






使用 Azure 开发到部署 AI 模型
使用前端部署机器学习模型

嗨,同学们!👋 欢迎来到机器学习领域的另一段激动人心的旅程。今天,我们将讨论构建 ML 模型时经常被忽视但极其重要的方面,即部署机器学习模型。所以,拿上你最喜欢的饮料,舒适地坐下,让我们一起踏上这段启发性的冒险吧!
为什么学习部署 ML 模型很重要?
现在,你可能会想,“为什么要为我的机器学习模型部署前端?”好吧,我的朋友,让我告诉你——这一切都是为了把你的项目从代码编辑器的范围带到现实世界。当然,你花了无数的时间来制作完美的模型,微调那些超参数,并取得令人印象深刻的准确率。但如果你的杰作被隐藏起来,无法被大众接触到,这一切又有什么用呢?
使用前端部署机器学习模型将为您打开一个无限可能的世界。它让您可以与他人分享您的创作,向潜在雇主展示您的技能,甚至为解决实际问题做出贡献。此外,让我们不要忘记看到您的辛勤工作付诸实践并对周围世界产生切实影响所带来的满足感。
让我们开始吧:构建和部署您的模型
既然我们已经确定了部署的重要性,让我们撸起袖子,深入研究细节。以下是分步指南,可帮助您像专业人士一样完成整个过程:
步骤 1:构建机器学习模型
在部署模型之前,我们需要部署一些东西,对吧?所以让我们从构建机器学习模型开始。对于这项任务,我将使用Kaggle 的Telco Customer Churn Dataset。这涉及几个关键步骤,从数据收集和预处理开始。
数据收集和预处理
构建任何机器学习模型的第一步都是收集和预处理数据。这通常涉及处理缺失值、处理分类变量和缩放数值特征。让我们仔细看看如何实现这一点:
导入pandas作为pd
导入matplotlib.pyplot作为plt
导入math
从sklearn.metrics导入mutual_info_score
从sklearn.preprocessing导入OneHotEncoder、LabelEncoder、MinMaxScaler
导入numpy作为np
从sklearn.model_selection导入train_test_split
从keras.layers导入Dense
从keras.models导入Sequential
从sklearn.metrics导入training_report
df=pd.read_csv( '..\Kaggle 竞赛\客户流失预测\WA_Fn-UseC_-Telco-Customer-Churn.csv' )
df.head()
探索性数据分析 (EDA) 和数据清理
一旦我们收集了数据并对其进行了预处理,下一步就是进行探索性数据分析 (EDA),以获得洞察力并识别数据中的模式。这涉及可视化数据和分析关键统计数据。让我们深入研究一下:
对于df.columns中的i :
打印(f“ {i} 唯一值:- {df[ f' {i} ' ].unique()} ”)
df.isnull () . sum ( )
df [ 'TotalCharges' ]=pd.to_numeric( df [ 'TotalCharges' ],errors= 'coerce' )
df.dropna(inplace=True)
df.drop(columns=[ 'customerID' ],inplace=True,axis=1)
df [ 'PaymentMethod' ]= df [ 'PaymentMethod' ].apply(lambda x: str(x).replace( ' (automatic)' , '' ))
churn_count = df[ 'Churn' ].value_counts( normalize = True )
churn_count.plot(kind = 'bar' ,color = [ 'springgreen' , 'salmon' ])
plt.title( '数据集上的客户流失分布' )
特征工程
特征工程涉及创建新特征或转换现有特征以提高模型性能。这可以包括编码分类变量、创建交互项或缩放数值特征。让我们设计一些特征:
one_hot_encoded_data = one_hot_encoded_data [['任期','总费用','每月费用','客户流失']]
one_hot_encoded_data.head()
mxs= MinMaxScaler ()
