年 亚马逊在ICML发表了一篇异常检测算法,Robust Random Cut Forest(RRCF),对周志华老师的孤立森林算法进行改进,适用于数据流的实时处理,实时训练与实时异常检测。该算法已被AWS落地服务化,集成为产品对外服务。
本文为大家梳理该算法的关键原理,供大家阅读。
会议概况

ICML 是 International Conference on Machine Learning的缩写,即国际机器学习大会。ICML如今已发展为由国际机器学习学会(IMLS)主办的年度机器学习国际顶级会议,被中国计算机协会推荐为A类会议。
每年,世界各地的学术机构和企业都会相聚在这个会议上,讨论分享最新的学术进展。因此,ICML被视为与NeurIPS齐名的推动机器学习发展的重要会议。

论文标题 | Robust Random Cut Forest Based Anomaly Detection on Streams
论文来源 | ICML 2016
论文链接 | http://proceedings.mlr.press/v48/guha16.html
论文源码 | https://github.com/kLabUM/rrcf
要解决的问题
在工业真实场景中,数据大部分是实时产生的。传统的数据处理方法是对实时数据进行批处理,其所花费的成本比较大,也不能充分发挥实时数据所能带来的价值。
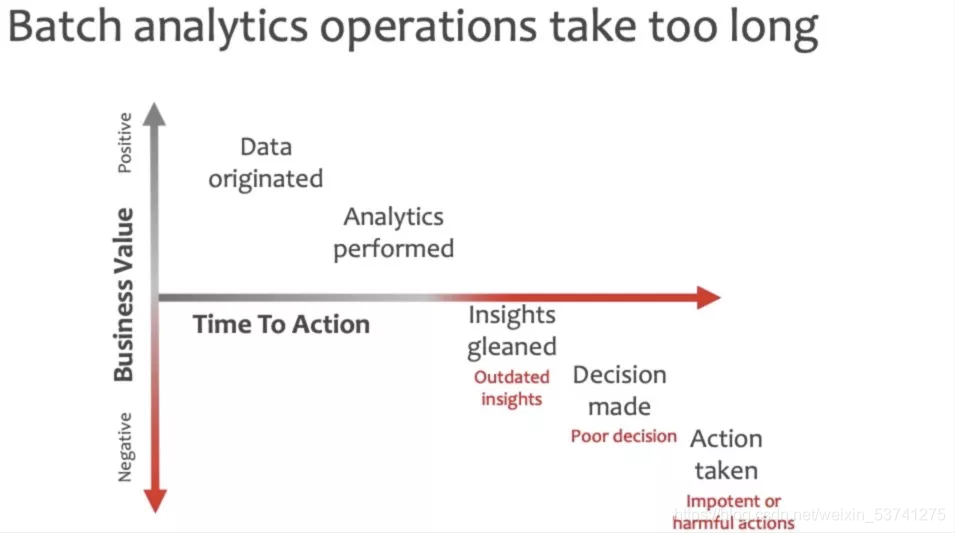
工业界常常会遇到这样的问题:在面对实时产生的海量数据流,我们如何才能快速且准确地发现数据中的异常呢?
基于数据流的异常检测
实时检测异常的能力是非常有价值的。想象一下:
- 注意大型涡轮机故障的早期预警信号
- 看心跳的细微变化表示疾病
- 在股市数据中发现重大异常
- 确认员工行为的变化,这是安全漏洞的信号
- 发现偏离典型的路线,提供绑架的早期预警信号
准确而快速的发现异常,可以帮助规避生产生活中很多风险,快速抓住机遇,产生巨大的价值。正所谓“时间就是金钱”。然而,准确地探测异常是非常困难的。首先,所谓的异常现象是不断变化的。随着软件的更新或行为的改变,系统会随着时间的推移而演进。因此,有效的异常检测需要一个系统不断的学习。其次,为了发现异常,我们不能等待一个指标明显超出范围。早期检测需要能够检测不明显或容易检测到的模式的细微变化。此外,由于异常的性质是出乎意料的,一个有效的检测系统必须能够确定新事件是否异常,而不依赖预先设定的阈值。
无监督树形异常检测算法发展历程
对于实时数据流异常检测,除了常用的统计方法以外,现在工业界最常用的方法是周志华老师于2008年提出的树异常检测算法。该类方法的发展历程如下:
- 2008 - Isolation Forest Published
- 2013 - Survey on outlier detection
- 2016 - RRCF published in ICML
- 2016 - RRCF available on Amazon Kinesis
- 2018 - RRCF available on Hydroserving
2008年 Isolate Forest 原理
1. 单棵树的构建过程
