







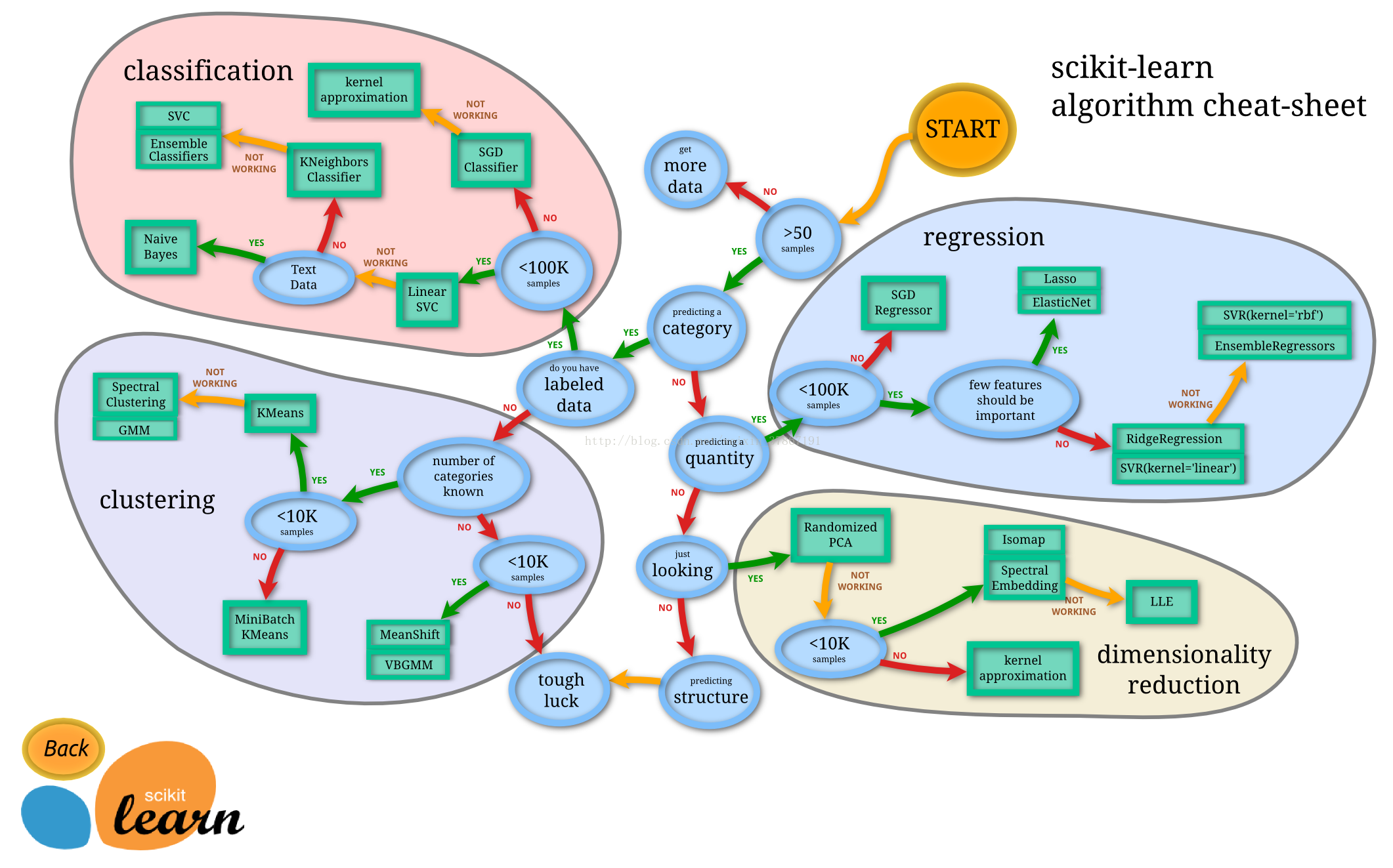
关于数据是否线性可分:
线性可分:
非线性可分:
常见分类器:
K近邻分类器(KNN):
最懒惰的学习方法,大概流程就是取一个点,找到离这个点最近的n个点,看哪一个类别最多,就预测那一个类别。
优势:易于操作,对于复杂的情况也可以做到可以接受的效果。
缺点:训练集纬度高时,因为高维灾难的缘故,表现会很差。当k取太小时极容易过度拟合。
支持向量机(SVM):
决策树:
随机森林:
具体使用哪种分类方法:
1. 这个问题本身是个meta-learning,即对方法进行分类-> 不可能有定论,以上抽样举例式的回答是一种回答方式,这里尝试从抽象层面进行回答。
2. 总体上总是可以分成高维方法和低维方法。高维亦即非参数模型,低维即参数模型。显然,非参数方法集之于参数方法集如同无理数集之于有理数集。
3. 参数方法的一个大块是线性模型,统计中这叫回归,数学中这叫投影。这反映了一个应用数学式的思路:一开始问题总是无穷维的,然后开始用投影进行降维,同时加上矢量空间假设,而所有非线性的部分全部扔到坐标轴内部。
4. 参数方法的另一个大块是分布模型,基于似然函数的方法(极大似然)和贝叶斯(先验x似然=后验)。分布模型本质也是降维,把问题降到低维度的参数空间里,并且允许样本误差的存在。事实上线性模型在统计观点下也是一个分布模型,应变量的分布。这样一来回归的多变性不仅在于投影基矢量的构造,还在于应变量分布的概率模型。这是高于应用数学思想的。
5. 当然还可以有别的参数方法。
6. 非参模型的一些例子前面的回答已经提过不少,如kernel,决策树,boosting,bootstrap等等等等。
2. 总体上总是可以分成高维方法和低维方法。高维亦即非参数模型,低维即参数模型。显然,非参数方法集之于参数方法集如同无理数集之于有理数集。
3. 参数方法的一个大块是线性模型,统计中这叫回归,数学中这叫投影。这反映了一个应用数学式的思路:一开始问题总是无穷维的,然后开始用投影进行降维,同时加上矢量空间假设,而所有非线性的部分全部扔到坐标轴内部。
4. 参数方法的另一个大块是分布模型,基于似然函数的方法(极大似然)和贝叶斯(先验x似然=后验)。分布模型本质也是降维,把问题降到低维度的参数空间里,并且允许样本误差的存在。事实上线性模型在统计观点下也是一个分布模型,应变量的分布。这样一来回归的多变性不仅在于投影基矢量的构造,还在于应变量分布的概率模型。这是高于应用数学思想的。
5. 当然还可以有别的参数方法。
6. 非参模型的一些例子前面的回答已经提过不少,如kernel,决策树,boosting,bootstrap等等等等。















 2795
2795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









