









一、语法工具
dir(packname) #输出包/函数中的内容
help(functionname) #输出函数使用方法在IDE中按下ctr键和help方法作用相同
二、载入数据
Dataset:提供数据获取方法,以及标签
Dataloader:为后续网络提供不同的数据形式
from troch.utils.data import Dataset #导入dataset类Dataset为一个模板类,所有实体类必须继承其且重写getitem方法(用于获取数据),也可重写len方法(获取dataset大小)
from PIL import Image #获取图片方法(也可使用opencv)
import os #使用系统方法
class MyData(Dataset): #继承dataset
def __init__(self,root_dir,label_dir):抓取路径列表
self.root_dir=root_dir #将其全局化
self.label_dir=label_dir
self.path = os.path.join(self.root_dir,self.label_dir) #用系统组件获取路径列表
self.img_path = os.listdir(self.path) #获取图片列表
def __getitem__(self,idx): #自指针,序号
img_name = self.img_path[idx] #将序号转换为图片名
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
#读取图片
label = self.label_dir
return img,label
def __len__(self): #返回列表长度
return len(self.img_path)使用MyData类
root_dir = "..."
ants_label_dir = "..."
ants_dataset = MyData(root_dir,ants_label_dir) #初始化类
#获取第1个变量
img,label = ants_dataset[0]
#img.show() #展示图片
#组合两个数据集
train_dataset = ants_dataset + bees_dataset三、数据/图像的展示和处理
1.TensorBoard
from torch.utils.tensorboard import SummaryWriter使用SummaryWriter
writer = SummaryWriter("logs") #实例化(参数为文件夹路径)
writer.close() #记得关闭①使用add_scalar方法
wirter.add_scalar(tag,value,step) #图表名,y轴,x轴
#此方法为绘制点,如需绘制曲线需要循环使用完成后使用控制台打开数据文件,会以网页的形式打开,同一名称下的数据会生成同一张图标
tensorboard --logdir=logs --port=6007 #文件路径 端口号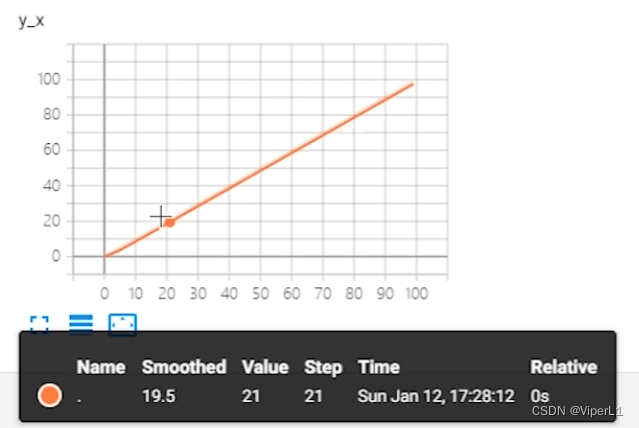
②使用add_image方法
在使用add_image之前需要对获取的图像类型进行转换
from PIL import Image
import numpy as np #载入np用以转换,也可以使用opencv
img_PIL = Image.open(path) #参数为地址
img_arry = np.array(img_PIL)
将数据装载进add_image
wirter.add_iamge("test",img_array,1,dataformats='HWC') #表名,图片容器,步数,格式虽然add_image可以使用numpy类型,但对容器内数据格式有要求,需要格式为:
[通道,高度,宽度],如数据格式有误,则需要使用TensorBoard对数据进行格式指定
img_array.shape #Tips.展示包内数据格式2.Transforms
from torchvision import transform①ToTensor的使用和Tensor型
from PIL import Image --使用图片库
img = Image.open(path) --导入图片
tensor_trans = transforms.ToTensor() --创建对象
tensor_img = tensor_trans(img) --将PIL或numpy转换为tensor型Tensor数据类型包含了神经网络反向传播算法的一些参数
同时也可以使用ToPILImage()将其还原
Tensor型可以直接写入图像
writer = SummaryWriter("logs")
writer.add_imge("标题",tensor_img) --写入图线
wirter.close()②Normalize的使用
作用为归一化,归一化公式为:
input[channel]=(input[channel]-mean[channel]/std[channel])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) --均值,标准差
(包含通道信息,一般为三通道)
img_norm = trans_norm(img_tensor) --输入仅可为tensor型③Resize的使用
trans_resize = transforms.Resize((512,512)) --变换后的大小
img_resize = trans_resize(img) --输入为PIL-img,返回值依旧为PIL-img④Compse的使用
与resize的区别是compose不会改变长宽比