iTree是一种随机二叉树,每个节点要么有两个孩子,要么就是叶子节点,每个节点包含一个属性q和一个划分值p。
具体的构建过程如下:
- 从原始训练集合X种无放回的抽取样本子集
- 划分样本子集,每次划分都从样本中随机选择一个属性q,再从该属性中随机选择一个划分的值p,该p值介于属性q的最大与最小值之间
- 根据2中的属性q与值p,划分当前样本子集,小于值p的样本作为当前节点的左孩子,大于p值的样本作为当前的右孩子
- 重复上述2,3步骤,递归构建每个节点的左、右孩子节点,知道满足终止条件为止,通常终止条件为所有节点均只包含一个样本或者多个相同的样本,或者树的深度达到了限定的高度
2. 构建参数的说明
有两个参数控制着模型的复杂度:
- 每棵树的样本子集大小,它控制着训练数据的大小,论文中的实验发现,当该值增加到一定程度后,IForest的辨识能力会变得可靠,但没有必要继续增加下去,因为这并不会带来准确率的提升,反而会影响计算时间和内存容量,论文实现发现该参数取256对于很多数据集已经足够;
- 集成的树的数量,也可以理解为对原始数据的采样的次数,它控制着模型的集成度,论文中描述取值100就可以了;
3. 如何衡量样本的异常值
计算样本的异常值得过程如下:将测试数据在iTree树上沿着对应的条件分支往下走,直到达到叶子节点,并记录这过程中经过的路径长度
h
(
x
)
h(x)
h(x),利用如下公式进行异常分数的计算:
s
(
x
,
n
)
=
2
E
(
h
(
x
)
)
c
(
n
)
s(x, n) = 2^{ \frac{E(h(x))}{c(n)}}
s(x,n)=2c(n)E(h(x))
其中,
c
(
n
)
=
2
×
H
(
n
−
1
)
−
2
×
(
n
−
1
)
n
c(n) = 2 \times H(n-1) - \frac{2 \times (n-1)}{n}
c(n)=2×H(n−1)−n2×(n−1) 是二叉搜索树的平均路劲长度,用来对结果进行归一化处理,其中
H
(
k
)
=
l
n
(
k
)
+
ϵ
H(k) = ln(k) + \epsilon
H(k)=ln(k)+ϵ 来估计,其中ε是欧拉常数,其值大约为0.5772156649
4. 一些缺点
- 需要计算所有的节点
- 每个叶子节点只包含一个数值点
- 每个节点都会将其点的边界框分成两半
2016年RRCF原理
0. 为何会引入RRCF算法?
- 数据是持续产生的,数据中的时间戳是一个重要因素,而这个维度却经常被大家忽略
- 数据的结构和形态是未知的,需要设计一个鲁棒性的算法来应对各种复杂的场景需求
- iTree是针对候选数据,进行N次无放回的采样,通过对静态数据集进行划分而得到。若针对流式数据,每次都要针对最新的数据进行采样,再去构造数据集,运行算法,得到相应的结果;
- 在针对流式数据的异常检测场景中,缺少对序列中时序的关系的考虑,算法仅仅把当前的点当做孤立的点进行建模;
1. 针对数据流进行采样建模
针对第一个上述的第一个问题:
- 可以采用一些采样策略(蓄水池采样)能准确的当前的数据点是否参与异常建模;
- 同时指定一个时间窗口长度,当建模的数据过期后,应该从模型中剔除掉;
2. 算法中核心的几个操作
构造Robust Random Cut Tree操作