one_hot_encoded_data[ ' tenure' ]=mxs.fit_transform (np.array ( one_hot_encoded_data[ 'tenure' ]). reshape ( -1,1 ) ) one_hot_encoded_data[ ' TotalCharges' ]=mxs.fit_transform ( np.array (one_hot_encoded_data[ 'TotalCharges' ]). reshape ( -1,1 )) one_hot_encoded_data[ 'MonthlyCharges' ] = mxs.fit_transform ( np.array (one_hot_encoded_data[ ' MonthlyCharges' ]). reshape ( -1,1 ) ) lb = LabelEncoder ( ) one_hot_encoded_data[ ' Churn' ]=lb. fit_transform(np.array ( one_hot_encoded_data [ 'Churn' ])。重塑(-1,1))
模型选择
一旦我们的数据被清理并且特征被设计出来,我们就可以继续为我们的问题选择合适的机器学习模型。模型的选择取决于问题的性质(分类或回归)、数据集的大小以及模型的可解释性。让我们选择一个模型:
模型 = Sequential()
模型。添加(Dense ( 4,激活 = 'relu',input_dim = 16,kernel_initializer = 'uniform' ))
模型。添加(Dense ( 4,激活 = 'relu',kernel_initializer = 'uniform' ))
模型。添加(Dense ( 1,激活 = 'sigmoid',kernel_initializer = 'uniform' ))模型。
编译 ( 'adam',loss = 'binary_crossentropy',metrics = [ 'accuracy' ])
x=one_hot_encoded_data.drop(['Churn'],axis=1)
y=one_hot_encoded_data['Churn']
x=np.array(x)
y=np.array(y)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=10)
模型.fit(x_train,y_train,epochs= 100,validation_split= 0.1,batch_size= 12)
模型训练与评估
选择模型后,就该在准备好的数据上对其进行训练并评估其性能了。这涉及将数据分成训练集和测试集,将模型拟合到训练数据,并评估其在测试数据上的性能。让我们训练和评估模型:
y_pred=model.predict(x_test)
y_pred=(y_pred>0.5)
1 在 y_pred 中
打印(分类报告(y_test,y_pred))
最后,保存你的模型,以便你可以使用它进行部署
模型.保存( “模型.h5” )
从现在开始,每一步对于项目的成功都至关重要,因此请务必在进展过程中密切关注细节。
第 2 步:创建 Flask Web 应用
我们的模型经过训练并准备就绪后,是时候迈出下一步并将其与前端一起部署了。在深入研究部署模型之前,让我们简要讨论一下 Web 框架。Web 框架提供了一个结构和一组工具来简化构建 Web 应用程序的过程。Python 中一些流行的 Web 框架包括 Flask、Django 和 Streamlit。虽然 Django 是一个功能齐全的框架,具有许多内置功能,但 Streamlit 是专为数据科学和机器学习应用程序设计的。今天,我们将重点介绍 Flask,因为它简单且多功能,适用于广泛的用例。
我们将使用 Flask(一种轻量级的 Python Web 框架)来实现此目的。操作方法如下:
设置Flask应用
初始化 Flask 应用程序很简单。我们将定义路由来处理 Web 应用程序的不同功能。让我们设置基本结构:
从flask导入Flask、render_template、request
从keras.models导入load_model
导入numpy作为np
app = Flask(__name__)
# 主页路由
@app.route( '/' )
def home ():
return render_template( 'index.html' )
if __name__ == '__main__' :
app.run(debug= True )
集成您的模型
将训练好的机器学习模型加载到Flask应用程序中,并定义主要的预测路线。
app = Flask(__name__)
# 加载训练好的模型
model = load_model( "model.h5" )
# 主页路由
@app.route( '/' )
def home ():
return render_template( 'index.html' )
# 预测路由
@app.route( '/predict' , methods=[ 'POST' ] )
def predict ():