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2 = trans_compose(img)其参数为一个列表,表现为Compose([transforms参数1,transforms参数2])
⑤常见的Transforms
| 输入 | PIL | Image.open() |
| 输出 | tensor | ToTensor() |
| 作用 | narrays | cv.imread() |
from PIL import Image
from torchvision import transforms
img = image.open("path")Tips.__call__的用法
class Person:
def __call__(self,name):
print("__call__"+"hello"+name)
def hello(self,name)
print("hello",name)
person = Person()
person("张三") --不需要使用引用符调用函数
person.hello("李四") --必须使用引用符3.torchvision中的数据集的使用
①DataSet的使用
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,download=Ture)
--根目录,是否训练(测集设为False),是否下载官方数据集(使用自己的数据集时设置为False)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,download=Ture)
print(test_set[0]) --展示数据集中的0号组与Transforms联用
dataset_transform =
torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
--建立transform对象
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,
transforms=dataset_transfroms,download=Ture)
--根目录,是否训练,transforms对象,是否下载
--会将数据集中的每一个PIL-img转换为tensor②DataLoader的使用
test_data = torchvision.datasets.CIFAR10(root="./dataset",train=False,
transforms=dataset_transfroms,download=Ture) --测试数据集
from torch.utils.data import DataLoader
test_loader = DataLoader(dataset = test_data,batch_size=4,
shuffle=True,num_worker=0,drop_last=False)
--dataset->数据源,batch_size->一个包内含的数据个数
--默认的抓取策略为随机抓取
--返回值为imgs,tragets
--获取包内部数据(使用循环)
for data in test_loader:
imgs,targets = data
print(imgs.shape)
print(traget)DataLoader读取的包内部结构如图示(会将x个图片和x个标号分别打包)
| 图片 | 标号 | 来源 |
| img0 | traget0 | dataset[0] |
| img1 | traget1 | dataset[1] |
| img2 | traget2 | dataset[2] |
| img3 | target3 | dataset[3] |
四、nn.Module框架
nn:神经网络(Neural network)骨架。
框架中所有的模组的使用可以归结为以下模式:
首先创建一个类,该类继承自nn.Module,需要包含以初始化函数__init__()和传递函数forward()
def __init__(self):
super(ClassName,self).__init__()
--需要调用的模组的初始化
初始化函数首先要继承基类的初始化函数__init__(),然后再在其中定义所需要的函数模块,如:
self.relu = torch.ReLu()传递函数forward有两个参数self和input,self为自体指针,input用于接收源数据。收到源数据后,可以在函数内用self调用已经被初始化好的工具,处理完成后再将其返回。
def forward(self,input):
output = self.relu(input)
return output完成神经网络结构的构建后,直接在主函数体内调用类即可
mynet = MyNerNet() --实体化
output = mynet(input) --网络处理1.Containers
module
包含两个重要组成部分:__init__()和forward()<前向传播函数,用于网络内计算>
import torch.nn as nn
import torch.nn.functional as F
class MyNerNet(nn.Module):
def __init__(self):
--用于初始化
def forward(self,x):
--x为前向传递函数/神经网络结构使用创建好的神经网络
mynet = MyNerNet()
x = torch.tensor(1,0) --测试数据,应为tensor型
output = mynet(x) --经过神经网络处理后输出数据2.卷积层
常用的卷积操作有Covn1d(一维卷积),Conv2d(二维卷积),其重要参数有
| weight | 卷积核 |
| bias | 偏置 |
| stride | 滑动步距 可以是单个数(纵向横向步距一致) 也可以是数组(分别有sH和sW控制纵横步距) |