从一个Tree中删除某个样本

插入一个新的样本到树结构中

如何衡量样本的异常值
形象化的描述如下所示
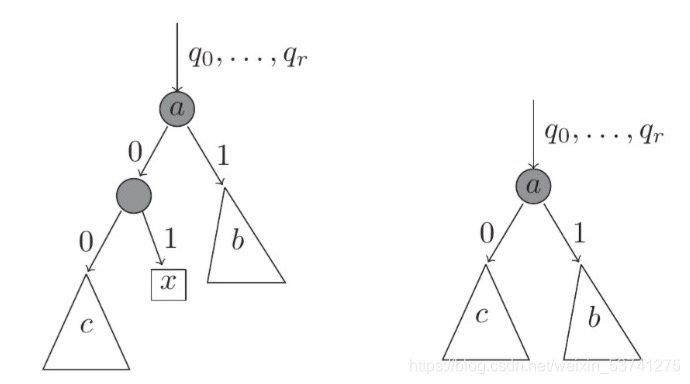
上图左侧表示构造出来的树的结构,其中x是我们待处理的样本点,有图表示将该样本点删除后,动态调整树结构的形态。其中
q
0
,
.
.
.
,
q
r
q_0,...,q_r
q0,...,qr表示从树的根节点编码到a节点的描述串。
每个样本的异常分数含义:将点 x 的异常得分视为包含或不包含该点,导致整体树结构发生改变的程度
E T [ ∣ M ( T ) ∣ ] − E T [ ∣ M ( D e l e t e ( x , T ) ) ∣ ] E_T[|M(T)|] - E_T[|M(Delete(x, T))|] ET[∣M(T)∣]−ET[∣M(Delete(x,T))∣]
用上述公式的描述,可以得到具体的衡量分数,但是如果将上述分数直接转换为异常值,还需要算法同学根据自己的场景进行合理的转换
RRCF在业内的服务方案
RRCF算法由亚马逊提出,率先在AWS落地作为服务对外提供(Amazon Kinesis),主要解决任意规模单条时间序列的异常检测问题。
应用场景
- AWS Metering
- Amazon S3 events
- Amazon Cloud Watch Logs
- Amazon.com online catalog
- Amazon Go Video analysis
Kinesis - RRCF调用方式
-- creates a temporary stream.
CREATE OR REPLACE STREAM "TEMP_STREAM" (
"passengers" INTEGER,
"distance" DOUBLE,
"ANOMALY_SCORE" DOUBLE);
-- creates another stream for application output.
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (
"passengers" INTEGER,
"distance" DOUBLE,
"ANOMALY_SCORE" DOUBLE);
-- Compute an anomaly score for each record in the input stream
-- using Random Cut Forest
CREATE OR REPLACE PUMP "STREAM_PUMP" AS
INSERT INTO "TEMP STREAM"
SELECT STREAM "passengers", "distance", ANOMALY_SCORE
FROM TABLE (RANDOM_CUT_FOREST (
CURSOR(SELECT STREAM * FROM "SOURCE_SQL_STREAM")))
-- Sort records by descending anomaly score, insert into output stream
CREATE OR REPLACE PUMP "OUTPUT_PUMP" AS
INSERT INTO "DESTINATION_SQL_STREAM"
SELECT STREAM * FROM "TEMP_STREAM"
ORDER BY FLOOR("TEMP_STREAM".ROWTIME TO SECOND), ANOMALY_SCORE
DESC;
参考文献
- Sudipto Guha, Nina Mishra, Gourav Roy, and Okke Schrijvers. “Robust random cut forest based anomaly detection on streams.” In International Conference on Machine Learning, pp. 2712-2721. 2016.
- Byung-Hoon Park, George Ostrouchov, Nagiza F. Samatova, and Al Geist. “Reservoir-based random sampling with replacement from data stream.” In Proceedings of the 2004 SIAM International Conference on Data Mining, pp. 492-496. Society for Industrial and Applied Mathematics, 2004.
- http://proceedings.mlr.press/v48/guha16-supp.pdf
- Implementation of the Robust Random Cut Forest Algorithm for anomaly detection on streams. https://klabum.github.io/rrcf/scoring-rctree.html
- 亚马逊中关于该算法的参数说明 https://docs.aws.amazon.com/zh_cn/kinesisanalytics/latest/sqlref/sqlrf-random-cut-forest-with-explanation.html
- 亚马逊中关于该算法的具体例子说明 https://docs.aws.amazon.com/zh_cn/kinesisanalytics/latest/dev/app-anomaly-detection.html
更多原创内容与系列分享,欢迎关注微信公众号“时序人”获取。


















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









