









 本文介绍了一种新的深度学习模型YoloV9,它利用可编程梯度信息(PGI)来解决特征提取过程中的信息丢失问题。通过设计GELAN网络结构,YoloV9在保持高精度的同时显著减少了参数量和计算量。实验结果显示,相比其他经典算法,YoloV9在性能上有所提升。
本文介绍了一种新的深度学习模型YoloV9,它利用可编程梯度信息(PGI)来解决特征提取过程中的信息丢失问题。通过设计GELAN网络结构,YoloV9在保持高精度的同时显著减少了参数量和计算量。实验结果显示,相比其他经典算法,YoloV9在性能上有所提升。
一、概述
代码路径为:
YoloV9![]() https://github.com/WongKinYiu/yolov9
https://github.com/WongKinYiu/yolov9
YoloV9的作者在论文中指出:现在的深度学习方法大多都在寻找一个合适的目标函数,但实际上输入数据在进行特征提取和空间变换的时候会丢失大量信息。针对这个问题,本文提出了一个可编程梯度信息(PGI),目标是提供完整的输入信息给目标函数,从而获得更可靠的权值来更新网络。

从上面的图片可以看出,传统骨干网络提供给目标函数的数据多多少少都存在丢失的情况。为了解决这个问题,通过辅助的可逆分支生成可靠的梯度,使深度特征仍然可以保持执行目标任务的关键特征。基于上述理论,本文设计了一种基于梯度路径规划的轻量级网络结构:广义高效层聚合网络(GELAN)。
二、模型
1.可编程梯度信息(PGI)
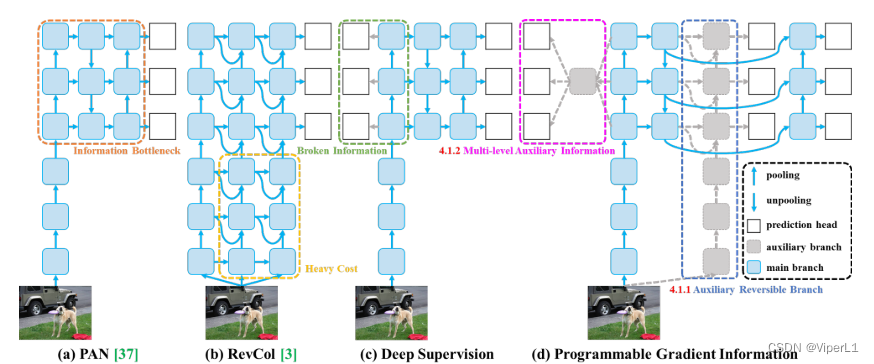
本文提出了一种辅助监督框架,称为可编程梯度信息(PGI),如上图(d)所示。PGI主要由三个部分组成:①主分支(main branch);②辅助可逆分支(auxiliary reversible branch);③多层次辅助信息(multi-level auxiliary information)。由于推理过程中,模型会仅使用主分支,因此并不需要付出额外的推理成本。
另外,上图所示的其他方法为:(a)路径聚合网络(PAN);(b)可逆列(RevCol);(c)常规深度监督(c)。
2.GELAN
GELAN(广义有效聚合网络)通过结合CSPNet和ELAN两种网络的结构,使用梯度路径规划设计。
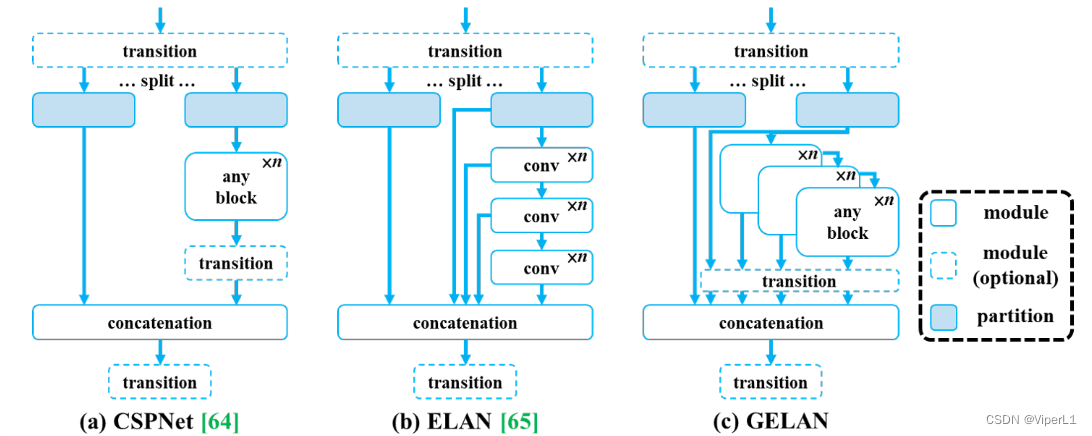
如上图所示,通过模仿CSPNet,将ELAN扩展到GELAN中去。
三、实验
实验基于MS COCO 2017数据集进行,与几种经典算法进行比较。均以M型为例
| 参数量(M) | 浮点计算量(G) | mAP@.50(%) | |
| YoloV5-m | 21.2 | 49.0 | 45.4 |
| YoloV7-m | 36.9 | 104.7 | 51.2 |
| YoloV8-m | 25.9 | 78.9 | 50.2 |
| YoloV9-m | 20.0 | 76.3 | 51.4 |