# 从表单获取用户输入
input = [ float (x) for x in request.form.values()]
# 执行预测
prediction = model.predict(np.array([inputs]))
churn_status = "Churn" if prediction > 0.5 else "No Churn"
return render_template( 'result.html' , churn_status=churn_status)
if __name__ == '__main__' :
app.run(debug= True )
此代码设置了一个具有两个路由的 Flask Web 应用:
- ‘/’ 路由表示主页,用户可以在此输入他们的数据。
- ‘/predict’ 路线处理预测逻辑并显示结果。
创建前端
现在我们已经设置好了 Flask 应用,让我们使用 HTML 和 CSS 构建一个简单的前端界面来与我们的模型进行交互。我们将有两个 HTML 模板:index.html用于输入表单和result.html显示预测结果。
index.html 的 HTML 代码
<!DOCTYPE html >
< html lang = "en" >
< head >
< meta charset = "UTF-8" >
< meta name = "viewport" content = "width=device-width, initial-scale=1.0" >
< title >客户流失预测</ title >
< style >
body {
font-family: Arial, sans-serif;
margin: 0;
padding: 20px;
}
h1 {
text-align: center;
margin-bottom: 30px;
}
form {
max-width: 500px;
margin: 0 auto;
border: 1px solid #ccc;
padding: 20px;
border-radius: 10px;
box-shadow: 0 0 10px rgba(0,0,0,0.1);
}
label {
display: block;
margin-bottom: 10px;
}
input[type="number"] {
width: 100%;
padding: 10px;
边距底部:20px;
边框:1px solid #ccc;
边框半径:5px;
}
input[type="submit"] {
background-color: #007bff;
color: #fff;
边框:none;
padding: 10px 20px;
边框半径:5px;
光标:pointer;
}
input[type="submit"]:hover {
background-color: #0056b3;
}
</ style >
</ head >
< body >
< h1 >客户流失预测</ h1 >
< form action = "/predict" method = "post" >
< label for = "tenure" >任期(月):</标签>
<输入 类型= “number” id = “tenure” name = “tenure” 必填>
<标签 for = "MonthlyCharges" >每月费用: </ label >
< input type = "number" id = "MonthlyCharges" name = "MonthlyCharges" required >
< label for = "TotalCharges" >总费用: </ label >
< input type = "number" id = "TotalCharges" name = "TotalCharges" required >
< input type = "submit" value = "Predict" >
</ form >
</ body >
</ html >
result.html 的 HTML 代码
<!DOCTYPE html >
< html lang = "en" >
< head >
< meta charset = "UTF-8" >
< meta name = "viewport" content = "width=device-width, initial-scale=1.0" >
< title >预测结果</ title >
< style >
body {
font-family: Arial, sans-serif;
margin: 0;
padding: 20px;
}
h1 {
text-align: center;
margin-bottom: 30px;
}