| padding | 0填充 |
其中input和weight有格式要求:minibatch,通道数,高度,宽度
需要使用尺寸变换torch.reshape对其格式进行转换
以Function代码实现
import torch
import torch.nn.funtion as F
input torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]]) --输入数据
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]]) --卷积核
input = torch.reshape(input,(1,1,5,5)) --(1batchsize,1通道,5高度,5宽度)
kernel = torch.reshape(kernel,(1,1,3,3))
output = F.Covn2d(input,kernel,stride=1) --使用卷积
print(output)以nn代码实现
函数原型中需要自己设置的参数(in_channels,out_channels,kernel_size)除此之外还有stride=1.padding=0,dilation=1(用于空洞卷积),groups=1(用于分组卷积),bias=True(偏置),padding_model='zeros'(填充模式)有默认参数
与function不同,仅需填入输入通道数/输出通道数(一般图片为3通道)以及卷积核尺寸即可,并不需要转换格式
输入/输出通道数指输入/输出组数,例如令out_channel=2,系统会再生成一个卷积核并产出一个额外的输出
如下列代码所示为初始化数据对象,以及设置一个简单的卷积器
import torch
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from torch.nn import Conv2d
dataset = torchvision.datasets.CIFAR10("../data",train=False,
transform=torchvision.transforms.ToTensor(),download=True) --数据集
dataloader = DataLoader(dataset,batch_size=64) --读取器
class MyNerNet(nn.Module):
def __init__(self):
super(MyNerNet,self).__init__() --继承父类初始化
self.conv1 = Conv2d(in_channels=3,out_channels=6,
kernel_zies=3,stride=3,pandding=0) --初始化卷积器(二维)
def forward(self,x):
x = self.conv1(x)
return x如下列代码所示为简单卷积器的应用
myNet = MyNerNet() --初始化对象
for data in dataloader: --遍历加载器
imgs,targets=data --拆包
output=myNet(imgs) --对图像进行卷积3.最大池化使用
参数包含kernel_size(卷积核尺寸)、stride(步长)、padding(填充)、dilation(空洞卷积)、return_indices(基本不使用)、ceil_mode(默认值为False-Ceiling,取整方式:Floor-向下取整、Ceiling-向上取整)
import torch
input = torch.tensor([[1,2,1,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32) --数据源
需要限定数据类型,最大池化无法处理long型数据
torch.reshape(input,(-1,1,5,5)) --调整格式(N,C,Hin,Win)
mynet = MyNerNet() --创建神经网络对象
output = mynet(input) --进行最大池化class MyNerNet(nn.Module):
def __init__(self)
super(MyNerNet,self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True) --初始化最大池化
def forward(self,input):
output = self.maxpool1(input)
return output最大池化的作用:在保留数据特征的情况下压缩数据体积(将复数个数据压缩为一个数据)
4.非线性激活
import torch
from torch import ReLu
from torch import nn
input = torch.tensor([[1,-0.5],
[-1,3]])
torch.reshape(input,(-1,1,2,2)) --重塑格式
class MyNerNet(nn.Module):
def __init()__(self):
super(MyNerNet,self).__init__()
self.relu = ReLu() --ReLu激活函数
def forward(self,input):
output = self.relu(input) --
inplace=True时,会直接更新原数据,为False时会返回一个新值;默认为False
return output
mynet = MyNerNet()
output = mynet(input) --调用激活函数5.其他常用层
①正则化层
nn.BatchNornom2d,对输入进行正则化,可以提升网络迭代的速度。在使用时仅需设置num_featrues参数(输入数据的格式)即可
②Recurrent层