可见,在精度相当的情况下,YoloV9比较显著的缩小了参数量(-49%)和浮点计算量(-43%),同时,相较于YoloV8拥有更高的精度。
四、模块解析
1.RepNCSPELAN4
class RepNCSPELAN4(nn.Module):
# csp-elan
def __init__(self, c1, c2, c5=1): # c5 = repeat
super().__init__()
c3 = int(c2 / 2)
c4 = int(c3 / 2)
self.c = c3 // 2
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = nn.Sequential(RepNCSP(c3 // 2, c4, c5), Conv(c4, c4, 3, 1))
self.cv3 = nn.Sequential(RepNCSP(c4, c4, c5), Conv(c4, c4, 3, 1))
self.cv4 = Conv(c3 + (2 * c4), c2, 1, 1)
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend((m(y[-1])) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
2.SPPELAN金字塔池化
class SP(nn.Module):
def __init__(self, k=3, s=1):
super(SP, self).__init__()
self.m = nn.MaxPool2d(kernel_size=k, stride=s, padding=k // 2)
def forward(self, x):
return self.m(x)
class SPPELAN(nn.Module):
# spp-elan
def __init__(self, c1, c2, c3): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = c3
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = SP(5)
self.cv3 = SP(5)
self.cv4 = SP(5)
self.cv5 = Conv(4*c3, c2, 1, 1)
def forward(self, x):
y = [self.cv1(x)]
y.extend(m(y[-1]) for m in [self.cv2, self.cv3, self.cv4])
return self.cv5(torch.cat(y, 1))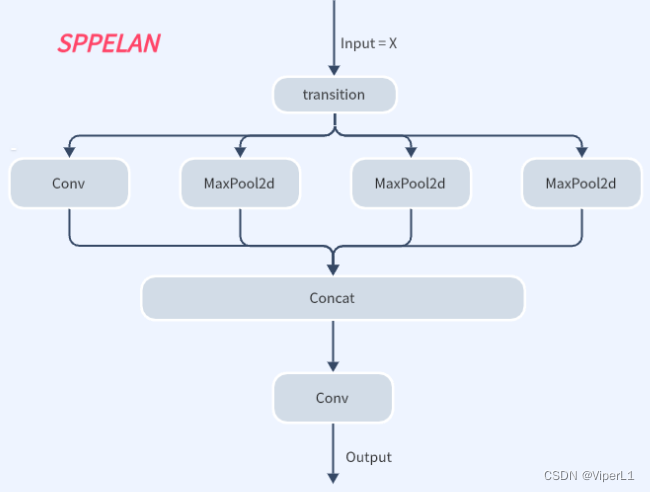















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