.result {
max-width: 500px;
margin: 0 auto;
border: 1px solid #ccc;
padding: 20px;
border-radius: 10px;
box-shadow: 0 0 10px rgba(0,0,0,0.1);
}
.result p {
text-align: center;
font-size: 20px;
}
</ style >
</ head >
< body >
< h1 >预测结果</ h1 >
< div class = "result" >
< p >预测的流失状态为:< strong > {{ churn_status }} </ strong > </ p >
</ div >
</ body >
</ html >
本地测试
在部署我们的 Flask 应用程序之前,必须在本地进行测试以确保一切正常。打开终端,导航到包含 Flask 应用程序的目录,然后运行以下命令:
python 应用程序。py
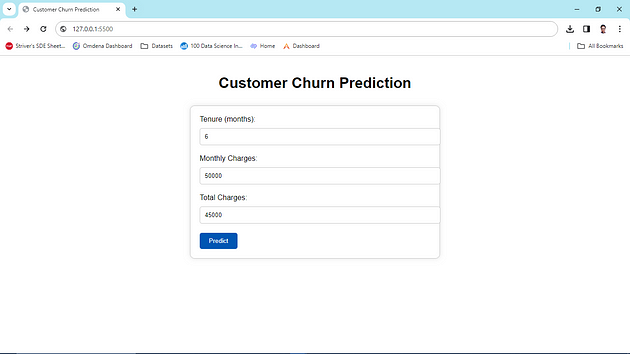
来源:作者创建的图像

来源:作者创建的图像
按照以下步骤,您将拥有一个功能齐全的 Flask Web 应用程序,可以使用您的机器学习模型进行预测。
步骤 3:在 Azure 上部署
现在我们已经在本地启动并运行了 Flask Web 应用,是时候与全世界分享它了。还有什么比使用 Azure 应用服务更好的方法呢?以下是使用 VS Code 在 Azure 上部署 Flask 应用的方法:
在 Azure Web 应用服务上创建 Web 应用
当然!以下是在 Azure Web 应用服务上创建 Web 应用的分步过程:
- 打开 Web 浏览器并导航到 ( https://portal.azure.com/ )。
- 使用您的 Azure 帐户凭据登录。
- 在 Azure 门户中,单击左上角的“+ 创建资源”按钮。
- 在搜索栏中搜索“Web App Service”,然后在搜索结果中选择“Web App”。
- 单击“创建”按钮开始创建新的 Web 应用程序。
- 在“基础信息”选项卡中提供以下信息,如订阅、资源组、应用程序名称等。

来源:作者创建的图像
7.点击“审核+创建”按钮,进入下一步。
- 检查您的 Web 应用程序的所有配置,然后单击“创建”按钮来创建您的 Web 应用程序。
9.等待部署完成。您可以在 Azure 门户中监视部署的进度。
10.部署完成后,在 VS Code 上打开您的项目。
从 VS Code 部署应用
- 在 VS Code 中,从扩展部分安装“Azure Tools”。
- 之后,您将能够看到一个新图标“Azure”。
- 在 Azure 选项卡中,从“应用服务”部分找到您刚刚在 Azure 帐户上创建的 Web 应用。
- 然后右键单击Web应用程序,然后单击“部署到Web应用程序”。
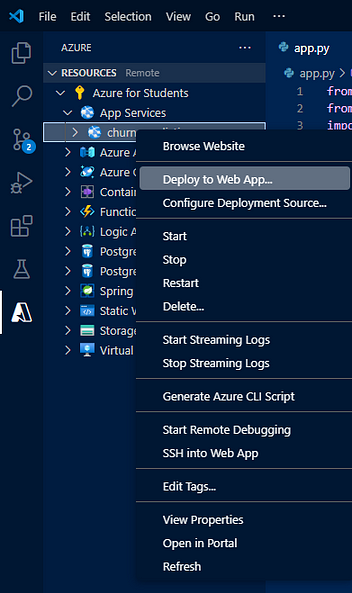
来源:作者创建的图像
- 从面板中选择项目,等待部署完成。您可以在终端中看到部署的进度。
- 应用程序部署后,您将能够打开它。

来源:作者创建的图像
就这样,您已经成功部署了机器学习模型,并让全世界都可以看到它!
结论
各位,现在就到这里!我们介绍了使用前端部署机器学习模型的方方面面,从构建模型到将其部署到 Azure 平台上。我希望这段旅程能像对我一样给您带来启发。
请记住,机器学习的世界广阔且不断发展,所以不要害怕尝试,从错误中吸取教训,不断突破可能的界限。谁知道呢?你的下一个项目可能是彻底改变这个领域的项目!
uhmOyP-1722336517070)]
来源:作者创建的图像
- 从面板中选择项目,等待部署完成。您可以在终端中看到部署的进度。
- 应用程序部署后,您将能够打开它。
[外链图片转存中…(img-1E3cPKQU-1722336517070)]
来源:作者创建的图像
就这样,您已经成功部署了机器学习模型,并让全世界都可以看到它!
结论
各位,现在就到这里!我们介绍了使用前端部署机器学习模型的方方面面,从构建模型到将其部署到 Azure 平台上。我希望这段旅程能像对我一样给您带来启发。
请记住,机器学习的世界广阔且不断发展,所以不要害怕尝试,从错误中吸取教训,不断突破可能的界限。谁知道呢?你的下一个项目可能是彻底改变这个领域的项目!
下次见,祝您编码愉快,并祝您的模型始终完美部署。干杯!🚀
博客原文:https://dz.closeai.cc/forum.php?mod=viewthread&tid=149















 3771
3771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