多用于自然语言处理
③Transformer层
④线性层
nn.Liner,主要包含in_features、out_features和bias。多用于全连接层
dataset = torchvision.datasets.CIFA10("../data",train=False,
transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class MyNerNet(nn.Module):
def __init__(self):
super(MyNerNet,self).__init__()
self.liner=Linear(196608,10) --in_features,out_featrues
def forward(self,input):
output = self.linear(input)
return output⑤Dorpout层
随机丢弃一部分数据(将其置0),概率参数为p,用于防止过拟合
6.Sequential结构
可以将所用到的层放入此容器中,随后统一调用。可以免去在__init__()中进行初始化
self.model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLu(),
nn.Conv2d(20,64,5),
nn.ReLu())直接在__init__()中使用。接下来在forward()中调用
x = self.model(x)五、网络的优化和保存
1.损失函数
损失函数有两个作用:计算目标输出和目标之间的差距;为更新提供依据(反向传播)
使用时需要注意输入/输出参数(N,源数据),N为数据batch_size
inputs = torch.tensor([1,2,3])
tragets = torch.tensor([1,2,5])
inputs = torch.reshape(inputs,(1,1,1,3),dtype=torch.float32)
tragets = torch.reshape(trages,(1,1,1,3),dtype=torch.float32)
loss = L1Loss(reduction="sum") --实例化损失函数
reslut = loss(inputs,tragets) --调用损失函数
损失函数仅接受浮点
L1Loss的参数reduction为计算方式,默认为mean(取平均),可以设置为sum(求和)
L1Loss可以用来计算差值,而MSELoss用于计算方差(reduction设置方式一样)
CorssEntropyLoss用于计算交叉差。
反向传播优化:
for data in dataloader:
imgs,targets = data
outputs = mynet(imgs)
result = loss(outputs,tragets) --计算误差
reslut.backward() --反向传播2.优化器
from torch import optim --优化器类优化器包含的基本参数有:param(传入的模型参数)、lr(学习速率)
优化器的使用步骤:创建优化器;在循环中进行逐步优化(梯度调0;损失函数的前向传递;按步优化)
optim = torch.optim.SGD(mynet.parameters(),lr=0.01) --实例化梯度下降
--传入参数、学习速率
for data in dataloader:
imgs.targets = data
outputs = mynet(imgs) --模型计算
reslut_loss = loss(output,targets) --损失函数计算
optim.zero_grad() --设置梯度为0
reslut_loos.backward() --前向传递
optim.step() --逐步调优3.使用现有网络模型和修改
以torchvision中的分类模型(VGG)为例
vgg16 = torchvision.models.vgg16(pretrained=False) --获取已有的模型
pretrained为true时,会调用已训练完成的参数;而为false时,仅会加载模型①在已知模型模型的基础上添加
vgg16.add_module('add_Linear'.nn.Linear(1000,10)) --名称、需要添加的模型
--通过添加一层线性层,让vgg16的输出由1000变为10
vgg16..classifier.add_module('add_Linear'.nn.Linear(1000,10)) --在指定层级中添加②修改已知模型
vgg16.classifier[6]=nn.linear(4096,10) --修改第6层4.模型的保存和读取
方式对1:
--保存
torch.save(vgg16,"vgg16_method1.pth") --模型,路径 --保存网络模型和参数
--加载(直接加载模型)
mdl=torch.load("vgg16_method.pth")方式对1在使用非官方网络结构时会报错(需要将模型重新定义一遍/引用)
方式对2(官方推荐):
--保存
torch.save(vgg16.state_dict(),"vgg16.pth") --模型.参数,路径
--将网络模型的参数保存为字典形式(空间需求更小)
--加载
vgg16=torchvision.models.vgg16(pretrained=False)
--model = torch.load("vgg16.pth") --会加载一个字典
vgg16.load_state_dict(torch.load("vgg16.pth")) --将字典加载进模型














 1803
1803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









